Roger Clarke's Web-Site
© Xamax Consultancy Pty Ltd, 1995-2024

Infrastructure
& Privacy
Matilda
Roger Clarke's Web-Site© Xamax Consultancy Pty Ltd, 1995-2024 |
|
|||||
| HOME | eBusiness |
Information Infrastructure |
Dataveillance & Privacy |
Identity Matters | Other Topics | |
| What's New |
Waltzing Matilda | Advanced Site-Search | ||||
Principal, Xamax Consultancy Pty Ltd, Canberra
Visiting Fellow, Department of Computer Science, Australian National University
Version of September 1993
© Xamax Consultancy Pty Ltd, 1993
This paper was published in The Information Society 10,1 (March 1994). The original version was presented at an Invited Conference on 'Changes in Scholarly Communication Patterns: Australia and the Electronic Library' at the Australian Academy of Science, Canberra, in April 1993
This document is at http://www.rogerclarke.com/II/ResPractice.html
Developments in information technology services during the previous and current decades are argued to have very significant implications for the conduct, and even the nature, of research. These changes should not be thought of as predictable, linear developments, nor even as mere discontinuous functions. They constitute a revolution, challenging established notions of research process.
Conventional economics is not appropriate as a means of understanding these changes, because it is presaged upon resource scarcity, whereas data and processing power are not in short supply. Other difficulties include the heterogeneity of research activity and research tools, and the chameleon character of many information technology services, which are what each user perceives them to be. To cope with the revolution, policy developers and research managers must resort to the blunter instruments of political economy, strategic and competitive theory, innovation diffusion and technology assessment, and be nimble.
The various stakeholders in the research community need a permanent focal point in which to pursue these debates, rather than just occasional, ad hoc fora. In the United States, the national research and education network (NREN) may or may not provide that focus. In addition, a vehicle is needed for discussions of electronic messaging and data access for industry, government and the public. The United States national information infrastructure (NII) initiative may provide a model for other countries.
Conventional economics is based on the assumption that resources are scarce, and concerns itself with the processes whereby they are allocated. This approach has had to be supplemented by bodies of theory and methods of analysis which cope with circumstances in which that key assumption does not apply.
Developments in information technolology have made it possible to replicate many kinds of data for a cost which is trivial in comparison with both the cost of producing the data in the first place, and its potential value-in-use. In addition to transaction data used by businesses, text is now readily captured into a machine, replicated, analysed and processed, and so are sounds including the human voice, and images including moving images.
As society assimilates the information technology developments of the previous and current decades, revolutions are taking place in the conduct of various industries, including the research industry. This paper addresses the question as to whether even so-called 'information economics' is sufficient to enable us to understand and cope with these new capabilities. The paper's focus is on the use of electronic support for research purposes, but there are clear implications for all forms of scholarly endeavour, for education at tertiary and secondary levels, and for industry, government and the general public.
The paper commences by reviewing the technologies which were delivered during the 1980s and those further capabilities which are emerging during the 1990s. It then applies basic economic ideas in an attempt to rationalise the present and future of research communications. It concludes with suggestions as to how the inadequacies of economics can be overcome, and a call for the exploitation of electronic support not only in research but also in other sectors of the economy, and in society generally.
In order to impose a limited degree of order on a dynamic field, this section somewhat arbitrarily distinguishes between the tools and services which came to prominence during the decade of the 1980s, and those which have recently emerged or are presently emerging.
During the 1970s, computing had involved singular resources controlled by a priestly caste. During the 1980s, this evolved to a position in which large numbers of inexpensive standalone microcomputers (commonly but imprecisely called 'personal computers') were much more readily accessible by people who could directly benefit from them, in a much less controlled environment. Where 'dumb' terminals had previously offered to approved users only pre-defined and restricted functionality, these machines provided power for a modest investment to anyone who wished to capture, store, process and publish data.
What has been usually referred to as 'the marriage of computing and telecommunications' enabled hitherto independent micro-computers to talk with one another, and (by emulating dumb terminals) to talk to mainframe equipment. Progressively, users' own microcomputers were linked with centrally controlled macro-processors (mainframes, 'mini-computers' and mid-range machines) to perform cooperative tasks in networks of dispersed machine intelligence. The old hierarchy of a central mainframe with slave terminals was inverted, and the users' workstations became the primary focus, with local, corporate and wide area networks placing 'servers' at the users' disposal.
Accompanying these developments were great improvements in the learnability and usability of applications, of utility software and of software development tools. Scrolling displays and exotic command languages which were inimical to convenient use by non-specialists were replaced by menu-driven and icon-based human-computer interfaces. For the arbitrariness of the old ideas has been substituted consistent machine behaviour, enabling the intuition users develop from their experiences with the first few functions they meet to be generalised to the learning of the remainder. The combination of these various factors has brought about the dispersion and democratisation of computing.
A wide range of tools very important to research were delivered or significantly improved during this phase. The management and analysis of structured, numerical data were better supported, and access to databases was facilitated by the alternative technologies of on-line access to remote databases and directories, and local optical storage (CD-ROM). Within free-text databases, the navigability improved, through the growing availability of so-called 'hypertext', i.e. the ability to roam along the inherent multi-dimensional paths in a document, rather than being limited to the linear sequence of the text. The concept has since been generalised to 'hypermedia' for compound documents (i.e. those which contain data in more than one format).
Document preparation was facilitated and researchers became less dependent on document preparation staff, not only in the sense of word processing, but also in regard to the preparation of diagrams and the incorporation of diagrams and images into text. Even more emphatically, the scope for refinement and revision was increased, with outcomes whose quality (at least potentially) was higher in terms of both content and presentation.
The long-standing dependence of academics on professional and relatively expensive design, production-editing and printing services was demolished. Desk-top publishing enables a team of a lone academic and a single moderately skilled support staff-member to produce conference proceedings, journals and monographs of a quality and at a cost directly comparable to, and in many cases superior to, those of the traditional publishing houses, and to do so much more quickly. The functions in which publishers retain significant advantages have been reduced to such areas as marketing, distribution and capital access.
