Roger Clarke's Web-Site
© Xamax Consultancy Pty Ltd, 1995-2024

Infrastructure
& Privacy
Matilda
Roger Clarke's Web-Site© Xamax Consultancy Pty Ltd, 1995-2024 |
|
|||||
| HOME | eBusiness |
Information Infrastructure |
Dataveillance & Privacy |
Identity Matters | Other Topics | |
| What's New |
Waltzing Matilda | Advanced Site-Search | ||||
Principal, Xamax Consultancy Pty Ltd, Canberra
Visiting Fellow, Department of Computer Science, Australian National University
Original of 13 September 1992, rev. 14 August 1999
© Xamax Consultancy Pty Ltd, 1992, 1993, 1996, 1999
This document is at http://www.rogerclarke.com/ISFundas.html
Very few information systems text-books ever bother to define the term 'data', assuming that its meaning is so obvious that it doesn't need discussion. Many misunderstandings can arise from that failure to consider the meaning of such a basic concept.
'Data' is the plural of 'datum'. A dictionary definition of 'datum' is "any fact assumed to be a matter of direct observation" (The Macquarie Dictionary, 1981, p.473). This approach adopts the conventional assumption that there is a reality outside the human mind, which humans cannot directly capture, but which they can sense and measure. The same dictionary defines 'fact' as "what has really happened or is the case; truth; reality" (p.638). A fact is therefore in the 'real world' and a 'datum' is in the human mind.
For the discipline of information systems, a little more care is needed in the defining such a key term as 'data'. If the dictionary formulation is used, then numbers produced by a random number generator in a computer might be excluded, and we would need another word to describe those kinds of numbers.
The following definition caters for that problem:
'Data' is any symbol, sign or measure which is in a form which can be directly captured by a person or a machine.
We can then use related terms to differentiate between different kinds of data. In particular:
'Real-world data' is data which represents or purports to represent a fact in the real world; whereas 'synthetic data' is data which does not.
Like 'data', the term 'information' is often used in information systems text-books without a clear definition being given. Many authors assume that their readers' conceptions of the notion are sufficiently similar to their own that it can be taken for granted.
Dictionary definitions identify two senses of the word. One is from Shannon and Weaver's theory of communications, in which information is 'a measure of the quantity of data in a message'. This has been extremely important in communications engineering; but it is far too narrow to serve the purposes of the information systems discipline. The other is 'an accretion to knowledge'. But this is very similar to the definition of real-world data, with the minor exception that it implies that the data is new, i.e. not previously in the collection. To provide a basis for information systems theory, we must probe a little deeper than the dictionaries go.
The vast majority of real-world facts never give rise to data. The background noise emanating from all points of the universe has been ignored for millions of years (until the last few decades, during which some astronomers have occasionally sampled a tiny amount of it). Some things about the trucks that carry goods in and out of a company's gates are of great interest to us (such as which trucks, when, what they carried in, and what they carried out). But we don't usually bother even measuring, let alone recording, the pressure in the tyres on the trucks, the number of chip-marks in the paintwork, the condition of the valves on the motor, or the number of consecutive hours the driver has been at the wheel. There are myriad real-world facts that we let go by, and never capture as data.
Of the real-world data which we do capture, many kinds are very uninteresting. The contents of audio-tapes on which astronomers record the background noise emanating from various parts of the sky might on occasions contain a signal from a projectile launched from the earth, and just possibly might contain some pattern from which an inter-stellar event can be inferred, or perhaps the existence of intelligent life somewhere in the universe. But usually the contents are extremely boring, and devoid of any value to anyone. Similarly, a great deal of the data captured by commerce, industry and government is either 'just for the record' or of interest for only a very short time, and then filed in case someone ever wants to look at it again.
What is it that makes data interesting or valuable? The most straightforward way in which data is useful is when it is relevant to a decision. Each morning, we don't usually think about what the weather is like outside until we are deciding what to do with the day (if it's a weekend) or what to wear (if it's a workday). Data about a delivery of a particular batch of baby-food to a particular supermarket is lost in the bowels of the company's database, never to come to light again, unless and until something exceptional happens, such as the bill not being paid, the customer complaining about short delivery, or an extortionist making a telephone call to claim that poison has been added to some of the bottles.
