Roger Clarke's Web-Site
© Xamax Consultancy Pty Ltd, 1995-2024

Infrastructure
& Privacy
Matilda
Roger Clarke's Web-Site© Xamax Consultancy Pty Ltd, 1995-2024 |
|
|||||
| HOME | eBusiness |
Information Infrastructure |
Dataveillance & Privacy |
Identity Matters | Other Topics | |
| What's New |
Waltzing Matilda | Advanced Site-Search | ||||
Publication Version of 30 December 2012
Journal of Information Technology 28,2 (June 2013) 93-110
© Xamax Consultancy Pty Ltd, 2010-12
Available under an AEShareNet ![]() licence or a Creative
Commons
licence or a Creative
Commons  licence.
licence.
This document is at http://www.rogerclarke.com/II/OzWH.html
This document supersedes the review draft of January 2012, at http://www.rogerclarke.com/II/OzWH-1201.html, and the first draft of April 2010, at http://www.rogerclarke.com/II/OzWH-1004.html
The World Wide Web arrived just as connections to the Internet were broadening from academe to the public generally. The Web was designed to support user-performed publishing and access to documents in both textual and graphical forms. That capability was quickly supplemented by means to discover content. The web-browser was the 'killer app' associated with the explosion of the Internet into the wider world during the mid-1990s.
The technology was developed in 1990 by an Englishman, supported by a Belgian, working in Switzerland, but with the locus soon migrating to Illinois and then to Massachusetts in 1994. Australians were not significant contributors to the original technology, but were among the pioneers in its application. This paper traces the story of the Web in Australia from its beginnings in 1992, up to 1995, identifying key players and what they did, set within the broader context, and reflecting the insights of the theories of innovation and innovation diffusion.
There have been multiple occasions on which adoption of an infrastructural technology has gone hand-in-glove with adoption of a dependent technology or product. In the ICT arena, email proved to be a critical application during 1969-1975,stimulating the adoption of the Internet's predecessor, the US ARPANET, such that in 1973, only a year after the protocol emerged, email accounted for 75% of all ARPANET traffic (Cybertelecom 2011). The VisiCalc spreadsheet stimulated purchases of the Apple II in 1979-80, and Lotus 1-2-3 did the same for the IBM PC in 1983. In a similar manner, the Web-browser played the role of the 'killer app' when the Internet become generally accessible in 1993-95.
The standing of the Web in popular imagination is so high that many people perceive the Web to be the Internet. In fact it is merely one application-layer protocol running over the TCP/IP protocols that mediate between services in the uppermost layer and the telecommunications protocols and infrastructure beneath. The Web has been highly successful in its original intentions in relation to the electronic publishing of documents and the gaining of access to them. It has been extended and compromised by scores of features, both standards-based and proprietary. Many of these have addressed not publishing, but commerce and government, initially to static devices (eCommerce) and more recently to mobile handsets (MCommerce). Meanwhile, the content aspects have been subjected to continual assaults by corporations seeking to 'monetise' and to monopolise the 'information commons' that the Web enabled.
As the Web continues to be formed, deformed and reformed under these stresses, it is important to retain a clear view of its origins and nature. General histories have been written, both by the originators and observers. Existing documents primarily adopt the perspective of technology-providers. This paper, on the other hand, summarises available information about the early years of the the World Wide Web in a single country, and reflects the views of technology-users, adopting the perspectives of individuals and organisations that applied the technology.
The following section considers the appropriate approach to adopt to a presentation of history of this kind, and outlines two bodies of theory that provide the interpretive framework within which the story is told. The paper then reviews relevant services that pre-dated the launch of the Web, and outlines the initial phases of the Web as a whole. This provides the necessary platform for the tracing of developments within Australia, commencing in mid-1992, through the pioneering year of 1993 and the early-adopter year of 1994, and into 1995. Interpretations are made about key factors in the success of the Web as innovation. Speculative comments are offered about the Web's future directions.
The academic discipline of history features the use of primary sources wherever possible, accurate chronology, and careful construction of narrative (Sewell 2005). It pays attention to the questions of where, who, when and what, before it turns to the question of why (Gottschalk 1969). Some history contributions focus on narrative, whereas other works extend beyond telling a story to being reflective, evaluative or comparative (Garraghan 1946).
Specialists in disciplines other than history face considerable challenges when they blunder into historical analysis of their own field, especially if they do so only a relatively short time after the events they are focussing on (Jordanova 2006). On the other hand, a great deal of the primary material in the IT arena is ephemeral, and much is already lost or in the process of being lost; so blunder into historical analysis we must.
The research on which this paper is based is an extension to an ongoing project that has documented the 'Origins and Nature of the Internet in Australia', whose most recent version is at Clarke (2004a). That paper still appears to be the primary historical report on that topic, although it has now been joined by an official court-history of Australia's Academic and Research Network (AARNet - Korporaal 2009).
The delay of 15-20 years between the events and the conduct of the research created difficulties in gathering material. The research commenced with a review of the author's own library and email-archive, which in Internet matters date back to the end of the 1980s. Conventional literature searches and web-searches were conducted. Additional information was gathered from people who were active in the field during the relevant period. Successive drafts were published to relevant electronic communities sporadically between 1997 and 2012. After each round of feedback, references were added, existing text was amended and new material was incorporated.
A participant in the events that are to be chronicled has the advantages of material to hand, a network of sources, understanding of and insights into the process as well as the product, and existing frames of reference within which to hang the factual material. Those factors are counter-balanced by many disadvantages. A mere 20 years' remove is too short for any observer to achieve perspective. Even worse, a participant is afflicted by their involvement, with their judgements influenced by knowledge of some of the individuals and institutions. The participant-researcher also subscribes to assumptions that were conventional at the time but may be questioned by future historians. And much as such researchers might strive for a neutral or universalist perspective, they remain subject to cognitive limitations. Added to that are the constraints of place and time, because factors that were significant in that particular period in the particular geographical area of study may have been materially different from those applying elsewhere.
Two broad areas of theory have been relied upon to provide a framework and language within which the narrative can be developed. The first area of theory is innovation, and the second is the diffusion of innovations.
Invention is the conception of a 'new idea', which may be expressed in textual language, or in a formalised language such as mathematics or precise drawings, or may be embodied in an artefact or process. Innovation is a step beyond invention, and is concerned with the deployment of an idea or cluster of ideas in the real world. This may involve the articulation of an invention, that is to say, its integration into an existing category of artefacts or processes, including adjustments to them so that they can accommodate the new idea.
Innovation involves an intervention into a pre-existing context. Intellectually, an innovation builds on prior ideas, and practically it depends on various elements of existing infrastructure. Successful innovations can often be seen as means of releasing potentials that already existed within the existing infrastructure but were incapable of being exploited without a change of some kind. Innovation may be incremental or revolutionary, depending on the extent to which the pre-existing arefacts and processes remain in place after the change has occurred. Architectural change is more fundamental than component change, resulting in intermediate degrees of disruption between incremental and radical innovation (Henderson & Clark 1990).
The innovation concept is applicable in many contexts, and is the subject of multiple and diverse literatures, particularly in economics, anthropology and management studies. Innovations in IT have been argued to be more dependent on creative actions within user communities than is the case in most other contexts (Tuomi 2002). The unpredictability of the applications of new IT artefacts is summed up by the aphorism `The street finds its own uses for things' (Gibson 1982).