During this period, communications between researchers were greatly enhanced. The telefax was the most explosive single change during the 1980s, but there was a vast increase also in the number of people connected to national networks such as Bitnet (U.S.A.), JANet (U.K.), EARN (Continental Europe) and ACSnet (Australia). The various networks were then linked via what began as a domestic United States initiative, but has since become the world-wide Internet.
What was originally a very basic and at best semi-reliable email service for unformatted text, has been progressively enhanced. Mailing-lists enable multiple copies of messages to be transmitted to many recipients with a single command. Mailing-lists can be stored centrally, rather than copies being maintained on multiple machines. Updates may be undertaken centrally, or the power to insert or delete one's own address may be vested in the individual, using emailed commands and so-called 'list-server' software.
A complement to the mailing list is the bulletin-board or news group, which stores messages in a database, displays data about the date, time, sender and subject, and enables individuals to read such messages as they choose. Because of the explosion of mail and news-groups, posting to some of the more influential mailing-lists and news-groups is not freely accessible, but is moderated by some kind soul who dedicates much time to encouraging a sufficient volume of useful traffic, and filtering out the less constructive messages.
Remote login capabilities at servers elsewhere in Australia and overseas enable access by pre-authorised users to specialised processing capabilities and databases. In addition, limited access is provided to all comers, to such openly accessible data as the catalogue systems of hundreds of university libraries, and the vast volume of material stored in areas which are labelled (less than clearly) 'anonymous ftp'. This is a form of publication which is at once very cheap and very open-ended, because anyone can use any form of computer-based aid to locate it, and copy from it.
By the beginning of the 1990s, the tools and services outlined in this section had been comprehensively prototyped by computer scientists and other devotees. The developments were by no means confined to the United States; for example, reflecting their deep-seated fear of isolation from the world mainstream and strong desire to overcome 'the tyranny of distance', Australians generate a significant volume of traffic over the Internet. For reviews of contemporary Internet services, see Kehoe (1992), Krol (1992) and LaQuey (1992).
No longer was information technology just about computing qua computation; it was about communication as well: "[an organisation] is constituted as a network of recurrent conversations ... computers are a tool for conducting the network of conversations" (Winograd and Flores 1985, pp.168, 172). The 1980s had seen the establishment of the basis for more widespread use of these tools, the development of more sophisticated services, and the customising of tools and services to the needs of particular disciplines, workgroups and individuals.
With many of the important breakthroughs in hardware and communications already achieved, developments in the early 1990's have been primarily in the software area. The implicit assumption of previous decades had been that individual users worked in isolation, or they cooperated with others but only by sharing the same database. A recurrent theme in the 1990s is the support of collaborative work between individuals, among members of localised workgroups, among widely dispersed workgroups, throughout organisations and even across organisational boundaries.
On-line access capabilities are now moving beyond library catalogues to full-text and image storage and retrieval. The data is increasingly available at the researcher's own workstation, rather than only on a specialised terminal in a library. Statistical databases and collections such as satellite images of weather and landforms are also becoming more widely available over the Internet. Meanwhile significant progress is being made in assisting researchers to locate material they need; in particular, Archie and Veronica provide centralised and frequently updated lists of files around the Internet; the Wide Area Information Service (WAIS) provides convenient but powerful search facilities, and a prototype distributed hypertext search product called World Wide Web (WWW) is also available.
Access to specialised computational capabilities on remote machines is also being facilitated through such initiatives as the U.S. supercomputer network, NFSnet. The emergent National Research and Education Network (NREN) in the United States and the Research Data Network (RDN) in Australia are preparing the ground for high-bandwidth telecommunications superhighways, and linkages across the oceans.
Weaknesses in worldwide email facilities are being quickly overcome. One of the greatest difficulties - finding the addresses of people you wish to communicate with, will be addressed during the next few years through what are commonly referred to as 'directories', both of the so-called white-pages variety (keyed by individuals' and institutions' names) and yellow-pages (organised by class of service offered or research undertaken).
Beyond text-only mail is the ability to transmit formatted (so-called 'binary') documents. Provided that sender and recipient(s) have the same or compatible software, data can be sent in any format whatsoever (e.g. those of particular word processing, diagram-drawing, image-processing, desktop-publishing, or spreadsheet packages), and compound documents containing multiple media-forms can be supported. The products to produce and read these documents are increasingly including capabilities to attach annotations to any location within them, and thereby facilitate fast turnaround among co-authors, and among authors, referees and editors. Many discussions of these capabilities appear in the literature under the term 'computer-supported cooperative work (CSCW)', e.g. Grief (1988). Many documents will continue to be under the editorial control of one person, but conventional notions of document authorship and editorship are being complemented by alternative forms, some democratic and some intentionally anarchic.
Another emerging capability is workflow, which can be conceived as the creation of an intelligent virtual mailroom and file-register, such that documents route themselves between individuals' work-trays. Although this notion's primary applicability is in transaction-processing environments in business and government, it could be usefully applied to aspects of research work, including the receipt, editing analysis of data, and the management of conference papers and journal articles.
Researchers in group decision support systems (GDSS) distinguish a 2x2 (place and time) matrix of multi-person discourse, negotiation and decision processes. The participants may meet in the same place or remain dispersed, and the interactions may occur in the same time-frame (synchronously) or at different times (asynchronously). Each of the four combinations requires different forms of electronic support. Many of the emerging tools are of potential benefit in research as well as in business and government; for example much faster development of ideas can be facilitated by electronic conferences (different-time / different-place communications, but enabling sharing of text, tables, graphics and voice data), and video-conferences (same-time / different-place communications, enabling real-time sharing of the various kinds of data, plus synchronised moving image and sound).
