Roger Clarke's Web-Site
© Xamax Consultancy Pty Ltd, 1995-2024

Infrastructure
& Privacy
Matilda
Roger Clarke's Web-Site© Xamax Consultancy Pty Ltd, 1995-2024 |
|
|||||
| HOME | eBusiness |
Information Infrastructure |
Dataveillance & Privacy |
Identity Matters | Other Topics | |
| What's New |
Waltzing Matilda | Advanced Site-Search | ||||
Review Version of 15 February 2010
© Xamax Consultancy Pty Ltd, 2008-10
Available under an AEShareNet ![]() licence or a Creative
Commons
licence or a Creative
Commons  licence.
licence.
This document is at http://www.rogerclarke.com/ID/IdModel-1002.html
An earlier version of this work was presented as:
Clarke R. (2009) 'A
Sufficiently Rich Model of (Id)entity, Authentication and Authorisation' Proc.
IDIS 2009 - The 2nd Multidisciplinary Workshop on Identity in the Information
Society, LSE, London, 5 June 2009, at
http://www.rogerclarke.com/ID/IdModel-090605.html
Supplementary Materials are at http://www.rogerclarke.com/ID/IdModel-Supp-1002.html
During the last 20 years, the practice of identification and identity authentication has been highly unsatisfactory. One important reason for this has been that the theory underpinning the practice has been seriously deficient. A model is presented that is argued to be sufficiently comprehensive and rich to reflect the relevant complexities, and hence to guide organisations in devising architectures and business processes for such activities as user registration, sign-on and identity management.
Organisations are confronted by many risks, and seek ways to understand and manage those risks. The most effective form of risk management is proactive, based on foreknowledge of key information. In particular, organisations want to have confidence in assurances that are given to them by others, and on which their success depends. This paper focusses on one particular cluster of assurances - that the entity or identity the organisation is dealing with is who or what it purports to be. Relevant categories of entity include people, organisations, goods, containers, vehicles, devices of various kinds, and software packages.
It has always been challenging to achieve an appropriate level of confidence in assertions about entities and identities, and to do so without undue cost and effort. For an extended period, the contexts were mostly physical, and involved assurances in relation to such things as physical goods, and the entrance of goods and people into physical locations, and the behaviour of those people once they were on physical premises. Particularly since the widespread application of online computing to business processes from the 1970s onwards, however, digital goods, virtual locations and disembodied behaviour have become much more commonplace. That has given rise to new forms of uncertainty and risk. As a result, during the last 20 years a great deal of attention has been paid to various aspects of identification and authentication, and many schemes have been implemented, particularly in relation to goods, containers, vehicles, devices, animals and people.
A great deal of the investment has delivered unsatisfactory outcomes, most of all in relation to people. Fraud continues to be perpetrated in great volumes, particularly in the context of credit-card payments. Identity fraud has become widespread. Individuals are issued with and required to use large numbers of identifiers and credentials, and they continually forget, lose and compromise them. Digital signatures, which once appeared to be a highly promising invention, have remained little-used, and their effectiveness in most real-world contexts is in serious doubt (Clarke 2001b). 'Identity management' initiatives continue to promise more than they deliver (Clarke 2004c). Despite many initiatives, 'single sign-on' remains wishful thinking, and even 'simplified sign-on' remains uncommon.
The author of this paper has been active in the domain for two decades, variously as researcher and consulltant. I have observed first-hand the widespread, inadequate understanding of the realities of identification and identity authentication, particularly in eBusiness and eGovernment contexts. The inadequate understanding shown by many business analysts, executives, managers and technology providers has reflected naiveté in the models and theories published by academics. Simplistic assumptions continue to be made about entities, about the various identities that entities adopt, about the processes by which confidence in assertions is achieved, and about the authenticators used in those processes.
Based on a combination of consultancy practice and research, I have progressively developed a model which I believe to be sufficiently comprehensive and rich to enable effective analysis of identification and authentication. Further, based on this model, architectures, credentials and business processes can be devised that are appropriate to the wide variety of circumstances that arise in busineess and government. Yet further, I believe that the use of any model less complete than this one is doomed to perpetuate the inadequacies and outright failures experienced in this domain during the last two decades.