The conventional framework for discussing the process whereby innovations achieve their impact has been set by Rogers (1962) and Rogers & Shoemaker (1971). Diffusion of Innovation (DoI) theory purports to explain how technological innovation is communicated through particular channels, over time, among the members of a social system. It posits a succession of stages through which each adopter is likely to pass:
According to DoI theory, mass media channels are relatively more important at the knowledge stage, whereas interpersonal channels are relatively more important at the persuasion stage.
Characteristics of an innovation that have a substantial impact on its success are:
Cumulative adoption has been observed to follow a logistical or `S'-curve, with slow growth during the pioneering phase - which may last highly varying periods - followed by relatively rapid adoption, later slowing as saturation is approached. The theory proposes rather different patterns of attitude and behaviour among the following, successive adopter categories:
In light of these considerations, the purpose of this paper can be refined. It presents a narrative history of the first two years of the World Wide Web in Australia, working within the constraints of the available information, utilising the precepts of the theories of innovation and innovation diffusion, and adopting the perspectives not of the originators of the technology but of individuals and organisations that applied the technology.
The following two sections provide the necessary background to the narrative, by presenting the context into which the World Wide Web was injected, and the nature of the innovation.
This section outlines the context into which the World Wide Web was launched. The Web depended on the existence of telecommunications networks, protocols to enable the transfer of data over those networks, and software that implemented the protocols. Some of the technologies listed below pre-dated the Web and were known to its developers, whereas others were closely parallel developments.
Long-distance ('tele') communications were originally achieved by 'optical telegraph', using such means as smoke-signals, fire, flags and shutters. During the eighteenth and nineteenth centuries, the emergent understanding of electricity and the development of electro-mechanics and electronics led to the 'electric telegraph'. Services commenced in the mid-1840s, first in the UK (Salford 2011) and very shortly afterwards in the USA, with the first international connection crossing the English Channel in 1851. These used variations in electrical impulses along wires to carry data, initially expressed in Morse code. By encoding an analogue representation of the human voice, telephone (distant sound) services emerged in the 1880s. From the mid-1930s, the telex network (abbreviated from 'teleprinter exchange') used typewriters for input and output rather than morse-key transmitters, and Baudot code rather than Morse. A comprehensive but US-oriented account is in Huurdeman (2003). A comprehensive European alternative has not been located, but see Stumpers (1984) and Standage (1998).
By the 1960s, the public switched telephone network (PSTN) was the most extensive telecommunications network, reaching to most homes and virtually all businesses, large and small (Andrews 2002). It was designed specifically for the transmission of an analogue representation of the human voice. However, many sets of dedicated connections were used to transfer data and transactions. Many of those were what are now called private networks, operated within a single organisation. Some of them were operated by service-providers (often called Value-Added Network suppliers or VANs), which carried traffic for their customers.
From the late 1970s onwards, modems (from modulator-demodulator) emerged, to convert data into the analogue form carried on the PSTN. Individuals and small organisations quickly harnessed dial-up, voice-grade lines to create bulletin-board systems (BBS), commencing as early as 1978 (Peter 2004), and well-supported by FidoNet from the mid-1980s (Wikipedia). During the late 1970s and 1980s, modem-based Videotex services were available using many different standards, such as Ceefax, Prestel and Minitel, typically supporting 1200bps towards the user and 75bps on the back-channel . The only national service that achieved significant penetration was France's Minitel (1978-2012). Its success appears to have been primarily due to what the French called 'messageries roses' and the English-speaking world usually calls 'adult chat'.
After a very long gestation period, fax (tele-facsimile) services were rapidly adopted during the 1970s, to transmit images over the PSTN, primarily images of documents. These initially used acoustic-couplers, and later modems, to map between the pixels that made up the images and the voice-analogue for which the PSTN was designed.
In 1987, modems operated at 2400bps / 0.0024Mbps. It took until 1995 for modem technology to reach 56Kbps - although the achieveable speed was heavily dependent on the quality of the line. Early broadband services (in many countries, primarily ADSL at 256Kbps) became economic for small business and consumers only from the late 1990s.
Until the 1960s, the PSTN and all other networks were 'switched', with each segment along a path from sender to recipient committed to that pair of players for the duration of a session. A new approach emerged, whereby segments of the network did not need to be committed to a single user-pair. In packet-switched networks, messages are interleaved, so that the available capacity can be shared among many users (Davies 2001, Baran 2002). The packet-switched networks that have been implemented since c. 1970 are designed to carry digital data, and have progressively replaced the designed-for-voice PSTN.
An Open Systems Interconnection (OSI) movement arose, whose intention was to ensure reliable communications among devices and networks using packet-switching technologies (Zimmermann 1980). It produced elegant standards, but did so through slow, bureaucratic processes, and delivered networks that operated relatively slowly. Meanwhile, a US academic project funded from Department of Defense sources, the ARPANet, fostered a more pragmatic approach that proved to be sufficiently reliable and much more nimble (Russell 2006). ARPANet operated from 1969, gave rise to the Internet in 1983, and was closed down in 1989.
In 1983, the core protocol of the Internet Protocol Suite, IP, and the primary transport control protocol, TCP, became available. TCP/IP provided a means for existing networks to talk to one another. Within 10-15 years, these protocols came to be used within most networks as well as between them.
The Internet quickly emerged within academe, initially in the USA, but with tentacles reaching out to other countries (Leiner et al. 1997, Hafner & Lyon 1998). By the end of 1992, the scale of the 'network of networks' and the growth in the traffic it was carrying were rapidly becoming unsustainable by the research community alone. The 'Acceptable Use Policy' for the Internet was relaxed in March 1993, allowing much more commercial traffic, and at the same time opening the backbone to a competitive environment. Adoption by individuals, business and government climbed, and geographical reach widened still further. Among many other impacts, use of the telex network collapsed during the late 1990s, because email had quickly become widely accessible.
One application of data networks was the transfer of files, of many kinds. An important means of doing this was the file transfer protocol (FTP), whose origins go back to 1971. Four decades later, FTP continues to be very widely-used.
Some types of files were not intended for the human eye, particularly executable software, but also data that is pre-formatted for processing by software. Many files, however, were intended to be printed or displayed in a form directly usable by people. These initially contained text, tables and images. Progressively, audio, video and animation formats emerged, which were designed to be 'played' to humans' ears and eyes. The verb 'to render' has come to be used to encompass all of 'display', 'print' and 'play'.
As the content being transmitted became more substantial, as files became larger, as users became more impatient, and as copyright-owners became more defensive, a variant of file-transfer was developed, referred to as streaming. A file-transfer, at least as that term is used in the context of the FTP protocol, treats each file as a unit, and stores it on the recipient's device. One of the results of the file-transfer approach is that none of the content can be used until the transfer is complete. Streaming, on the other hand, enables the file's contents to be rendered progressively. This may be useful for text and image, but is particularly appropriate for audio and video, especially when they are live transmissions of current events (Wikipedia).
A further feature of the file-transfer approach is that complete copies of the file proliferate, on every recipient's device. This has the effect of compromising the ability of copyright-owners to exploit their monopoly in order to gain revenue. Streaming offers them the benefit of avoiding the automatic storage of the content on every recipient's device - although, because all of the content reaches every device, however ephemerally, it is feasible for any recipient device to accumulate and store the data. File-transfer long pre-dates the development of the Web. Streaming, on the other hand, emerged from 1993, as the Web was being adopted.