Another potential application is to enable doctoral supervisors who are remote from one another in time and/or space to 'meet' from time to time as an interactive panel, rather than restricting their operations to multiple one-to-one interactions with the candidate. With the trend from entirely State-funded to dual-funded research programmes, the importance of interaction between programme sponsors, directors and staff is greater than ever before, and GDSS tools have much to offer in this area also. A more exciting contribution is the facilitation of brain-storming by, for example, electronically-supported anonymous delphi techniques.
A related development is 'visualisation'. Initially, this is enabling solo and co-located researchers to impose alternative models on data through iterative attempts to explain and replicate patterns. With the increasing availability of high-bandwidth networking, it will support same-time/different-place experimentation in what amounts to a high-tech/high-science 'jam session'.
A further emergent notion with potential research applications is the 'digital persona'. This is a person's data shadow, or image, as projected out into the net; for example, each individual may use multiple identities to reflect different aspects of their 'real' personality, such as the responsible researcher, the social advocate, the sceptic and the 'angry young man'. Ideas and reactions which would be inappropriate in one role may therefore be given free rein via one of the other personae. This is therefore a means whereby members of a community can gain access to all of the varied and often mutually inconsistent thoughts of outstanding individuals.
There are many other applications of the notion, however. In its more active sense, a digital persona is similar to the idea of an 'agent' conceived by computer scientists to perform functions on a person's behalf on a local workstation, a local server, or elsewhere in the net. One simple application is a mail-filter which vets a person's incoming mail, classifies and prioritises it, and perhaps discards low-interest messages, or places them in a 'read-only-if-something's-missing' pile (Loch & Terry 1992). A more interesting class of active persona or agent is the so-called 'knowbot'. Because no central directory exists for the Internet as a whole, it is necessary to search multiple directories when trying to find a particular user or a particular data-file. Prototype programs are in use which adopt modestly efficient search patterns in order to find desired data from anywhere in the net. A further development is the notion of a news-gatherer, which wanders the net, browsing through accessible files, and sending back references to or copies of items which appear to satisfy search criteria nominated by the 'real' person. A more sophisticated persona could 'learn' criteria through feedback gathered about the usefulness of earlier despatches from the individual, and perhaps also from his work-group or a wider reference group.
The richness of emergent ideas is so great that individual researchers, and even whole research teams, are unlikely to apply more than a few of them. Selection and use of those most appropriate to the needs of particular individuals, teams and disciplines will be facilitated by 'researcher workbenches'. These incorporate a user interface supporting access to the various services; tutorial, on-line help and reference material; significant customisability for particular disciplines, research areas and personal preferences; and extensibility to additional and new applications. The most important feature which a workbench offers is, however, integration, both between functions and among local and remote team-members. Prototype workbenches have been reported in the legal area (Greenleaf et al 1992), and exist on the Internet (e.g. gopher). Although there are signs that mature products will soon begin to be offered commercially, the new ideas will continue to emerge from collaborative efforts among researchers themselves.
Sophisticated computing and communications infrastructure is in place to support the research endeavour. Many and varied services are available and will come to be delivered. These services are highly open-ended, and their users will apply them to different purposes, and perceive them differently. This section identifies a few of the implications of the revolution in electronic research support.
Electronically published 'papers' have been appearing on resumés for some years now, particularly in the computer science and information systems disciplines. An increasing emphasis on electronic publication and local printing of hard copy on-demand can already be detected. Never-finished articles have hitherto been a liability rather than as asset, because the ideas contained in them had neither been contributed into the common pool, nor subjected to assessment by peers. A new environment has arisen, in which some kinds of articles can be living reference works, in a state of permanent revision. Collaboration is thereby facilitated, among researchers, between researchers and sponsors, and between researchers and publishers. It is also feasible for improve the peer review process, because reviewers can enjoy a convenient working environment, and spend less time providing more prompt feedback, in a form which is more convenient for the author, editor and co-reviewers.
A further effect of information technology is the democratisation of research: as network connectivity increases, it will not be just researchers in recognised research institutions which will have access to data, communications and processing capacity. Private individuals with an interest in the area will seek to extract ideas from researchers, and to inject their views into the process. It is possible to conceive of circumstances in which researchers will welcome this; for example in the early stages of a new and urgent challenge such as the sudden emergence of the next exotic and fatal virus. It is to be expected, however, that most researchers most of the time will seek to protect themselves from interested amateurs.
Less benign and more predatory are commercial interests, particularly those which are not contributing to research, who use the net to monitor developments in areas in which they perceive an opportunity for profit. It appears likely that, in just the same way that the security of research servers has had to be enhanced in the wake of virus and hacker attacks, research groups will establish closed groups in the open net, and filter the data that they allow out into the public domain, and the communications that they allow in. There is also the prospect of individual research workers, project-teams, institutions, regions or countries seeking to isolate their work from other researchers. For a discussion of the international implications of communications technologies, see Clarke et al (1991).
In the physical, chemical and biological sciences, it is increasingly attractive to replace costly and general messy laboratory work by digital simulation: 'virtual reality' is not merely a creation of the entertainment industry. An unavoidable effect is the creation of an 'ideal world', in which experiments nearly always work, and theory presents itself as gospel. Such anomalies as do present themselves can be explained away as programming errors, as failures in the mapping of the theory into silicon. The leaders in any discipline will not be fooled by the apparent authority of the digital experiment, but for the gullible majority, established theories will be more authoritative than ever before, and the psycho-shock of the occasional paradigm-shift will be that much more dramatic.
There is an unfortunate tendency to use the terms 'data' and 'information' interchangeably. It is more useful to regard data as symbols which represent, or purport to represent, real-world entities and processes. 'Data' is/are intrinsically valueless, but can come to have value in a variety of contexts. The simplest context is that of a decision to which the data is relevant, i.e. where a decision-maker would reach a different conclusion, and therefore take different action, depending on whether that data is or is not available. On this interpretation, 'information' is data which has value arising in a particular context. Hence information can only be judged situationally, and only in the presence of intelligence.