The paper provides definitions for a set of concepts and makes clear the inter-relationships among them. Sources, which include references to the underlying literature, are provided in the supplementary materials. The model has been applied to a number of different categories of entity, in order to provide an adequate sample of the considerable richness and diversity of requirements, and to demonstrate that the model is sufficient to enable description and analysis of important real-world problems. The report on that analysis is also provided in the supplementary materials.
The model is presented in graphic form by means of a static representation of the key concepts and their inter-relationships, in Figure 1, together with a depiction of the processes of identity authentication and authorisation, in Figure 2. The definitions provided are instrumentalist in their origins and purpose. They adopt the conventional ontological presumptions: that there is a real world of things (or perhaps a 'domain world' or 'subject world'); and that there is an abstract world of data (or perhaps a 'model world') that is created, stored, transmitted, used and disclosed by means of combinations of manual procedures and automated processes that utilise various kinds of information technology.
A small number of meta-comments are provided in italics. These relate to the origins of the less commonly-used terms, and alternatives to them.
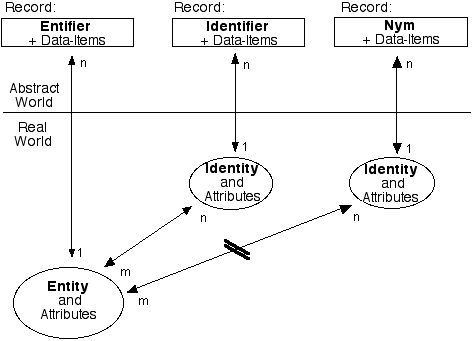
First published in Clarke (2001d)
Entity. An entity is a real-world thing. The notion encompasses pallets piled with cartons, the cartons, and each item that they contain; plus artefacts such as computers and mobile phones; and animals and human beings.
Identity. An identity is also a real-world thing, but is of virtual rather than physical form. Some kinds of entity may present many identities. For example, in computing, the notion of identity may correspond to the multiple processes that are running in a device; and a particular SIM-card currently inserted into a particular mobile phone is one identity (possibly among many) associated with that phone. A person (whether a human, or a legal entity) may also present many identities, to different people and organisations, and in different contexts. Each identity can be thought of as a presentation or role of an underlying entity. Examples important in eCommerce and eGovernment include customer/client, supplier, employee and contractor.
During recent decades, organisations have co-opted the term 'identity' to refer to something that they create and that exists in machine-readable storage. Better terms exist to describe that notion (such as 'digital persona', discussed below). The term 'identity' has widespread usage among normal people to refer to a real-world phenomenon evidenced by human beings, and it is important that observers respect that usage rather than co-opting the term for other purposes.
Where appropriate, the expression 'entity and/or (id)entity' is abbreviated to '(id)entity', in order to enable statements that apply to both to be written once rather than twice. The expressions '(id)entifier' and '(id)entification' are used in similar manner.
Attributes. Both entities and identities have attributes, or characteristics. For example, human entities have physiological characteristics such as hair colour and psychological traits such as expertise; whereas an identity such as a particular eConsumer may have a profile comprising attributes such as demographics, user-interface preferences, and the default credit-card details and default delivery-address to be used for purchases. Attributes, like the things they are associated with, exist in the real world.
Entity-to-Identity Relationship. In Figure 1, entities and identities are shown as having an m:n relationship. Firstly, each entity may have multiple identities (e.g. a person may play multiple roles, and a mobile-phone may contain multiple SIM-cards, at least at different times and in some cases even at the same time). In the diagram, that is represented by the 'n' at the end of the arrow.
In addition, each of the identities may be used by multiple entities, and hence the other end of the arrow is marked with an 'm'. For example, a SIM-card may be shifted from one phone to another. Similarly, email client-software may send messages on behalf of the device's normal user; but if malware is installed such that the device is a 'zombie', then the device may also send messages on behalf of the botnet manager, or the botnet manager's clients. Examples in the human world are legion, e.g. the identity 'associate editor of a particular journal' is adopted by multiple people, both in parallel and in succession.