Documents that are intended for the human eye may be transmitted in a fixed format that suits that need, such as proprietary word-processing formats, the international-standard word processing Open Document Format (ODF) or page-image formats such as Portable Document Format (PDF).
There are benefits, however, in distinguishing among a document's structure, its content, and the presentation of that structure and content. A receiving device can run software that interprets the structure and content, and renders the content in manner appropriate to the device and its user. This enables one source-document to be rendered on devices with very different characteristics, such as a desktop with a very large colour screen, a handheld with a small grey-scale screen, or an audio-speaker by means of text-to-voice technology. This approach may also assist in circumstances in which standards change, e.g. for documents that are important for a period longer than any particular document format is current.
The way in which the structure is conveyed is commonly by means of meta-symbols, in much the same way in which editors have passed their detailed instructions to type-setters throughout the 550 years of the Gutenberg era. This activity was referred to as 'marking up' the source-document, and hence the general term used in the area is 'mark-up'.
Early forms of mark-up language for computer-readable documents were Runoff (1965) and troff (Kernighan 1973). While troff was being applied in universities, Generalized Markup Language was developed within IBM (Goldfarb 1981). It appears that the name `GML' may have been derived from the surnames of the originators, Goldfarb, Mosher and Lorie, and the language's name may have been of the nature of a `retronym', designed to fit the acronym. Soon afterwards, Scribe clarified the key feature of separation of content, structure and presentation (Reid 1980). Meanwhile the GML thread gave rise to Standard Generalized Markup Language (SGML - SGML-UG 1990). SGML was highly extensible, and resulted in many specialised sets of tags for marking up documents. See generally Furuta (1992).
File-transfer services were intended to enable the right file to end up on the right device. But it was necessary to know which file to transfer, and from where to where. An important element of extracting value from networks was therefore the discovery of relevant files.
Progress was made initially with the discovery of files that contained text. Indexing of holy books dates to at least the thirteenth century, which saw the preparation of both Grosseteste's topical concordance of the Bible and Hugh of St Cher's word concordance (Wikipedia). Concordances of other religious works appear to post-date 1240, including the Jewish Talmud (JE 1906) and the Koran (Kidwai 2005).
Free-text search software was developed during the 1960s, and was a well-established service in the 1970s. Indexes and search facilities across very large text-databases were provided by ICL's Status product and IBM's internal tool Aquarius and subsequent product STAIRS (STorage And Information Retrieval System - Furth 1972). The software was originally designed to be used within a single site, but the searches could be submitted, and the results received, over networks.
In 1990, Archie was released by Peter Deutsch of MacGill University in Canada. (The name was a contraction of 'Archive'). It was a tool for indexing FTP archives, allowing people to find specific files - "an archipelago of scattered FTP archives is melded into a coherent, distributed information system" (Ciolek 1999). Hence Archie was arguably the first Internet search engine, operational in 1990.
In April 1991, Gopher was released by a team at the University of Minnesota. It provided a free-text search mechanism across multiple collections of textual data, and was specifically designed for use on the Internet. It had a strongly hierarchical style, based on nested menus (Wikipedia). Veronica was a search-engine across multiple gopher servers developed in 1992 at the University of Nevada, Reno. Also in April 1991, WAIS (Wide Area Information Servers) was developed by Brewster Kahle and promoted by Thinking Machines Co. It provided an indexing mechanism and a powerful, structured search tool for text-files stored on networks. In retrospect, some downsides of what appeared at the time to be breakthrough technology were that WAIS required registration in a central catalogue using structured metadata, and did not have a mechanism for automatic discovery of new sites or new files (Wikipedia). A review of these file-discovery mechanisms is in Ciolek (1998). They pre-date by several years the search-engines that later came to dominate Web-usage - Lycos from July 1994, Altavista from December 1995 until about 2000, and Google only from 1998-99.
The text-indexing mechanisms discussed in the preceding paragraphs can be regarded as 'brute force' approaches, seeking to deliver value from a mechanical process. But the parts of a text are not equal in their significance. For example, the occurrence of a word in a document's title, or in the Abstract, may be much more significant than a dozen occurrences within the text as a whole. There is also a considerable difference between the use of a person's name within text, and in the part of the document that identifies the authors.
Grosseteste's topical concordance of the Bible of c. 1240, was a very different tool from Hugh of St Cher's word concordance of c. 1260. The notion 'topic' is a form of 'metadata' - data that describe files. Common examples are title, author, publisher and (as a refinement of Grosseteste's 'topics') author-nominated keywords - which may be free-choice or limited to a controlled vocabulary, and which may or may not be supported by a thesaurus of synonyms. A variety of metadata standards have emerged, beginning in the late eighteenth century in France, and including, significantly, MARC (MAchine-Readable Cataloging) developed by the US Library of Congress in the 1960s. Information professionals need much greater precision than is possible using brute-force free-text search-engines like Lycos, Altavista and Google. They are much better served by discovery tools that take advantage of metadata.
Precedence algorithms, notably Google's, have been so successful in delivering convenient and good-enough search facilities for the masses that metadata-based search of text is little-known. On the other hand, as non-text files have proliferated, metadata has been the primary basis on which the discovery of relevant images, sound and video can be achieved.
The notion of hypermedia originated in 1945 with Vennevar Bush's 'memex' idea for linking information by association (Bush 1948). Both the terms 'hypermedia' and 'hypertext' appear to have been coined by Ted Nelson in 1963, when he was in his mid-twenties (Wikipedia), with the earliest documentation of the terms in Nelson (1965) and Wedeles (1965) respectively. Even Nelson's original, 1965 conception included (using contemporary rather than contemporaneous terminology) granularity rather than linearity of text-segments, links, auto-indexing, versioning, forking, annotation and outlining. Although motivated by the needs of creative writers, the model's scope expressly encompassed documents such as instruction manuals, statute law, PERT networks, family trees and circuit design (Nelson 1965, pp. 93-94). "This paper has proposed a different kind of structure for handling information. Essentially it is a file with certain storage provisions which, combined, permit the file's contents to be arranged any-which-way, and in any number of ways at once. A set of manipulation functions permits making changes or keeping track of developments. The file is capable of maintaining many different arrangements at the same time, many of which may be dormant" (p. 97).
A long-running project called Xanadu commenced in 1967 (Wikipedia, Nelson 1980). The ideas were progressively described in greater detail, with some important additions such as 'transclusion' (inclusion by reference) and micro-payments. Many partial implementations of hypertext and hypermedia ideas were prototyped through the 1970s and 1980s, although few made it into the mainstream. An important exception was Apple's HyperCard, available 1987-2004 (Wikipedia). An outline of the concept appears on p. 92 of Nelson's 1965 paper. Xanadu was overtaken by the Web, and suffered the fate anticipated by an early reviewer: "it may ultimately drown in its own good intentions" (Smoliar 1983).
Looking back at the failure of Xanadu to deliver on its promise, Nelson later said "HTML is precisely what we were trying to PREVENT-- ever-breaking links, links going outward only, quotes you can't follow to their origins, no version management, no rights management" (Nelson, undated, in Pam 1995). The following sections show how, for all its massive inadequacies, the simple pragmatism of the Web, built on a highly-flawed markup language and trivially simple hotlinks, broke through.