In recent years, there has been some amount of confusion between 'information' and 'knowledge', particularly in the artificial intelligence community. What is recognised by the cognoscenti as hyperbole is often accepted by the less discerning at face value. So-called knowledge engineering techniques are nothing more than clever processing capabilities using data representation methods rather more abstract than those which were conventional a decade or two earlier (e.g. Dreyfus & Dreyfus 1985).
Some commentators judge the prevalent mis-use of the term 'knowledge' not as mere ignorance, but as dangerous arrogance. They infer from computer scientists' statements and behaviour a philosophical stance that not only information and knowledge, but also judgement, wisdom, mind and conscience can be reduced to a common denominator of data. The following is one particularly scathing attack on the mechanistic notion of information technology:
"information, [even today], is no more than it has ever been: discrete little bundles of fact, sometimes useful, sometimes trivial, and never the substance of thought [and knowledge] ... The data processing model of thought ... coarsens subtle distinctions in the anatomy of mind ... Experience ... is more like a stew than a filing system ... Every piece of software has some repertory of basic assumptions, values, limitations embedded within it ... [For example], the vice of the spreadsheet is that its neat, mathematical facade, its rigorous logic, its profusion of numbers, may blind its user to the unexamined ideas and omissions that govern the calculations ... garbage in - gospel out. What we confront in the burgeoning surveillance machinery of our society is not a value-neutral technological process ... It is, rather, the social vision of the Utilitarian philosophers at last fully realized in the computer. It yields a world without shadows, secrets or mysteries, where everything has become a naked quantity" [Roszak 1986, pp.87,95,98,118,120,186-7].
As information technology changes the face of research work, charges such as these must be confronted.
Cumulative change in information technology through the 1980s and 1990s will have both intensive and extensive impacts on research. There will be effects on the choice of research topics, methods and tools, the dissemination of research outcomes, and even the very nature of research itself. In some cases, computing and telecommunications will be used merely to automate existing research practices, but in other cases existing practices will be augmented or rationalised. There are prospects of wholesale (but accidental) 'transformation', and of deliberate 'research process re-engineering'. The following sections present an analysis of the mechanisms of, and rationale for, change.
In order to assess the ways in which innovation in electronic research support is occurring, it is necessary to impose a degree of order on the apparent chaos of tools and services. Exhibit 1 provides an architectural model showing the elements of the network which are needed in order to support the services outlined in the earlier sections. Exhibit 2 provides a classification of those services.
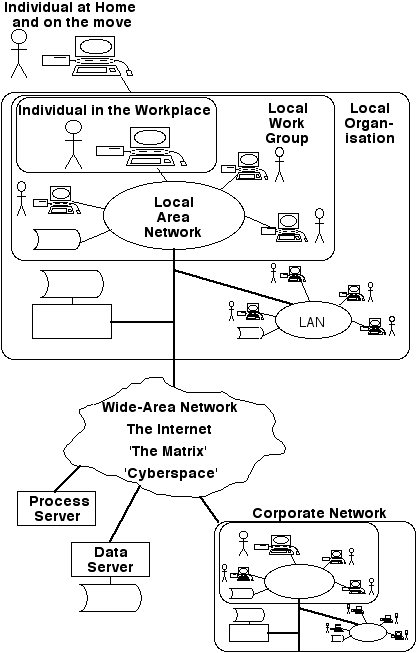
The logical place to start the assessment appears to be economics. In that discipline, it is conventional to commence with a simple case, and to subsequently identify, and then try to remove, simplifying assumptions. The same approach is taken here, by initially considering only the first of the classifications suggested above, data access.
The questions addressed in this section are:
In each case, consideration is given to infrastructure on which the mechanism depends, the cost profile of the delivery mechanism, its service features, and its capacity to generate revenue.
Conventional means for the distribution of data are based on capture into textual, tabular or image form, reproduction on paper sheets or in book form, and distribution of these physical documents by mail. The economics of collecting, processing, storing and maintaining it, require separate consideration from the question of providing access to it. The superiority of computer-based systems for these steps has often been assumed rather than assessed. Key considerations include cheap, automated data editing, ready updateability, and the ease of re-using the data and presenting it in different forms. A well-developed industry exists to support conventional publishing; a rather different infrastructure is needed for electronic publishing. Investment in fixed costs enables some savings in variable costs, and potentially very significant improvements in data quality, flexibility and speed of response to requests for data. To confirm the crisis-point that is already being reached in conventional publishing, it is only necessary to note the escalating costs to university libraries of sustaining subscriptions to even the central serials in each relevant discipline, and the purchase of key new monographs and of a sufficient sample of the remainder (e.g. Cummings et al 1993). The purely economic case in favour of computer-assisted over paper-based publishing may not be straightforward; there are, however, some very significant quality and convenience factors which have been influential in bringing about change.
In order to provide on-line, remote access to data stored centrally, a substantial infrastructure is necessary. Fortunately, much of this infrastructure is very similar to that required for many other capabilities, such as email and remote login, and hence the investment supports several services rather than just one. The fixed costs involved in making each particular database accessible are then relatively modest. Depending on the context they may include the host machine, storage devices, network connection, systems software including database management system, accounting, collection and management capabilities, and management, maintenance and marketing. The variable costs associated with each particular customer and customer-access are very low.
The cost profile for distributing data on physical, machine-readable media (e.g. optical disk) is quite different. There is no reliance on a shared infrastructure, but instead each customer must invest in appropriate hardware, software and perhaps local area networking, in order to provide access to the data. The data manager's costs are somewhat less, in that, of the list in the previous paragraph, network connection and on-line accounting facilities are unnecessary, and much less machine-capacity is needed. On the other hand, either the necessary equipment to manufacture the media must be purchased (increasing the fixed costs), or the manufacture must be undertaken by a specialist supplier under contract (increasing the variable costs). Variable costs are appreciable, and marketing costs are likely to be higher as well, as the database manager is less able to use the network as a promotional vehicle.