The ambiguity in the relationship between entities and identities may be intended and well-known. Alternatively, a person (or any other sentient entity) might want to be the only user of a particular identity, or an organisation may want a particular identity to be used only by a specific entity. It is challenging, however, to prevent use of identities by other parties. Such activities are described by such terms as impersonation, masquerade, spoofing, identity fraud and identity theft.
Nymity. The term nymity usefully encompasses both anonymity and pseudonymity. The term anonymity refers to a characteristic of an identity, whereby it cannot be associated with any particular entity, whether from the data itself, or by combining it with other data. The term pseudonymity refers to a similar but materially different characteristic of an identity. In this case, the identity may be able to be associated with a particular entity, but only if legal, organisational and technical constraints are overcome (Clarke 1999b). In Figure 1, nymity is depicted as an obstacle to the arrow that links the entity with the nymous identity.
All of the concepts introduced in the previous sub-section exist in the real world. This sub-section introduces their correlates in the abstract world of information systems.
Records. Each entity and each identity may be represented by a record that contains data. Each record relates to a particular instance of the general category of entity (e.g. computers, organisations or human beings) or of identity (e.g. processes running in a computer, business divisions of an organisation, or roles played by a human being).
Data-Items. The attributes of the real-world entity or identity are represented by the content of data-items stored in the relevant record. A record associated with an entity or identity may also contain data representing transactions conducted between the (id)entity and the organisation, and data generated by the record-keeper. An important example of data generated by the record-keeper is authorisations (also referred to as permissions or privileges). These are addressed in a later sub-section.
(Id)entity-to-Record Relationship. Each (id)entity may give rise to an associated record in each of multiple data collections, but each record is intended to relate to just one (id)entity. Hence the cardinality is shown in Figure 1 as a 1:n relationship, by which is meant that each (id)entity is associated with 'n' (i.e. zero, one or more) records.
Digital Persona. The collection of data stored in a record is designed to be rich enough to provide the record-holder with an adequate image of the represented entity or identity. The term 'digital persona' is usefully descriptive of the phenomenon. It was my own coinage, first presented at the Computers, Freedom & Privacy Conference in San Francisco (Clarke 1993), and published in Clarke (1994a, and 1994b). But it is in any case an intuitive term and has gained some degree of currency.
It is quite common to see the term 'identity' used to refer to what is called here a digital persona; but 'identity' has many meanings, and to avoid ambiguity it is far preferable that some other term be used. Another candidate term is e-persona. The term 'partial' (which originated in the sci-fi genre) is also a contender, because it underlines the inherent incompleteness of a digital persona in comparison with the real-world entity or identity it represents.
Data Silo. As indicated by the cardinality markers in Figure 1, a real-world (id)entity may have multiple records associated with it. Each set of records may be a 'data silo', separate from the others. In particular, records about an individual that are held by different government agencies, by different corporations, and by different divisions of the same agency or corporation, are maintained separately from one another, in many cases as a legal requirement. During recent years, this phenomenon has tended to be regarded as an impediment to quality of service, and even more so to efficiency in business and government. These justifications have been used for the breaking down of data silos through the correlation, matching, consolidation or merger of multiple sets of records. This has undermined a longstanding side-effect of data silos - privacy protection.
Identifier. An identity can be distinguished from others in the same category by means of some sub-set of its attributes. A data-item or items that represent such attributes is called an identifier.
One example of an identifier is the particular name or name-variant that a person commonly uses in a particular context (such as with family, with a particular group of friends, or when working in a customer-facing role such as a telephone help-desk). Names are highly variable and error-prone, and do not represent convenient identifiers for operators of information systems. More effective and efficient business processes can be achieved by means of an organisation-imposed alphanumeric code (Clarke 1994d). Examples include a customer-code or a username (for a human identity); an International Mobile Subscriber Identity or IMSI (in the case of the identity of the SIM-card currently in a particular GSM mobile phone); and a process-id (e.g. for a software agent).
Entifier. An identifier is associated with an identity, and not directly with the underlying entity, e.g. not directly with a person, a mobile-phone, or a computer. In order to distinguish an entity from others of the same category, a separate term is needed to refer to a suitable sub-set of the entity's attributes. An appropriate term is entifier.