The World Wide Web (more succinctly, just 'the Web') emerged between 1989 and 1992, within the intellectual context described in the previous section. It began as a means of making documents readily discoverable and transferrable over networks, and conveniently displayable to the user on their own computing device. (Subsequent developments are outlined in later sections). The Web uses a very simple form of hyperlink, referred to as a hotlink. The organisational setting within which it was developed was a large scientific laboratory.
This section provides a brief overview of the timeline over which the several elements emerged. It is not intended to be comprehensive, but as a means of setting the scene for the emergence of the Web in Australia, which is described in the following section. The description draws on multiple sources, including CERN(1992a), Berners-Lee (1999), W3C (2000), Gillies & Cailliau (2000), together with Deja Vu (2000) and a variety of other such informal sources. See also Reid (1997).
The first sub-section addresses the need for files to be stored on servers, and protocols to be defined, and implemented in software, to enable those files to be downloaded to other devices. The second sub-section considers the format in which the files need to be expressed to enable software in remote devices to render the content into a form conveniently accessible by humans.
In March 1989, an English computer scientist called Tim Berners-Lee was working at the European Organization for Nuclear Research (known as CERN), in Geneva very close to the French border. Building on some work he had undertaken in 1980, Berners-Lee submitted a document to CERN management in March 1989, proposing a hypertext project. In October 1990, Berners-Lee coined the term 'World Wide Web', was joined by Belgian Robert Cailliau, and began writing code on his new NeXT computer (Berners-Lee 1999, p. 28). A further proposal was submitted in November 1990 (Berners-Lee & Cailliau 1990), but again no approval was forthcoming. The intention was to develop a protocol to enable storage, discovery and display of the content in a web of nodes that crossed machine boundaries, focussing initially on textual content but with extensibility to non-text information such as diagrams, pictures, sound, animation etc. A keyword-search option was also proposed.
Despite the absence of formal approval or earmarked funding, a protocol specification, a prototype server and a prototype browser-editor all existed by the end of 1990 (Berners-Lee 1999, p. 30), and in May 1991 a production version of the server was released within CERN. The design enabled access to data in a native format but also in plain text (ASCII). Its native protocol was Hypertext Transfer Protocol (HTTP), but it also supported FTP. The data could be managed by a web-server, or stored in a variety of other kinds of repositories.
In December 1991, the first server outside CERN was installed by particle physicist Paul Kunz at the Stanford Linear Accelerator Center (SLAC). Shortly afterwards, in January 1992, the first promotion outside CERN occurred: "At [a workshop in La Londe, France], Tim Berners-Lee gave the first demo of the Web outside of the CERN laboratory. The attendance of the workshop was about 200 physicists from around the world" (Festa 2001).
By August 1992, "There [were] about 20 Web servers in existence" (WVL 2008,, but attributed to Ciolek 1999). In a document dated 3 November 1992, 26 servers were listed, in 12 countries, several well beyond the physics community (CERN 1992b). During the early years all servers used variants of the original software, which was called httpd.
On 30 April 1993, CERN made the Web software and protocols available on a royalty free basis, and without any other impediments (CERN 1993). It was at that stage still uncommon for potentially significant products to be open-sourced. Berners-Lee and Cailliau gave many public presentations during 1992-93, including one at the first INET in San Francisco in August 1993 (personal communication, Ian Peter, December 2011). The World Wide Web Consortium (W3C) was formed in October 1994, and Berners-Lee moved from CERN to MIT.
In October 1993, there were over 200 registered servers. The growth in server-numbers was very rapid from then onwards, and the number of files and the count of accesses was as well. In February 1995, the open-source Apache server appeared and quickly became the mainstream (Wikipedia). The count of servers grew to 100,000 in January 1996, 650,000 in January 1997 and 4.3 million in March 1999 (Ciolek 1999). A long-running survey of web-servers is at Netcraft (2010). Apache server software still dominates, 15 years later, although a number of commercial products are also available.
Server-side functionality was quickly extended from displaying documents to conducting transactions. All of the additional features necessary to support eCommerce - the HTML forms feature, the HTTP POST method, Common Gateway Interface (CGI) scripting and interfaces to the Electronic Funder Transfer (EFT/POS) system - were in place by the fourth quarter of 1994 (Clarke 2002).
The native format in which files accessible over the Web were intended to be expressed was called Hypertext Markup Language (HTML). This is a greatly simplified version of the well-established and extremely complex Standard Generalized Markup Language (SGML). 'Tags' provide guidance to the browser on how to structure, and to present, the text. From the outset, HTML included the 'hotlink' notion, a very limited form of hyperlink (Cailliau & Assman (1999).
Although it was open-ended, initially the service delivered only text: "[At the end of 1991,] the only graphical browser available was for the NeXT machines, which were not all that popular. I think there were fewer than 100,000 sold. Everybody else had a line-mode browser. And Tim Berners-Lee and Robert Cailliau were too busy promoting the Web to write a graphical browser for Unix" (Festa 2001, quoting Paul Kunz). The NeXT browser was called WorldWideWeb from Christmas 1990 until c. 1993, and later Nexus (Berners-Lee 1995).
In April 1992, Viola was released by Pei Wei at University of California at Berkeley. It was claimed to be the first publicly available web browser with inline graphics, scripting, tables and stylesheet. In October 1992, the Lynx browser was developed by a team at the University of Kansas. This is a text-only browser, which has ongoing value for multiple purposes and was for some years the primary vehicle for the sight-impaired.
From late 1992, through 1993 and into 1994, Marc Andreessen and Eric Bina worked on a generic graphical browser at the National Center for Supercomputing Applications (NCSA) at the University of Illinois in Urbana-Champaign. "Development of Mosaic began in December 1992" (Wikipedia). No mention of the term 'Mosaic' is found in the archive of the WWW-Talk email-list during 1992. However, version 0.5 was released on 23 January 1993 (Andreessen 1993a), and then in successive versions through 1993, including version 1.0 on 21 April 1993 (Andreessen 1993b). There is conflict between this original data and NCSA (1996), which dates versions a variable number of months later. A possible explanation is that the developers and their managers were operating in parallel universes. The earlier dates appear to be the correct ones.
The early versions were for Unix with XWindows, and have been subsequently referred to as XMosaic. Only in September 1993 were Wintel and Mac versions released, finally making the Web conveniently accessible on widely-installed operating systems and without requiring the user to have any significant technical ability.
In March 1994, Andreessen left NCSA, and further developed the browser-software. In mid-1994, Mosaic Communications Corp. was incorporated, and released Mosaic Netscape on 13 October 1994. By December 1994, the company had settled a claim by the University of Illinois and changed the names of the product and the corporation to Netscape. First Mosaic in 1993-94, and then Netscape in 1995-98, were closely associated with a period of explosive growth in use of the Web. When Netscape's dominance was overturned at the end of 1998, it was by another derivative of Mosaic, Microsoft's Internet Explorer (Wikipedia).