The question as to what data is 'relevant to a decision' is not always clear-cut. The narrowest interpretation that we could make is that data is relevant and of value, only if it actually makes a difference to the decision made. As we shall see in the next section, decision-making processes are often complex, and in many circumstances it is unknowable whether data made a difference or not. So that very narrow criterion, attractive though it may seem, is not a very useful approach.
A broader interpretation is that data is relevant and therefore of value, if, depending on whether or not it is available to the decision-maker, it could make a difference to the decision. This approach can also lead to difficulties. How do we decide whether it might make a difference? What if the data might make a difference, but in law shouldn't (e.g. where a person's ethnic background or marital status is precluded by anti-discrimination legislation from being a factor in employment decisions, but the decision-maker is known to have a bias for or against people from a particular race or country, or people who are divorced)? What if the data might make a difference but logically shouldn't (e.g. because the person making the decision doesn't understand how interest is calculated on a loan)?
In addition to decision-making, there are other circumstances in which data can be interesting or valuable. When we read the newspaper, listen to the news on the radio, or watch 'infotainment' programs on television, we are seldom making decisions, and yet we perceive informational value in some of the data presented to us. Sometimes it is merely humorous. Sometimes it is not what we would have expected, and therefore has 'surprisal' value ("Gosh! The government might survive the election yet!" Or "An injury incurred in training will keep the star fullback out of the Grand Final!").
In other cases, it may be something that fits into a pattern of thought we have been quietly and perhaps only semi-consciously developing for some time, and which seems, for no very clear reason, to be worth filing away (things like the proportion of this year's immigrants who were British, or Kiwis; or the proportion of companies who are requiring skills with web-publishing as a condition of employment).
The most useful and conventional way to use the term 'information' in the information systems discipline is to encapsulate these points:
'Information' is data that has value. Informational value depends upon context. Until it is placed in an appropriate context, data is not information, and once it ceases to be in that context it ceases to be information.
Some people feel very uncomfortable with this definition. It forces us to confront the fluidity of the situation. Rather than a nice, straightforward 'thing', describable in mathematical terms, and analysable using formidable scientific tools, this definition makes information rubbery and intangible, a 'will o' the wisp'.
Finally, we must again acknowledge that the term 'information' is frequently used, even in the information systems discipline, in senses different from the somewhat formal definition proposed above. In particular, 'information' and 'data' are often used interchangeably (which seems like a terrible waste of a useful word).
The most common manner in which data can have value, and thereby become information, is by making a difference to a decision. It is therefore important to consider in some depth what a decision is, and what decision-making processes are about.
A 'decision' is a choice among alternative courses of action.
In many cases, the making of the decision is performed in the same breath as the taking of the action itself. In other circumstances, however, we may make a mental commitment, but take no action until a short time later. Note, too, that 'action' includes 'inaction', i.e. we can decide to do nothing, as in "Shall I take part in the demonstration against the cuts to the tertiary education budget tomorrow? No, I don't think I'll bother".
A 'decision-making process' is the procedures which result in a decision being reached.
How a decision comes about is important to understand. The simplest model of decision-making envisages four steps:
The 'trigger' is something that causes a person to realise a decision is needed, such as the notice you will receive to re-enrol for units next year. In order to make the decision, you will need to gather information about what units are going to be offered, and of course you'll need to know your results for the previous year. The decision-maker needs to generate a set of options, and then to choose among them.
Gaining access to information is crucial to most of these steps. In order to choose, for example, you need to know what your objectives are, in order to work out a criterion whereby you can work out which is the best of the available options.
In practice, this model is too simple. It's a 'normative model', because it describes how scientists think people ought to make decisions. To support organisations making complex decisions, we need 'behavioural models' which describe how managers and executives really make them.