The term entifier has been used consistently in my works since Clarke (2001d), but is not yet widely adopted. It has the advantages of being obvious and being otherwise unused. Contemporary approaches to 'identity management systems' suffer important deficiencies (Clarke 2004c) that will not be overcome until the concept is better-appreciated, and a commonly-used name arises for it.
Examples of entifiers that distinguish an artefact from others of the same category include the serial-number of white goods such as a refrigerator, a computer's processor-id (or a suitable proxy such as the identifier of its network interface card / NICId) and the International Mobile Equipment Identity (IMEI) which distinguishes each mobile-phone - as distinct from the IMSI, which distinguishes the subscriber module such as a SIM-card which is currently inserted in it (Clarke 2008b).
In the case of human beings, distinguishing one entity from another can be achieved by means of biometrics. A biometric is a measure of some aspect of the physical person that is unique (or is claimed, or assumed, to be so). A further possible entifier for a human is what is usefully referred to as an 'imposed biometric' such as a brand, an RFID tag fastened to the person, or an implanted RFID chip (Clarke 1994d, 1997, 2001a, 2002a).
Identification. Identification refers to the process whereby data is associated with a particular identity. This is achieved by acquiring an identifier for it, such as a person's name, or a SIM-card's IMSI.
This application of the term is consistent with dictionary definitions, and has been used in this manner in my works since Clarke (1994b). The term has many other, loose usages, however, particularly as a synonym for 'identifier' (discussed above) or for 'token' (discussed below). It is incumbent on analysts and authors of formal works to avoid such ambiguities.
Entification. The association of data with a particular entity depends on the acquisition of an entifier such as a phone's IMEI, a processor-id or a human biometric. This process is usefully described as entification.
This term has been used consistently in my work since Clarke (2001d), but to date neither it nor any equivalent has become mainstream. The emergence of some such term is important, because there are material differences between identification and entification, firstly conceptually, secondly in terms of the data involved, and thirdly in relation to their impacts and implications.
Token. (Id)entification procedures need to be reliable and inexpensive. Achieving that aim can be facilitated by pre-recording an (id)entifier on a token from which it can be conveniently captured. One common form of token is a card, with the data stored in a physical form such as embossing, or on, or in, a recording-medium such as a magnetic stripe or a silicon chip. In the case of a natural human or animal, a token may be unnecessary, because the entifier can be gathered by sampling the entity itself.
Nym. Several categories of identifiers can be distinguished, depending on whether or not they can be associated with entifier of the underlying entity. The term pseudonym refers to a circumstance in which the association between the identifier and the underlying entity is not known, but, in principle at least, could be known, e.g. if access could be gained to data that is normally protected (such as an index linking a client-code to the commonly-used name and date-of-birth of the AIDS-sufferer to whom the record relates). If an identifier cannot be linked to an entity at all, then it is appropriately described as an anonym. The term accordingly does not imply 'identity-less-ness', but rather an identity unlinked to any specific underlying entity. The term nym usefully encompasses both pseudonyms and anonyms.
The term 'pseudonym' is widely used, and has a large number of synonyms (including aka, 'also-known-as', alias, avatar, character, handle, nickname, nick, nom de guerre, nom de plume, manifestation, moniker, persona, personality, profile, pseudonym, pseudo-identifier, sobriquet and stage-name). In contrast, only a small number of authors have used the term 'nym', although it is readily traceable back prior to 1997.
There has been limited use of the term 'anonym' to date, but it is far from unknown and I have used it consistently in my work since Clarke (2002b). It is important to have a term such as 'anonym' available, because it is entirely feasible to conduct persistent communication with an identity whose underlying entity or entities is, and will remain, unknown. A celebrated example is the whistleblower who brought US President Nixon undone. 'Deep Throat' remained an anonym from 1974 until 2005. 'Publius', which was used for contributions to debates about the U.S. Constitution, has remained an anonym since 1787.
Identity Silo. When data silos are destroyed, the correlation, matching, consolidation or merger of separate records is undertaken on the basis of one or more identifiers, such as name and date of birth, or commonly occurring identifying codes. The term 'identity silo' is usefully descriptive of a context in which an identity and its associated identifier(s) are used for a restricted purpose.