Australians have made important contributions to a wide range of computing and networking technologies. Unusually, however, no major contributions in the field of Web technology during the foundation years of 1990-93 have been detected while undertaking this research. On the other hand, a considerable number of Australians and Australian organisations were among the pioneers in the Web's application. The following sub-sections trace the application of the Web in Australia, commencing in mid-1992, focussing primarily on the pioneering web-publishers in 1992-93 and important early adopters during 1994, and supplemented by an outline of the growth in traffic volumes. The sources that have been unearthed provide a substantial amount of information about servers, but less about the content that they made available, and even less about the use and users of web-browser during the period. The paper reflects its sources, and acknowledges the need for complementary research on these other aspects.
Considerable scope for ambiguity exists in relation to such ideas as 'the first web-sites in Australia' and the dates they became available. A site could be launched but only as a place-holder rather than rich in content. Some sites may have been of only local or experimental interest, may or may not have been publicly announced, and may or may not have been registered with the two lists that were authoritative during 1992-94. Even if registered, a site may have been registered some time after launch. Registration was, in any case, unnecessary in mid-1992, while the social network was small; and it quickly became unmanageable during 1994-95, as the server-count exploded. Registration soon became redundant, as first Lycos in July 1994 and then Altavista from December 1995, offered free-text search as a more efficient discovery mechanism.
The registration lists that have been located date to between late 1992 and mid-1994. Relevant excerpts from those lists are in the Appendix. This section presents the information that has come to light during research conducted between 1998 and 2012. By its nature, the narrative cannot be complete. On the other hand, the information that has been unearthed provides a considerable amount of triangulation, enabling a degree of confidence in the facts, dates and claims of priority. The narrative is chronological, comprehensive and careful, and focusses on summarising the available facts rather than on being reflective or evaluative, or on testing theories.
From the early-to-mid 1970s, Australia had many private networks, a significant number of VANs sold services, and the Australian Computer Science discipline operated the ACSnet network to link relevant Departments and other research facilities. Personal contacts were developed and sustained between various Australians and the US developers of first ARPANet and then the Internet. Australia gained a direct connection to the Internet in 1989 (Clarke 2004a). By 1992, there was accordingly a fairly small but well-established and highly capable community of people in academe with the technical capacity both to use and to develop Internet facilities.
It is likely that some of the small community of Australian particle physicists visited CERN during 1992-93, but no information has come to light identifying any individual in that community who was active at that stage even as a user let alone as the operator of a Web-server, and only a single physicist is apparent during the first two years. It remains uncertain whether Viola gained much use in Australia, although Lynx was in evidence in the mid-1990s.
However, it is clear that a few people in Australia knew of developments at CERN and NCSA during 1992. Australia's super-computing community (who were considerably more numerous than particle physicists) had ongoing contacts with NCSA. ANU Bioinformatics professor David Green was sufficiently aware of the initiative that he established a server in mid-1992. In addition, two relevant visits are known to have occurred during 1992. The first, to CERN on 31 August 1992, was specifically for the purpose of meeting with Robert Cailliau, and was by a social scientist working at the ANU, Matthew Ciolek (Ciolek 1998). The second was happenstance, at NCSA in October 1992, when Sydney-based CSIRO astrophysicist Ray Norris saw Web-related developments during a visit there (personal communication, March 2004).
The evidence is clear that the first web-server in Australia was David Green's Bioinformatics site, at life.anu.edu.au. The server-software was installed by Gaby Hoffmann (personal communication, December 2011), and the site-content was established by David Green in mid-1992. It was therefore among the first 20 sites in the world. His claim to have launched the first Australian web-server is "for the simple reason that when I registered it with CERN and with NCSA, no other Australian servers were on their lists" (Green 2001). There were no Australian servers in the list of 3 November 1992 (CERN 1992b), so Green's site would appear to have been registered in late 1992 or early 1993.
Two other pioneers have identified themselves. Computer scientist Rik Harris said that "I set up my first web server in August 1992 when Tim Berners-Lee asked me to do a hypertext version of my Computer Science Technical Reports archive at daneel.rdt.monash.edu.au (which doesn't exist any more). I was discussing the format of search term URLs (can you have two ?'s in a URL?) with Marc Andreessen in February 1993 when xmosaic wasn't able to properly access my databases. I definitely had the Victorian Institute of Forensic Medicine [VIFP] web server then (www.vifp.monash.edu.au)" (personal communication, December 2001). These would appear to have been at worst among the first 30-40 web-servers in the world. At 1 July 1993, VIFP was the second of only two .au entries on the 100-strong list of registered servers (Berners-Lee 1993).
The other pioneer represented a further discipline - astrophysics. Ray Norris advised that, in October 1992, "I visited NCSA and was shown their beta-version Mosaic. I got very excited about it, and on my return home we installed a web server at the [CSIRO] Radiophysics Lab here in Sydney, and became (I think) the second web site in Australia" (personal communication, March 2004). The currently-available evidence suggests that it was actually the third Australian site, but also within the first 30-40 in the world.
The links within the ANU were strong. By the end of 1992, David Green had installed an early version of XMosaic on the workstation of the Deputy of the ANU Library, Tony Barry (a lapsed physicist), who was already a Campus Wide Information Systems (CWIS) evangelist. Within a year, the dominance of gopher within CWIS projects in Australia was under serious threat, and quickly subsided after the release of Mosaic for Windows and Macs in September 1993 (Barry 1995).
Green advised that "by early 1993 ... [his bio-informatics site] was one of the largest [registered on the official lists with CERN and NCSA] with several hundred pages and thousands of hits per day". Tellingly, he also said "At first I didn't do much with it, just experimented because it was text only. It was only when NCSA brought out their hypermedia browser Mosaic late in 1992 that I saw any real point in pursuing it. Prior to that Gopher had been the better medium" (personal communication, Green 2001).
Further, Green says that "No other sites registered themselves until well into 1993. If I recall correctly Jim Croft set up his site at the [National] Botanic Gardens early in 1993 after we discussed the possibilities and Mike Greenhalgh set up his Art History site around mid 1993 after we gave him a demo" (personal communication, Green 2001). Both of these appear to have been within the first 150 sites in the world.
At Sydney University, a web-server was installed on the Basser Department of Computer Science Honours students host (minnie.cs.su.oz.au) in early 1993, by Michael, now Michela, Ledwidge. This supported a local web-site registered with NCSA in November 1993, and provided a test-harness for a very early browser/editor WHype (Ledwidge 1993).
Michael Greenhalgh's Artserve was released on 15 June 1993, mirrored on the NCSA site at the University of Illinois. It continues to be accessible at its original URL, http://rubens.anu.edu.au/. It gained Honourable Mentions in the (overwhelmingly US) 'Best of the Web Awards' announced at the first International W3 Conference in Geneva on 26 May 1994, for both Education and Best Use of Multiple Media. (To put this in perspective, an individual humanities Professor, working alone, and running his web-server underneath his desk, was beaten only by one of the world's largest art institutions, Le Louvre).
Green also interacted closely with the ANU Supercomputing Facility (ANUSF), which naturally had direct connections with NCSA. This resulted in a web-site being created for ANUSF in mid-1993 (personal communication, Bob Gingold, December 2011). The Facility's Annual Report for 1993 was published on the site using the format-converter rtftohtml 2.7.5 (ANUSF 1993). (That now 20-year-old version of rtftohtml is still part of this author's publishing tool-set, and was used to produce the HTML PrePrint of this paper).