The features provided by the two approaches to data reticulation also differ. Centralised data can be maintained in a more up-to-date form, and the current data made available to the on-line customers; whereas data distributed periodically on physical media is inevitably somewhat out-of-date. Where network services are unreliable or highly expensive, however, the locally stored data will be accessible when distant data is not. Where the database provider or third parties provide value-added services, centralised data makes good sense; whereas if the customer wishes to add value locally, the physical distribution mechanism may be preferable.
The manner in which revenue is able to be collected is also different. In the case of on-line access, a periodic subscription is likely to be charged, plus usage fees; and of course there will be additional communications costs. Physical distribution is commonly based on periodic subscription fees only.
Taking all of these factors into account, it is apparent that wide-area access to centrally-stored data is likely to be increasingly attractive to most users. This is because the availability and quality of the networks is likely to continue to improve, the cost is likely to be shared across many different services, and the costs may be regarded as infrastructure investment and hence be apparently gratis to the individual researcher.
There are, however, sufficient differences in the cost profiles, service features and revenue collection opportunities that profitable niches for physical media distribution may persist over the long term; for example, in situations involving non-volatile data, low network reliability (e.g. in troubled places and troubled times), high communications costs or volumes, and/or customers which have very specific views or applications which they wish to superimpose over the data, or other data collections which they wish to manage in an integrated fashion with the purchased data.
The simplistic analysis in the preceding section overlooks a number of important factors. This section provides a tentative discussion of some of the matters which a more careful analysis would need to deal with.
One important weakness is the presumption that revenue will be collectible. This depends on several elements. The first is the existence of a legal framework within which investment will give rise to some form of protected enclave, or monopoly space, within which revenue can be charged at a considerably higher rate than marginal cost. The various forms of intellectual property (patent, copyright, designs, trademarks, and sui generis or specific-purpose constructs such as chip designs) are the normal approach to providing protection to investors in innovation, but other forms exists, including research and development grants, export development grants and other forms of subsidy such as bounties. Difficulties have been noted with applying the concept of ownership to software (e.g. Clarke 1984) and to data (e.g. Wigan 1992).
The second pre-condition for exploiting investment is that the services must be able to be denied to potential customers unless they pay the price. Serious difficulties are being encountered by software suppliers, and by data providers of all kinds, in collecting the monies that should be due to them under intellectual property law. Both data and software are readily replicable. The various strategems to restrict replication to those people who have been issued with a special hardware device (e.g. a master diskette or a 'dongle'), special software, or special data (e.g. a login id and password) have commonly proven insufficiently effectual, or have restricted legitimate use and been unpopular among consumers. Although suppliers, particularly of software, are pursuing high-profile miscreants through the courts in an attempt to lift the level of morality among their customers, there has to be doubt about the medium-term effectiveness of such approaches.
In the new publishing context, the scope for leakage of ideas is greatly increased, and with it the capability to manage intellectual property diminishes to vanishing point. An organisation cannot realistically expect to recover its investment in data by locking it up and denying access. Yet the only point at which control can be exercised is the point of access to the first copy of the data, because as the number of copies increases, the traceability of renegade, second-generation and later copies decreases. The recent trend in data-gathering agencies towards 'user-pays' may prove unenforceable (Wigan 1992). This raises the serious question as to what economic incentives exist, or can be devised, to ensure that raw data continues to be captured and stored, and that acceptable quality levels are sustained.
Alternative approaches to collecting revenue focus less on legal incentives and disincentives, and more on positive, service-related factors. Suppliers can contrive to offer a stream of future improvements which will not be available to a one-time, illegitimate copier, nor even to a one-time purchaser who fails to retain contact with the supplier. Admittedly a dedicated cheat can arrange for repetitive copying of successive versions, but that costs money and effort, and involves a lag. Versions of software products can be released in quick succession, offering new or enhanced features, but with upward compatibility from the previous ones (i.e. with no deleterious effects when converting from one version to another).
In addition, value-added and support services can be bundled into the price and denied to non-subscribers; for example, search capabilities may be made available; training can be offered at significantly discounted prices; libraries of useful examples can be made available; and on-line or telephone support can be provided for loyal, i.e. registered, customers.
Commercial organisations are (by and large) prepared to pay for appropriate levels of quality, reliability, support, progressive enhancement and the right to sue someone for sub-standard products and services. The same cannot be said as confidently for researchers and research institutions. Many research staff, particularly in Universities, have little or nothing in the way of discretionary budgets, and some are opportunistic rather than consistent in their approach to research, and hence less willing to invest in software, data and services. Small numbers of very large institutions tend to employ large numbers of researchers, rather than each research group being a separately incorporated body. Moreover, these large institutions act with some degree of coordination. And there has been a long tradition of teaching-and-research institutions receiving favourable consideration from suppliers of information technology. The result is that buyers of research-related software, data and services have significant power, and use it to ensure that low prices are paid to suppliers, sometimes even below the incremental cost.
There are other difficulties. Conventional economics is applicable to circumstances in which resources are scarce. It is also assumed that the scarce resources are controlled by someone, and difficulties arise where there are qualifications to that notion, as in the distribution of 'public goods' such as air, water and sunshine which are not readily amenable to control. Information economics relaxes the assumption of scarcity of resources, but other traditional assumptions remain. One such assumption is that it is feasible to infer a utility function which sufficiently accurately describes the consumers' preferences in the use of a resource. With any complex technology, that is a dubious proposition, and economists are forced to depend on aggregate profiles, without probing for insights as to how that profile is made up from large numbers of decisions. With sophisticated information technology, even the aggregate profiles are of little use, because the perceptions of the resources differ so much between individuals that any assumption about additivity is unjustifiable, and hence aggregration is meaningless. In effect, there are very large numbers of markets for very many different kinds of psychic resources, rather than a small number of markets for moderately homogeneous resources.