The term 'identity silo' is my own coinage, in consistent use since Clarke (2006). It is a natural extension of the established data silo notion, but has not at this stage come into common usage. The term was unfortunately adopted by some other writers at about the same time, as a (misleading) way to refer to Google's endeavours to establish a Google-controlled single sign-on service.
A multi-purpose identifier is expressly intended to enable the conflation of identities. A common example is national registration numbers assigned to residents in many European countries, which are used within some cluster of related functions such as taxation, health insurance and self-funded pensions (known in some countries as superannuation or national insurance).
A general-purpose identifier, such as the national identity number that is imposed on the residents of countries such as Denmark and Malaysia, is intended to enable the merger of all 'partials', deny the right to nymity, and thereby provide the State, or organisations more generally, with much greater power over people (Clarke 1994d, 2006).
Authentication. The term authentication refers to a process that establishes a level of confidence in an assertion.
Authentication Strength. The degree of confidence achieved in the assertion is determined by the quality or strength of the authentication process. This depends on a range of factors including the nature, quality and number of authenticators (discussed below).
The term 'verification' is sometimes used as a synonym for authentication. It is much less appropriate because 'verity' = 'truth' and 'verify' = 'prove to be true', and hence 'verification' implies that a very high level of confidence is necessary, and is attainable. The term 'validation' is also sometimes used, but similarly implies a high level of confidence, whereas 'authentication' encompasses a range of levels.
Assertion. Authentication processes may be applied to many different categories of assertion. The categories include an assertion of fact, an assertion of data quality, an assertion relating to value, an attribute assertion (i.e. that a particular (id)entity has a particular attribute), a location assertion (i.e. that an entity is in a particular location), and an agency assertion (i.e. that an (id)entity has the capacity to represent, or act as an agent for, a principal). In a great many contexts, assertions of these kinds are the relevant ones to authenticate (Clarke 2003a). However, they are not the primary focus of the model or this paper.
Identity Assertion. A particular form of assertion that has been focussed upon by many analysts to the virtual exclusion of all others is an assertion that an identifier is being appropriately used, or that the identity in question is who or what it purports or is inferred to be. Identity assertions are very challenging to authenticate.
Entity Assertion. This is an assertion that an entifier is being appropriately used, or that the entity in question is who or what it purports or is inferred to be. Many analysts have failed to distinguish entity assertion from identity assertion, and have thereby created fundamental flaws in their designs. Human entity authentication is also very challenging.
Authenticator. Authentication is performed by cross-checking the assertion against one or more authenticators, or items of evidence. For example, an assertion of value may be checked by examining the characteristics of the banknote that is being offered, or by comparing a newly-executed written signature with one previously executed by the presenter of the cheque or card, or by checking the validity of a card-identifier (which identifies a card not a person) and a PIN (which tests whether the person presenting the card knows something that they should know and others should not know, generically referred to as a 'shared secret').
Credential. This is a general term for an authenticator that conveys the imprimatur of some authority, such as a registrar. For example, a signed document may attest to an attribute of the person it was provided to, and a token with a chip may carry a digitally-signed statement that a particular person has a particular trade qualification, age or pension-status.
Identity Authentication. This is the process whereby a level of confidence is achieved in an identity assertion. Identity authentication is quite distinct from identification, which was described above as the process whereby data is associated with a particular identity, by acquiring an identifier for it.
It is common for the unqualified term 'authentication' to be used for what is referred to here as 'identity authentication'. This is highly inadvisable, because it leads organisations to overlook the many other relevant assertions that may be as important, or even more important, to authenticate.
The alternative term identity verification (often just 'verification') is much-used in business and government discussions and even in the academic literature. Strong authentication of identity is very challenging and expensive for whoever is doing the authentication, and onerous on, and even demeaning of, the person on whom it is imposed. The term 'identity authentication' avoids the implication of very high accuracy and is hence much to be preferred.
Evidence of Identity (EOI). This term refers to the authenticators used in the context of identity authentication are commonly referred to as evidence of identity (EOI). All other things being equal, two-factor authentication is regarded as being stronger than single-factor authentication, and three-factor as stronger again, in both cases provided that the factors are independent from one another. In the case of human identities, several forms of EOI are used. They include 'what the person knows' (such as a password or PIN) and 'what the person has' (such as documents and tokens).