Unsurprisingly, the ANU's Department of Computer Science was experimenting with a web-server during the second half of 1993, including for presenting teaching materials (fittingly, for a unit on Open Systems Concepts and Applications), with the main page "last updated August 11, 1993" (personal communication, Chris Johnson, December 2011).
Within 1km of the ANU, the Australian National Botanical Gardens (ANBG) site was registered by NCSA on 6 July 1993, and announced on 8 July 1993 (Croft 1993). Key players there included Jim Croft and Greg Whitbread. The organisation as a whole clearly appreciated the significance of what it was doing, because its 1993-94 Annual Report stated, in its 'Highlights' section, "In July 1993, the ANBG released its World Wide Web server to the Internet, supplementing the Gopher information server released the previous year. This new server integrates the Gopher information and is the fastest growing information protocol in the world today. The ANBG was the first botanic gardens and herbarium to make information available this way" (ANBG 1994).
Also in Canberra, a government project called the Environmental Resources Information Network (ERIN) had a web-server operational from August 1993, leveraging off the nearby ANBG team. The ERIN Web and Gopher servers drew praise from U.C. Berkeley as early as 30 August 1993. Registration with CERN was sought on 15 October 1993. Despite having a 5-month advantage, the Gopher server's hit-rates were overrun by mid-1994. One reason was that the in-line display of images in the Mosaic browser proved to be an important feature for scientific resource-pages.
Another key attraction of the site derived from the sophistication of both its user interface and its integration with pre-existing databases: "By the end of 1993 using the Common Gateway Interface (CGI), connections between the web and our database were made to allow users to find geographic locations, map and model species distributions etc and this was much more interesting technically than static HTML pages!". The application already included auto-generated maps, with clickable areas that generated a pick-list enabling selection of the user's target-species, but at that stage zoom capabilities and map-overlays for cities, rivers and roads had not yet been delivered (Boston & Stockwell 1995 and personal communication, March 2011).
In August 1993, David Green travelled to Hobart to install a web-server for the Tasmanian Parks and Wildlife Service (ANUSF 1993).
A small Northern Territory Company, NT.Net set up web-pages for the Northern Territory Tourist Commission (NTTC) in September 1993 (personal communication, Tom Koltai, December 2011).
At the University of Sydney, a further very early contribution in the humanities was James Farrow's Shakespeare web-site, The Works of the Bard, which he launched in October 1993 (Farrow 1998). In early 2012, a DNS entry still existed for the original www.cs.su.oz.au domain, re-directing to a pathname within the domain sydney.edu.au. All of the servers identified in this section fell within the timeframe of the first 200 registered by CERN and NCSA.
During 1993, the acquisition of copies of various versions of Mosaic, by probably some hundreds of people in Australia, gave considerable impetus to both web-usage and the creation of web-servers and material to load up on them. The influential Melbourne PC Club offered (X)Mosaic v.0.8 as a bulletin board download from mid-to-late February 1993 (personal communication, Stephen Loosley, December 2011).
My own first experiment with the Web as a teaching-medium was in an ANU MBA class in August 1993. However, in a paper in November 1993 on the financing of the Australian Internet, the only reference I made was this: "If the services are attractive enough (and such facilities as gopher, World-Wide-Web and X-Mosaic might well satisfy that requirement), it may prove feasible to charge fees approaching those of commercial value-added networks" (Clarke 1993). Tony Barry's papers at the same conference and at another event shortly afterwards showed a much greater appreciation of the impact that the Web was to have (Barry 1993, Barry & Stanton 1994).
A November 1993 version of the register (Mason 1993) lists the following Australian servers:
In December 1993, the register of Australian web-servers operated by David Green for NCSA, for many years at http://life.anu.edu.au:80/links/ozweb.html, showed only nine, eight of them at ANU or launched with the support of Green himself (Barry & Stanton 1994, with the individuals who were primarily responsible interpolated by this author):
During December 1993, there were also announcements on NCSA's What's New pages of a site for an additional community organisation, the Australian Public Access Network Association (APANA), and for the Northern Territory (now Charles Darwin) University, and the University of Canberra. By the end of 1993, a first site for a secondary school had been established, for Vermont Secondary College in Victoria, hosted by Monash University (personal communication, Stephen Loosley, December 2011).
At some stage between mid-to-late 1993 and mid-1994, the 'pioneer' phase was over. The Internet and hence the Web were increasingly accessible from outside academe, and the benefits of being an early-mover in the web-publishing space were becoming apparent to leaders across government, community organisations and industry. This section draws an arbitrary distinction between 'pioneers' in 1993 and 'early adopters' in 1994.
At the boundary was Matthew Ciolek's Coombsweb, which involved migration of a substantial collection that had been available worldwide by other means since September 1991. "At the time of its launch (25 Jan 1994) Coombsweb was ... the 850th site in the world ... The Asian Studies sites managed or supervised by Matthew Ciolek remain an important part of the [Virtual Library], as well as being now the oldest" (WVL 2008). The claim of being "the 850th site in the world" was based on an inspection of the CERN register at the time (interview, 2010).
With the emergent liberalisation of Acceptable Use Policy, Internet Service Providers were beginning to emerge. One that offered web-hosting at an early stage was Pegasus, some time between late 1993 and early 1994 (personal communication, Ian Peter, December 2011).
Within the universities, librarians played important roles in stimulating adoption. They had initiated a movement commonly referred to as Campus Wide Information Systems (CWIS). This predated the Web's emergence, because gopher appeared to offer an excellent basis for providing remote access to text and the discovery of text. During 1993-94, the CWIS efforts rapidly converted across to the increasingly popular, multi-media Web service (CAUL 1995). Most encountered at least a degree of apathy, and a number were confronted by outright opposition from university administrators.
On the basis of the limited searching that has been undertaken, the earliest corporate web-site that has been reliably located is that of Xanadu, at http://www.aus.xanadu.com/, live on 19 April 1994. However, with Pegasus and possibly several other ISPs active during the first half of 1994, it is likely that some other sites were in place by then.
In May 1994, "a prototype distributed hypertext search product called World Wide Web (WWW)" was still perceived merely as "an important example of contemporary services", rather than as a tsunami or a 'killer app' (Clarke & Worthington 1994).
Possibly the earliest community organisation to launch on the Web was Railpage Australia and New Zealand. It was originally implemented in 1992 using a different format, was converted to a web-site in July 1994, and claimed to be among the first 100 web sites to be hosted in Australia (Evans 2009). Another community-service site that originated in late 1994 is the Index of Information Systems Journals, originally at the University of Tasmania, subsequently at Deakin University in Geelong (Lamp 2004).
By mid-1994, individuals were also making headway in applying the Web. The oldest identified site to date is that of Danny Yee, whose book review site was launched in June 1994, originally at thor.anatomy.su.oz.au/danny/book-reviews/ (personal communication, January 2012). In July 1994, during a presentation to the Canberra Branch of the Australian Computer Society (ACS), Tom Worthington noted that "the photographs have been scanned at a resolution suitable for display on a personal computer and compressed to be transmitted in a reasonable time (about 30 seconds each) with a 9600 bps modem" (Worthington 1994). My own web-site was established in August 1994, but publicised only in February 1995. As late as April 1995, a Senate Committee that considered the need for regulation of content reticulated over networks was focussed on 'bulletin board systems' and had to have the Web explained to them (Clarke 1995).