The preceding two sections addressed only data access. It is important to extend the analysis to communications services, because, at least initially, the primary uses of generally available wide area networking have been in person-to-person communications and in personal access to processing services. In addition, considerable growth can be anticipated in person-with-group communications.
Assessment of the costs involved in research communications is made difficult by the manner in which the services have come into existence. Initially, communication paths were established as 'virtual laboratory' research artefacts, or as infrastructure for individual research projects. Subsequently, as the technology became more widely understood, they were built opportunistically, without prior cost/benefit assessments, and frequently element-by-element, rather than within some grand design. It is very likely that even the most important links, processors, software modules and subsidiary networks appear on the asset registers of research institutions, if at all, only as individual components rather than as synergistic wholes.
It is not unusual for inventions to arise in a manner which cannot be identified, let alone costed. It is less common, however, for innovation to occur so informally, i.e. for the invention to be exploited without passing through the 'pre-competitive R&D' and product development phases before reaching widespread usage.
A post hoc rationalisation of the investment might proceed along the following lines. Personal communications by physical post are labour-intensive, expensive and slow. Faster service for urgent matters costs a premium for courier services or telephone calls. An electronic analogue of physical mail (or of telephone calls to a 'voice-mail' 'mail-box') therefore saves an appreciable amount of direct cost, and the variable costs are apparently zero (since the telecommunications, processor and disk-space costs present as stepped fixed-cost functions, i.e. a need for faster lines, a faster processor and more disk-space, arising because of a general increase in activity). It is necessary to make a not insignificant investment in internal and external network connections, processor-time, disk space, and the creation or acquisition and then maintenance of specialised software. But because many of these are already in place (e.g. the internal network connections) and others are needed for other purposes anyway (e.g. the external network connections) or are available gratis (e.g. the specialised software), the actual investment is relatively small, and largely invisible.
The question of the collectibility of revenue was considered above in relation to database access, and found to be problematical. Electronic messaging services cost money when they are provided to government, corporate and private individuals by specialist service-provider companies, or by corporations' own internal cost-centres and profit-centres. Researchers have to date ignored such complications. To most, and perhaps all, employees of research institutions, such services are gratis at the personal, project, Departmental and Faculty or Research Unit level. The costs are generally being absorbed at the highest level of the organisation, through the information technology services unit. This may change over time, and some form of charge-out may be undertaken, as occurs in many institutions with, for example, telephone and even electricity. The variable costs are, however, almost zero, and it will be necessary to allocate the fixed costs across users according to arbitrarily chosen criteria. In the meantime, third party providers appear unlikely to be able to sell electronic messaging services to researchers based on cost-competitiveness, and so will have to offer substantially superior features.
Far more critical than the cost and revenue considerations, however, are the service factors. The physical mail removes the element of spontaneity from inter-personal communications, because each despatch of an idea or information involves simple but seemingly irrelevant labour (finding letterhead, printing, finding the address details, preparing an address-label, enveloping, and a trip to the administrative office) and substantial delays through a logistic chain within and beyond the organisation.
Telephone communications are excellent for short interactions (such as checking possible dates for a meeting), and can be a reasonable means for leaving messages; but they are only effective for serious discussion if both parties are available and prepared. Rather than party-calls, many-to-many conversations are frequently reduced to a succession of two-person calls. The notion of sending a copy of a conversation to third parties seems not to exist. A great deal of valuable research time and focus is wasted because of interruptions by relatively trivial calls. Yet most researchers are at least competent with a keyboard. A typed message can be re-read, revised and re-structured before transmission, unlike a hand-written or spoken message; and it can be sent to multiple people. It can be transmitted and received in asynchronous mode, avoiding insistently ringing bells and unnecessary interruptions to conversation and thought.
Beyond these basic features, the Internet enables the discovery of, and communication with, people who would not otherwise be within the researcher's area of mutual influence. Although it supports far less rich personal and intellectual relationships than is possible with physical contact, the Internet enables many people to create and sustain intellectually profitable relationships in a cost-effective manner, which their research institutes' finance manager does not need to constrain. It enables speedy development of ideas, grant applications, research projects and papers, in ways that are simply not practicable through other messaging mechanisms. For researchers who are remote from one another but have an established relationship, it provides a cost-effective means of maintaining the relationship between visits to one another's sites and conference meetings. Through these new electronic support mechanisms, new ways of working are emerging, and a quantum shift in 'intellectual productivity' is in prospect.
The analysis undertaken in this paper has been tentative. Some inferences may be drawn, although the force with which they are expressed must be limited.
From the viewpoint of corporate information systems theory, the investment by research institutions in networks and networking software is strategic, rather than a mere economic decision. It is driven by competitive necessity, because if the institution does not invest, it will fall behind its peers, and be less able to attract both research grants and top-quality staff. The tools of conventional economic analysis are of limited assistance in understanding and coping with change in the communications patterns within the research community. Analysis of the policy issues confronting individual research institutions and the community of research institutions needs to draw heavily on the insights of political economy, business and competitive strategy (e.g. Porter 1980, 1985), innovation diffusion (e.g. Rogers 1983) and technology assessment (e.g. Berleur & Drumm 1991).
Another implication is that, under the current and likely near-future arrangements, the scope for competitive markets in electronic support for research purposes is limited. Some suppliers may be able to sustain a business in the relatively few niches in which they can demonstrate cost-savings, or the rather greater range of circumstances in which they can offer services which are superior in ways which are important to researchers.
Of course, there remains scope for symbiotic relationships between research institutions and third parties. In particular, conventional publishers may be successful in a rearguard action to slow the onrush of electronic publishing, and to attract research institutions to use their distribution channels to bring their data and reports to market. The difficulties of ensuring that revenue is gained from disk-based and electronic publications seems likely to lead to imaginative schemes to offer timeliness and updatedness of data collections, and value-added and support services.