An alternative term that is in common use is proof of identity (POI). The term is misleading, because, like 'verification', it implies a level of reliability that is generally unattainable. In addition to being unrealistic, the idea is inconsistent with a risk-managed approach to the conduct of business and government.
Entity Authentication. Entity authentication is the process of achieving a level of confidence in an entity assertion. In the case of a cargo container, the process of entification involves collection of the container's serial-number. The process of entity authentication involves the collection of additional data (such as the container-type code, and its length, height and other size characteristics) followed by computation of the check-digit and comparison against data held in records in order to detect any material inconsistencies.
To conduct entity authentication for an active device such as a computer or mobile phone, a test needs to be conducted of the claim that the device is properly distinguished by means of a relevant entifier (such as the processor-id or mobile-phone-id). For example, if an entifier presents at the same time in two local networks or cells, or in a new cell very shortly after being in a cell a considerable distance from the previous cell, it would appear that at least one of the devices is conducting masquerade.
To conduct entity authentication for a human, it is necessary to collect a measure of 'what the person does' (such as the act of providing a written signature, or the micro-actions involved in the keying of a password), 'what the person is' (a biometric), or 'what the person is now' (i.e. an imposed biometric), and then compare the measure against some previously collected and stored measure of the same thing. All such mechanisms involve significant challenges in terms of quality and security.
It is common for security analysts to discuss 'what the person does' and 'what the person is'.as though they were forms of identity authenticator. The model makes clear that this is mistaken. They are forms of entity authenticator. This oft-made error is sognificant and harmful. It was noted above that authentication of human identities is challenging, expensive, onerous and even demeaning. Authentication of human entities is substantially more so. It is undermined by a whole litany of difficulties in achieving adequate measurement and comparison quality. It suffers serious security vulnerabilities. And it is highly personally intrusive and degrading (Clarke 2002a).
(Id)entity Credential. A token was referred to above as a facility that supports the identification process by providing a convenient means for capturing an identifier. In addition, or instead, a token may assist in the authentication process. For example, it may carry a copy of a secret (or, better, a hash of the secret), or a set of one-time passwords, or a digital signing key and the ability to generate a digital signature, or a biometric (or, much less dangerously, a hash of a biometric).
Authorisation. An (id)entity, once it has been (id)entified - i.e. once an (id)entifier has been collected - and after (id)entity authentication has been performed, may be permitted to perform particular acts. The process whereby it is determined what a particular (id)entity is permitted to do is referred to as authorisation.
A permission or privilege is a capability that an (id)entity is permitted to perform. In a physical context, the capability may be access to particular premises, or to particular parts of premises. In a virtual context, an identity is provided with access to system resources, and in particular authorised to run particular software, use particular functions performed by that software, access particular data collections and/or access particular data within those data collections.
Permissions may be associated with entities, or with identities. Association with entities is fraught with difficulties because entity authentication is confronted by many quality problems, it is highly intrusive and involves vulnerabilities. In any case, a person's access to computer applications and databases commonly depends on the identity or role that they are performing. For example, an employee will generally not be authorised to approve his or her workmates' sick leave forms but may be in the event that their usual manager is absent and the person is 'acting up' as his or her workmates' supervisor; and an employee has different authorisations when they are acting as a selection committee member, or as a fire warden.
The relationship between authentication and authorisation is the subject of considerable confusion in the literature and in practice. A process description is therefore valuable. The depiction in Figure 2 is limited to virtual contexts, i.e. the enabling of users to gain access to system resources.
Access Control. A primary purpose of establishing accounts and performing authentication and authorisation activities is the protection of system resources against unauthorised access, use and abuse. From the perspective of the service-provider, the term 'access control' is usefully descriptive of the complete set of processes depicted in Figure 2.