A further early example of a commercial operation selling access to the Internet with direct support for use of the Web was the Ausnet Instant Internet Access Start-up, a bundle delivered to newsagencies across Australia in October 1994. It included a copy of Netscape v.0.9b and sold 55,000 copies (personal communication, Tom Koltai, December 2011). Another important contextual factor was the capacity of Internet connections at the time. In June 1994, there was no broadband, and the cost of (64kbps or 128kbps) ISDN was out of the reach of consumers. The standard for modems current at the time was 14,400 bps, but "some users still use 1200 bps modems and ... many use 2400 bps units" (Nallawalla 1994).
An indication of the growth rates in web-sites is provided by Goldschlager (1995). That paper reviewed the many emergent categories of Web search mechanism, and reported on a www.au index developed by that paper's author. In its first 4 months from December 1994 to March 1995, the catalogue grew from 235 to 809 entries. As the author presciently noted, "challenges will arise as the database grows larger".
Identifying the second government agency web-site after ERIN has proven challenging. PIENet was a well-known web-site established by the then Department of Primary Industry and Energy (DPIE) - whose contemporary equivalent is the Department of Agriculture, Fisheries and Forestry (DAFF). An archive copy of the site in late 1996 includes the statement that PIENet was established on 22 December 1994. A prime mover in the initiative was Peter Talty, who, in his role as Chair of the Canberra Branch of the ACS, drove the release of a network service for ACS members during 1994.
"The Defence Home Page was launched on 2 March 1995" (Worthington 1998). The Special Broadcasting Service (SBS) had a web-site from March 1995, courtesy of the ACS and Tom Worthington (ACS 1995). A March 1995 by-election in Canberra featured a supporting web-site (private communication, Kerry Webb, July 2011). The National Library web-site was launched in May 1995 (NLA 1995). The webmaster was Michael Ledwidge, who had graduated with Honours from Sydney University in 1993. Also in May 1995, an early sign of 'media convergence' was a web-site that complemented a TV show, Hot Chips, produced by the Australian Broadcasting Commission (ABC). The site is archived at http://www.abc.net.au/hotchips/.
The abruptness with which the Web shot from obscurity to prominence is exemplified by the treatment of the topic in the Australian Unix Users Group (AUUG) Conferences. The September 1992, 1993 and even 1994 events run by this large and dynamic community did not include a single paper on the Web, or on hypertext, or even on gopher. (Reasonably enough, the strongly technical members saw them as playthings rather than real computing). The earliest entry in the AUUG monthly Newsletter appears to be at the end of 1993 (Sanders 1993), followed by its inclusion in a workshop in February 1994. The next mention is two paras. in a review of Internet services, on p. 65 of the AUUG Conference in September 1994 (Cave 1994). Yet, at the September 1995 event, 31 of the 78 papers were specifically on the Web, and Robert Cailliau was a keynote speaker (AUUG 1995). Similarly, the first mention of the Web in the Melbourne PC Users Group monthly newsletter appears to have been in June 1995 - even though XMosaic had been available on the Group's bulletin board two years earlier.
Corporate web-sites rapidly implemented Internet commerce capabilities during 1995, mostly using variants of the 'shopping cart' model (Clarke 2004b). The Internet Archive discloses that a proprietary shopping cart application, developed by Harris Technologies for its own use, had reached a substantial level of sophistication by 22 December 1996 - suggesting that the innovation took place considerably earlier, very probably during 1995. There were eCommerce nominations for the inaugural Telstra/AFR Web Awards in the third quarter of 1996 (for which the author was a judge), and in subsequent years one and then multiple eCommerce classifications were established. Subsequent extensions to the architecture of the original Web have been under the aegis of such terms as 'Web services' and 'service-oriented architecture' (SOA).
Despite Berners-Lee's original intentions, there was no indexing mechanism intrinsic to the Web. The Dublin Core metadata movement was launched within US library circles in early 1995, with enthusiastic UK and Australian involvement shortly afterwards (DCMI 1995, Clarke 1997). This spawned the Australian Government Locator Service (AGLS) in 1997. Despite the elegance and logical advantages of metadata-based search, Lycos from July 1994 and Altavista, from December 1995, offered users convenience and ready availability. Brute-force text-search became the mainstream, to the extent that metadata-based search remains unknown to the vast majority of Web users. Altavista fell victim to a failed attempt to monetise its dominance via a portal and eCommerce strategy, combined with the the dot.com collapse of 2000 (Wikipedia). Google, formed in 1998, was the beneficiary.
A further question of interest concerns the oldest still-available and/or continuously-available web-sites in Australia. With little doubt, but more than a little surprise, the prize goes to the humanities ahead of the sciences. The contenders appear to be:
The majority of the information that the research has unearthed and on which this paper is based is 'supply-side', and tells the story of the people and organisations who pioneered the provision of information via web-servers. Information about the 'demand-side' is difficult to come by, but aggregated data throws some light on the matter.
Statements about Internet traffic require care. By design, there is no chokepoint through which all traffic passes, and hence most measures of network traffic are localised, proxies or estimates, rather than comprehensive and authoritative. However, during the period of the NFSnet backbone (1986-95), fairly reliable statistics were gathered. No statistics for Australia have been located for the relevant period, but experiences in Australia at the time were consistent with the patterns evident in data available from overseas sources.
From the implementation of TCP/IP in 1983 until the mid-1990s, user-related Internet traffic was distributed across a range of protocols, with file-transfer (ftp) dominating the volume, followed by the smtp and pop protocols (email), nntp (network news) and telnet (remote terminal simulation).
The original purpose of the Web's http protocol was the transfer of files suitable for rendering on the user's screen. Interfaces to back-end databases were rapidly devised and were in mainstream use by early 1995 (Clarke 2002). Since then, a considerable amount of content has been generated 'on the fly' and formatted as though it resided on a server in a requested file. This provided a firm foundation for commercial transactions from the end of 1994 onwards, and for access to emails in the browser-window, which began later but in recent years has become the norm for many categories of user.
A graph in Berners-Lee (1996) shows growth in the traffic on the primary web-server, on a log-scale, as "a steady exponential ... at a factor of ten per year, over three years", from July 1992 to April 1994. During the year from March 1994 and March 1995, Web traffic grew from 5% to 25% of a significantly larger volume of Internet traffic. Web traffic-volume overtook ftp traffic-volume in the 2nd quarter of 1995, a mere 3-1/2 years after the protocol appeared on the Internet (Lance 1995, Gray 1996, Odlzyko 2003). Within two further years, in early 1997, The Web was accounting for in excess of 50% of the traffic volume. Odlzyko's Table 2 provides ample evidence in support of the Web-browser as the Internet's first 'killer app'.
From 1995 onwards, growth rates in Web traffic were very high in Australia as elsewhere, with rapid adoption as a publication medium, and large numbers of individuals installing the quickly-improving web-browser software to gain access to the content. "[In mid-1997,] every University in Australia has at least one World Wide Web server and a 'home page'" (Debreceny 1997).