An important inference from the argument in this paper is that research institutions need to recognise the breadth and the importance of the infrastructure under-pinning electronic research support. In transport systems (such as rail freight and road haulage, and seaport and airport facilities), it is necessary to conceive of some elements as national system infrastructure, serving the needs of the community, and conducted on a collaborative rather than a competitive basis.
It is important that an appropriate business model be adopted for electronic support for research. A rich range exists of alternative ways of organising and financing the undertaking. They vary in terms of who bears the risks, who pays and who benefits; and how much and what kinds of governmental intervention and regulation are involved. At one extreme lies a fully government-funded approach, and at the other an uncontrolled free market. At the heart of the issue is the appropriate balance in the conduct of the research endeavour between competition and collaboration: consideration must be given by the community of research insitutions as to where the boundaries between infrastructure and market forces should be defined. It is suggested that many of the basic services offered over the network should be conceived and financed as infrastructure. There are advantages in submitting other, particularly less mainstream services to the dynamics of competitive markets.
There are many circumstances in which data collection and maintenance are already undertaken on a non-commercial basis; for example many directories of researchers and research are prepared by individuals or research institutions as a convenience for all members of a discipline or applications area. A commercial sponsor (typically a book publisher, software publisher or other IT supplier) generally needs to be found to support the publication and dissemination of such directories, but with electronic services the cost of those steps may also fall sufficiently low that the project can proceed without recourse to an external sponsor.
Many forms of research data cannot be so readily collected and maintained. It is suggested that the community of research institutions must seriously consider defining some forms of research data and processing software as infrastructure, and not part of the commercial realm. One instance of this is data collected under a national research grant, which should arguably by available to the public generally, and the research community in particular. The suggestion is more contentious in the case of data collected under projects which are jointly funded by government, one or more sponsors and/or one or more research institutions: there is a moral argument that the investment should result in some proprietary interest in the data as a means of recovering the costs of entrepreneurial activity. Research institutions may make bilateral, bartering arrangements to provide access to one another's collections; or act multilaterally by forming collectives.
A particularly thorny issue is the question of government data collections. A national policy decision is needed as to whether the national statistical bureau and other data-collecting agencies should charge for data on a user-pays basis, or should be financed from the public purse as part of the national infrastructure.
Over twenty years ago, Drucker asserted that major discontinuities were already upon us, including genuinely new technologies and "knowledge as the central capital, the cost centre and the crucial resource of the economy" (1969, p.9). It is increasingly clear that the notion of discontinuity is inadequate, because it implies that, although the relationship between variables is anything but smooth, the situation can nonetheless be modelled as a set of relationships among the same old variables. Instead the factors which most strongly influence change are themselves changing, and notions such as quantum shift and structural revolution seem more apt.
This paper has focussed on electronic support for research practice. It has briefly reviewed and classified the kinds of services which have emerged and are imminent. It has assessed the cost and revenue factors involved, and concluded that the service factors are much more significant. It has noted that conventional economic analysis is at best only marginally relevant to the readily replicable goods and services involved in this sector. It appears that, during the current revolution, the insights of political economy, business and competitive strategy, innovation diffusion and technology assessment, are likely to be of greater assistance than the precision of economics in understanding the policy issues confronting both individual research institutions and the research community as a whole.
The extent to which the development of electronic support systems for research can be managed, or even guided, may be quite limited. As a science fiction critic expressed it, "the technical revolution reshaping our society is based not in hierarchy but in decentralisation, not in rigidity but in fluidity" (Sterling, 1986, p.xii). This is a central tenet of post-industrial and information society futurism (e.g. Drucker 1969, Bell 1973, Toffler 1980, Masuda 1981, Jones, 1982, Stonier 1983, Cawkwell 1987).
It is reasonable to predict rapid change in research processes during the next decade, far greater than that in any previous decade, and probably more than in the rest of century. Any analysis of that change must recognise complicating factors, such as the re-definition of the competitive bases of the marketplace, and the resources being traded; increasing resemblance between captured data and public goods; the current unpopularity of the notion of infrastructure investment by government; and the need for maturation from the tired old ideas about regulation and intervention. At a national level, the models of MITI and Singapore may be inappropriate elsewhere, but all countries need to encourage appropriate forms of teamwork between the public, private and research sectors.
The research sector is undergoing rapid and highly beneficial change. In addition to the intrinsic importance of this movement, it is leading toward new patterns of communication, which will provide vital improvements in messaging and data access for economic progress and social well-being.
The research community needs a permanent focal point in which to pursue these debates, rather than just ad hoc fora. The planning and management of research networks need to be undertaken by organisations with appropriate remit, funding and representation. The U.S. National Research and Education Network (NREN) may satisfy the need, but if it does not do so, then the research community needs to take up the initiative.
The progress made in the research sector needs to be applied to electronic messaging and data access for industry, government and the public in general. This demands one or more additional bodies, with very wide representation. The debate in the United States surrounding the National Information Infrastructure (NII) may give rise to a suitably structured organisation and process, but if it does not do so, then key players in the academic community should consider initiatives of their own.