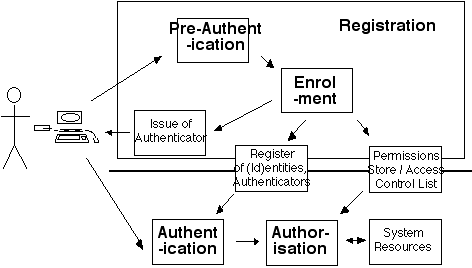
Figure 2 depicts the user operating from a desktop computer. It also serves if the device is instead a portable, handheld or mobile phone. In current and emerging contexts, however, several other variants need to be taken into account. In particular:
The lower part of Figure 2 shows the process flow from Authentication on to Authorisation, which occurs on each occasion that a user seeks access to services. Those concepts have already been introduced. The upper part of the Figure, on the other hand, introduces further concepts. It distinguishes the establishment-phase Registration activities, comprising Pre-Authentication and Enrolment.
User. This term refers to an entity that seeks access to system resources. The scope may be limited to humans, or may extend to organisations and/or devices.
Loginid, Userid or Username. These terms are commonly applied to the identifier that distinguishes a particular user from other users and non-users. The identifier may be weakly or strongly associated with a real-world identity; and the identity may be weakly or strongly associated with one or more real-world entities behind the identity. Alternatively, the identifier may be a nym, because the link back to the entity has not been established.
A loginid is commonly associated with an account (discussed immediately below). If so, and if the identifier is a nym, then it is a Persistent Nym, and can be utilised for as long as the service-provider makes system resources available to it. It may establish a reputation, and hence come to be a more or less trusted identity even if the entity or entities behind it remain unknown.
Account. This term refers to the facilities that a loginid or username provides access to. From the service-provider's perspective, an account comprises one or more linked records containing a set of data-items, which together define and describe a real-world identity recognised by the service-provider and provided with specified services. From the model as a whole, it is clear that a person, an organisation or a device may have multiple accounts with any one organisation, to reflect the various identities that they adopt; and that an account may be used by any entity that can satisfy the authentication tests. The notion of an account is therefore related to that of digital persona, and in particular to that of a partial.
Registration. This usefully refers to the comprehensive process, of the nature of a 'rite of passage', whereby future acts of (id)entity authentication are facilitated.
Pre-Authentication. This is a convenient term to describe that part of the Registration process whereby the assertion is tested that the (id)entity is an appropriate one to have an identifier, identity authenticator(s) and authorisations created for it or assigned to it. Examples of techniques used to achieve relatively strong authentication include the presentation of documents (in some countries referred to as 'the 100-point check'), cross-checking of data supplied by the applicant with entries in databases, call-back to nominated contact-points, and contact with the entity through other channels such as phone-books or previously-recorded email-addresses. Another approach to pre-authentication is reputation-based, with known identities attesting to the appropriateness of the applicant to be provided with an account. A further possibility is evaluation of the applicant's performance or behaviour (e.g. what the user has done in other fora or while using a trial account, or what the user knows).
There are many circumstances in which strong authentication is unnecessary, impractical, too expensive, or unacceptable to the entities involved. For example, the creation of accounts at Passport/Hotmail, Yahoo and Google involves little or no authentication. The identity is just 'an identity', and any reliance that any remote computer, person or organisation places on it depends on subsequent authentication activities. One reason for this is that unauthenticated identities are entirely adequate for a great many purposes, and they are inexpensive and quick for both parties. In addition, nymity is positively beneficial in some circumstances, such as obligation-free advice, online counselling, whistle-blowing and the surreptitious delivery of military intelligence.
A further alternative is to pre-authenticate not the entity, but rather an attribute of the entity. In this case, assurance may be achieved that the account is associated with an (unknown) entity that has a particular characteristic, such as being a registered medical practitioner, or a qualified online counsellor. For this to be achieved, the applicant needs to provide a credential that the service-provider trusts. For example, a medical registration board can provide a digitally-signed message, which omits the applicant's identifier, but is cryptographically assured to refer to the applicant.
An important category of attribute is agency. Pre-authentication of an agent's authority is very important in a range of circumstances, such as the capacity and limitations of an individual to act on behalf of an organisation, e.g. to access data, to provide data, and to bind the organisation in contract. To date, however, authentication processes for agency relationships are extremely poorly developed.
Enrolment. This refers to the second part of the Registration process whereby the means are established for effective and efficient authentication on each subsequent occasion that the user seeks access. It comprises the creation or adoption of an authenticator (or perhaps more than one), possibly the issue of the authenticator to the user, the recording of means of checking the authenticator (which may be a copy of the authenticator, or some more secure alternative such as a 'one-way hashed' copy of the authenticator), and the recording of the capabilities that the user is to be provided with.