One example of the difference between the two is that most people don't actually search out the 'best' alternative: rather than 'maximising', they 'satisfice'. This odd word was coined, because people have what's called 'bounded rationality'. They don't diligently search a huge decision-space in order to identify every possible strategy. They think of a few possibilities, and ask themselves "Is that good enough?". As soon as they find one that's adequate, they stop searching, and the decision's made. That's 'satisficing'.
In order to understand topics in information systems, it is important to always keep in mind these fundamental notions of data, information and decision-making.
In a related document, knowledge is defined as either:
A further concept which can be confused with information is 'wisdom'. This is, however, on an entirely different plane from information, because it has to do with judgement exercised by applying decision criteria to knowledge combined with new information.
Note that the orthodoxy represented in this document is not universally shared. A nice expression of the philosophical sceptic's position is as follows: "Information, [even today], is no more than it has ever been: discrete little bundles of fact, sometimes useful, sometimes trivial, and never the substance of thought [and knowledge] ... The data processing model of thought ... coarsens subtle distinctions in the anatomy of mind ... Experience ... is more like a stew than a filing system ... Every piece of software has some repertory of basic assumptions, values, limitations embedded within it ... [For example], the vice of the spreadsheet is that its neat, mathematical facade, its rigorous logic, its profusion of numbers, may blind its user to the unexamined ideas and omissions that govern the calculations ... garbage in - gospel out. What we confront in the burgeoning surveillance machinery of our society is not a value-neutral technological process ... It is, rather, the social vision of the Utilitarian philosophers at last fully realized in the computer. It yields a world without shadows, secrets or mysteries, where everything has become a naked quantity" [Roszak 'The Cult of Information' Pantheon 1986, pp.87,95,98,118,120,186-7].
Information Systems is a particular discipline, or branch of learning. It is concerned with the application of information to organisational needs. The scope of IS includes manual, computer-based and other forms of automated procedures, and applications of information technology generally.
'Information Systems' (IS) is the study of information production, flows and use within organisations.
IS makes extensive use of information technology (IT) artefacts. But it is very important to appreciate that its scope encompasses systems in their entirety, including manual activities, the interface between manual and automated components of systems, design aspects of IT artefacts, and economic, legal, organisational, behavioural and social aspects of systems.
Information systems overlaps with both the computer science and business clusters of disciplines; for example, software engineering and database management and some aspects of application software development overlap with computer science, and systems analysis and organisational behaviour overlap with the business-related disciplines.
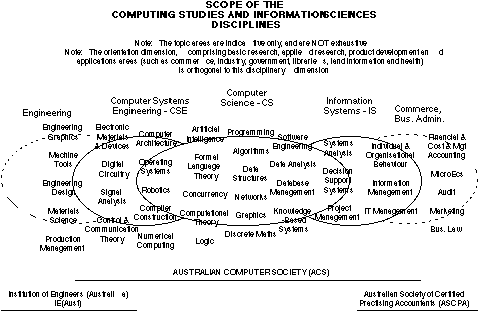
Information systems is derivative from a wide variety of disciplines. These include:
A major applications area is in commercial, administrative and industrial systems, but it is also being applied in association with other disciplines, including applied sciences (such as geography and geology), social sciences (such as econometrics) and humanities (such as art history).
| Personalia |
Photographs Presentations Videos |
Access Statistics |
 |
The content and infrastructure for these community service pages are provided by Roger Clarke through his consultancy company, Xamax. From the site's beginnings in August 1994 until February 2009, the infrastructure was provided by the Australian National University. During that time, the site accumulated close to 30 million hits. It passed 65 million in early 2021. Sponsored by the Gallery, Bunhybee Grasslands, the extended Clarke Family, Knights of the Spatchcock and their drummer |
Xamax Consultancy Pty Ltd ACN: 002 360 456 78 Sidaway St, Chapman ACT 2611 AUSTRALIA Tel: +61 2 6288 6916 |
Created: 17 May 1996 - Last Amended: 14 August 1999 by Roger Clarke - Site Last Verified: 15 February 2009
This document is at www.rogerclarke.com/SOS/ISFundas.html
Mail to Webmaster - © Xamax Consultancy Pty Ltd, 1995-2022 - Privacy Policy