Antonelli C. (Ed.) 'The Economics of Information Networks' North-Holland, Amsterdam, 1992
ASTEC 'Research Data in Australia' Proc. Wksp, Occasional paper No. 20, Austral. Sci. & Techno. Council, Canberra, 14 November 1991
Bell D. 'The Coming of Post Industrial Society' Penguin, 1973
Benedikt M. (Ed.) 'Cyberspace: First Steps' MIT Press, Cambridge MA, 1989
Berleur J. & Drumm J. (Eds.) 'Information Technology Assessment' North-Holland, Amsterdam, 1991
Bolter J.D. 'Türing's Man: Western culture in the computer age' Chapel Hill, Uni. of North Carolina Press, 1984
Bolter J.D. 'Writing Space: The computer, hypertext, and the history of writing' Hillside, NJ, Lawrence Erlbaum Associates, 1991
Cawkwell A.E. (Ed.) 'Evolution of an Information Society' Aslib, London , 1987
Clarke R.A. 'Arguments for Software Protection' Austral. Comp. Bull. (May 1984) 24-29
Clarke R.A., J. Griçar, P. de Luca, T. Imai, D. McCubbrey & P.M.C. Swatman 'The International Significance of Electronic Data Interchange' in Palvia S. Palvia P. & Zigli R.M. (Eds.) 'Global Issues in Information Technology' Ideas Group Publ., 1991
Cox D. J. 'The Art of Scientific Visualization' Academic Computing (March 1990) 20-40
Cummings A.M., Witte M.L., Bowen W.G., Lazarus L.O. & Ekman R.H. 'University Libraries and Scholarly Communication' Association of Research Libraries, Washington DC, 1993
Daedalus Journal of the American academy of arts and sciences. Special Issue: A New Era in Computation (Winter, 1992)
Denning P.J. (Ed.) 'Computers Under Attack: Intruders, Worms, and Viruses' Addison-Wesley, New York, 1990
Dreyfus H.L. 'What Computers Can't Do: A Critique of Artificial Reason' New York, Harper & Row 1972, 1979
Dreyfus H.L. & Dreyfus S.E. 'Mind Over Machine', New York, Macmillan/Free Press 1985, 1988
Drucker P.F. 'The Age of Discontinuiy' Penguin, 1969
Forester T. (Ed) 'Computers in the Human Context: Information Technology, Productivity and People' MIT Press, 1989
Greenleaf G.W., Mowbray A. & Tyree A. 'The Datalex Legal Workstation: Integrating Tools for Lawyers' J. L. & Inf. Sc. 3,2 (1992)
Grief I. 'Computer-Supported and Cooperative Work: A Book of Readings' Morgan Kaufman, San Mateo, 1988
Haugeland J. (Ed.) 'Mind Design: Philosophy, Psychology, Artificial Intelligence' MIT Press, Cambridge, MA, 1981
v. Hayek F. 'The Use of Knowledge in Society' Am. Ec. Rev. (Sep 1945)
Helsel S.K. and Roth J.P. 'Virtual Reality: Theory, Practice, and Promise' Westport, CT, Meckler Publishing, 1991
Jones B. 'Sleepers, Wake! Technology and the Future of Work' Oxford Uni. Press, Melbourne, 1982
Kehoe B.P. 'Zen and the Art of the Internet' Prentice-Hall, 1992
Kiesler S., Siegel J., & McGuire T.W. 'Social and psychological aspects of computer-mediated communications' American Psychologist (October 1984)
Krol E. 'The Whole Internet' O'Reilly, Sebastapol CA, 1992
Krueger M. 'Artificial Reality' Reading, MA, Addison-Wesley, 1982
Krueger M. 'Artificial Reality II' Reading, MA, Addison-Wesley, 1983
LaQuey T. 'The Internet Companion: A Beginner's Guide to Global Networking' Addison-Wesley, 1992
Loch S. & Terry D. (Eds.) 'Information Filtering' Special Section of Commun. ACM 35,12 (December 1992) 26-81
Machlup F. & Mansfield U. (Eds.) 'The Study of Information: Interdisciplinary Messages' Wiley, New York, 1983
Marcus A. 'Graphic Design for Electronic Documents and User Interface' Addison-Wesley, 1991
McCormick B., DeFanti T., & Brown M. 'Visualization in Scientific Computing' Computer Graphics 21,6 (November 1987)
Masuda Y. 'The Information Society as Post-Industrial Society' World Future Society, Bethesda, 1981
Porter M.E. 'Competitive Strategy: Techniques for Analyzing Industries and Competitors' Collier Macmillan, London, 1980
Porter M.E. 'Competitive Advantage: Creating and Sustaining Superior Performance' Maxwell Macmillan, London, 1985
Rogers E.M. 'Diffusion of Innovations' The Free Press, New York, 3rd Ed., 1983
Roszak T. 'The Cult of Information' Pantheon 1986
Scientific American Special Issue: 'How to Work, Play, and Thrive in Cyberspace' September 1991
Smith A. 'The Geopolitics of Information' Oxford U.P., New York, 1980
Steele C. & Barry T. 'Libraries and the New Technologies' in Clarke R.A. & Cameron J. (Eds.) 'Managing the Organisational Implications of Information Technology' Elsevier / North Holland, Amsterdam, 1991
Sterling B. (Ed.) 'Mirrorshades: The Cyberpunk Anthology' Ace Books, New York, 1986
Stonier T. 'The Wealth of Information: A Profile of the Post-Industrial Economy' Methuen, London, 1983
Toffler A. 'The Third Wave' Collins, London, 1980
Winograd T. & Flores F. 'Understanding Computers and Cognition' Ablex 1986
Wigan M.R. 'Data Ownership' in Clarke R.A. & Cameron J. (Eds.) 'Managing the Organisational Implications of Information Technology, II' Elsevier / North Holland, Amsterdam, 1992
| Personalia |
Photographs Presentations Videos |
Access Statistics |
 |
The content and infrastructure for these community service pages are provided by Roger Clarke through his consultancy company, Xamax. From the site's beginnings in August 1994 until February 2009, the infrastructure was provided by the Australian National University. During that time, the site accumulated close to 30 million hits. It passed 65 million in early 2021. Sponsored by the Gallery, Bunhybee Grasslands, the extended Clarke Family, Knights of the Spatchcock and their drummer |
Xamax Consultancy Pty Ltd ACN: 002 360 456 78 Sidaway St, Chapman ACT 2611 AUSTRALIA Tel: +61 2 6288 6916 |
Created: 31 October 1998 - Last Amended: 31 October 1998 by Roger Clarke - Site Last Verified: 15 February 2009
This document is at www.rogerclarke.com/II/ResPractice.html
Mail to Webmaster - © Xamax Consultancy Pty Ltd, 1995-2022 - Privacy Policy