Single Sign-On. The number of service-providers has exploded during the last 20 years, and the number of service-providers that any one person may have accounts with is large. This brings with it many practical problems. Some arise from lost and forgotten authenticators, and other from lost and forgotten accounts. Security issues arise, because people record their many authenticators in ways that become accessible to other people, they prefer a small number of easily-remembered passwords to a unique and strong password for each account, and they resist the requirement to frequently change their passwords. The term 'single sign-on' refers to the notion of each user having a single master-account that enables access to all accounts with all service-providers, or all service-providers within some domain. In addition to being challenging to implement, the notion creates substantial additional vulnerabilties. As a consequence of all these difficulties, single sign-on is a theoretical construct rather than a tenable design objective.
Simplified Sign-On. This refers to a less ambitious and less insecure approach than single sign-on, whereby a master-account provides access to a number of accounts rather than to all accounts within a domain.
Identity Management. This is a generic term for architectures, infrastructure and processes that support the authentication of assertions relating to identity. Standards and services has been the subject of a great deal of competitive activity since the late 1990s. Most products and most standard-sets are seriously deficient when evaluated against the model described in this paper (Clarke 2004c, 2008a).
The model presented in this paper has presented a set of related concepts, has carefully distinguished them, has segregated real-world from information-systems concepts, and has described the relationships among them. The definitions are provided in Glossary form in the supplementary materials.
The model is asserted to be sufficiently comprehensive and rich to enable effective representation of real-world phenomena and designs for systems intended to perform (id)entification, authentication and authorisation functions. A series of test-applications presented in the supplementary materials demonstrates that the model is effective in reflecting the realities of multiple categories of entity, which together have a wide array of different attributes and attribute-values, and exist and are used in widely varying contexts. It is therefore contended that the model satisfies the requirements of comprehensiveness and sufficiency. Further, it is asserted that systems designed on the basis of this model will avoid a wide range of deficiencies that have afflicted and continue to afflict practice in this area.
A set of sources, fifteen of them published in refereed venues, which include many references to the underlying literature, is provided in the supplementary materials
The successive versions of this model since the early 1990s have benefited greatly from many interactions with my colleagues at ETC, now Convergence eBusiness Solutions Pty Ltd - particularly David Jonas, Ian Christofis, Ross Oakley and Kevin Jeffery. Valuable feedback was also provided by many clients for whom aspects of the model were presented in workshops and reports, and by participants in the many seminars at which the definitions and related models and analyses have been presented. An advanced version was presented at IDIS 2009 - The 2nd Multidisciplinary Workshop on Identity in the Information Society, at the London School of Economics, 5 June 2009. Comments on advanced drafts by reviewers, David Vaile and Jill Matthews were valuable in clarifying the presentation. Responsibility of course lies with the author alone.
Roger Clarke is Principal of Xamax Consultancy Pty Ltd, Canberra. He is also a Visiting Professor in the Cyberspace Law & Policy Centre at the University of N.S.W., and a Visiting Professor in the Department of Computer Science at the Australian National University.
| Personalia |
Photographs Presentations Videos |
Access Statistics |
 |
The content and infrastructure for these community service pages are provided by Roger Clarke through his consultancy company, Xamax. From the site's beginnings in August 1994 until February 2009, the infrastructure was provided by the Australian National University. During that time, the site accumulated close to 30 million hits. It passed 65 million in early 2021. Sponsored by the Gallery, Bunhybee Grasslands, the extended Clarke Family, Knights of the Spatchcock and their drummer |
Xamax Consultancy Pty Ltd ACN: 002 360 456 78 Sidaway St, Chapman ACT 2611 AUSTRALIA Tel: +61 2 6288 6916 |
Created: 30 March 2008 - Last Amended: 15 February 2010 by Roger Clarke - Site Last Verified: 15 February 2009
This document is at www.rogerclarke.com/ID/IdModel-1002.html
Mail to Webmaster - © Xamax Consultancy Pty Ltd, 1995-2022 - Privacy Policy