After 1997, Web traffic continued to increase year-on-year by of the order of 50% p.a. for some time, but remained below half of the total traffic. That was because, from about 1998 onwards, peer-to-peer (P2P) traffic increased greatly, associated with, chronologically, Napster, Kazaa and BitTorrent. P2P traffic may have exceeded Web traffic c. 2002-07. Streaming is most appropriately performed using a specific-to-purpose protocol running over the low-overhead alternative transport protocol, UDP. Since 2007, however, the Web has also been much-used as a funnel for not only file-download but also streaming of audio, video and animation. This is achieved by breaking the stream into multiple small files (Wikipedia). As a result of this, combined with copyright-owners' efforts to repress P2P traffic in copyright-infringing materials, the Web resumed its leadership in the protocol tables after 2007 (Anderson 2007).
The Web was originally conceived as "a wide-area hypermedia information retrieval initiative aiming to give universal access to a large universe of documents" (W3C 1992). Berners-Lee was aware of the precursors to the Web identified in the earlier section of this paper. But he intentionally set his sights lower than the visionaries, and, with his employer's concurrence, he intentionally made the technology and its implementation transparent to its users.
From the perspective of innovation theory, the Web delivered new components that enabled significantly improved exploitation of existing infrastructure, stimulated a range of refinements and extensions to that infrastructure, and quickly replaced competitors. In the terms of the Henderson-Clark model, it represented `modular innovation'. The openness of the technology and standards resulted in it being quickly enhanced and built upon, and hence it rapidly became an important part of the complex of Internet infrastructures. Although the original technology was the work of a very small team, and although an expanded team has continued to work on enhancements ever since, within the context of an industry consortium, a great deal of the subsequent innovation has emerged from user communities, and the `official' organisation has only ever been able to exercise limited control over the phenomenon.
Many of the propositions of Diffusion of Innovation theory are borne out by the evidence, although some variations are apparent. The innovation was readily trialable, and the results observable, using infrastructure that was already to hand. It was immediately perceived by its earliest users to have relative advantages over all predecessor technologies, and over a competitor technology, gopher. The Web was an implementation of ideas that had been 'in the air' for some time, and hence it was understandable to leaders in the field. It was already feasible to use a tool to transfer a file. But a user then had to select, and in many cases to acquire, an appropriate tool to display its contents. There was no capability at the time to fetch-and-display, especially not easily and seamlessly, and that was what the Web offered. Individual adopters migrated rapidly through the early knowledge and persuasion stages, and the degree of positive reinforcement was close to the strongest form of `instant gratification'.
Rogers posits that mass media channels are more important during the preliminary knowledge phase, after which interpersonal channels become key. Mass media was indeed important in the very earliest phase of the Web, in the form of seminars and conference presentations. Interpersonal channels very quickly became critical, however. Although the earliest adopters in Australia were hosted in universities scattered along the east coast, a strong concentration of them was in Canberra, at and adjacent to the university in which the earliest Australian pioneers worked, and in contact with them.
A further relative advantage, starting with the NeXT-only WordWideWeb/Nexus browser, then Viola, but critically Mosaic, was the display of images, initially in separate windows ('pop-ups', as they were later dubbed), but then in the same window, and soon after that with text neatly folding around them. The criticality of this was expressed by several Australians, e.g. "At first I didn't do much with [the Web, in early-to-mid-1992], just experimented because it was text only. It was only when [a] hypermedia browser [arrived, in mid-to-late 1992] ... that I saw any real point in pursuing it" (personal communication, Green 2001).
It was only at a later stage, when users who were less driven by professional motivations needed a 'wow' factor, that glitz become important: Mosaic "broke away from the small pack of existing browsers by including features -- like icons, bookmarks, a more attractive interface, and pictures -- that made the software easy to use and appealing to 'non-geeks'" (NCSA 2009).
The characteristic of compatibility with existing values, past experiences and needs was evidenced by the Web's support for the existing FTP protocol as well as its native HTTP, and for existing ASCII format as well as its native HTML. For ERIN, on the other hand, a critical aspect was compatibility with existing databases: "By the end of 1993 using the Common Gateway Interface (CGI), connections between the web and our database were made to allow users to find geographic locations, map and model species distributions etc and this was much more interesting technically than static HTML pages!" (personal communication, March 2011).
Complexity was avoided, in that installation of the httpd server software was not unduly challenging for a person with modest technical skills. And all that a browser-user had to do was download, install and invoke the browser, type in an address, and fetch-and-display. After that, additional content could be found by clicking on links. Typical of the reactions of Australians in 1992-93 was that of astrophysicist Ray Norris, who said that, when a graphical browser was demonstrated to him at NCSA in October 1992, "I got very excited about it" (personal communication, March 2004).
Matthew Ciolek nicely summarised two critical factors about the Web that caused him to convert his already-substantial public electronic library to the Web at the beginning of 1994: "It was the first time that no tech support was needed to publish documents. You just needed an account [and some capability with HTML editing]", and "the visibility of the HTML source-code for each page enabled the appropriation of code, templates and techniques" and hence facilitated rapid dissemination of skills (interview, 2010). This was an environment in which lay-people could publish conveniently, quickly and inexpensively, and had the motivation to do so because other people were publishing, and the pooling of resources was perceived to be valuable for all concerned.
A simplified re-construction is as follows:
Only a very small number of the first-round social network were Australians. The awareness, enthusiasm and energy of those few, the richness of their own social networks, particularly within and adjacent to the ANU, and the awareness, enthusiasm and energy of the second-round pioneers, resulted in experimentation and in innovative applications.
In some cases, such as the bioinformatics and social sciences collections, substantial sets of resources were quickly made available. In other cases, the innovations were far from obvious at the time. For example, the richness of fine art images and their relationship to cultural monuments such as Borobudur (on the island of Java), were a major surprise to those who saw them. ERIN's innovative application was its very early harnessing of technological extensions in order to deliver map-based interfaces.
The rapid growth that commenced in 1993 demonstrated that critical mass had been achieved. This paper is witness to the productivity that arises from ready discoverability and accessibility. The author had accumulated electronic sources over a period of many years. On the basis of that material and copious, rapid, Web-based literature-searching, a working paper - containing about two-thirds of the review draft of this paper - was written in 7 hours, on 18 April 2010. Review and refinement to publication-standard of course required the investment of many multiples of that time. On the other hand, a public resource has existed since that date, and feedback from the c. 750 human downloads of the PrePrint versions of this paper to date has resulted in the acquisition of a considerable volume of additional information relevant to the topic.
In the two decades since the events chronicled in this paper, the Web has become the world's electronic library, yet also the vehicle for a vast amount of transactional activity variously of economic, administrative and social natures. This section briefly identifies some issues that have arisen during that period, which are threatening to the legacy of the Web as it was originally conceived and implemented.
The oft-repeated mantra "Information wants to be free ..." is not the battle-cry that many people have thought it was. It is actually a concise expression of the fundamental tension between those who want to gain access to information and those that want to exercise control over it, as a basis for power (Clarke 2000). The early years of the Internet unleashed euphoria about a new world of free information (Barlow 1994, 1996). But that optimism was very quickly tempered by warnings about an imminent 'new dark ages' Clarke (1999b) and 'the Internet as a tool of authoritarianism' Clarke (2001). As this paper was being finalised, the majority of the nations of the world were seeking to impose, through the International Telecommunications Union (ITU)'s World Conference on International Telecommunications (WCIT), a new control regime over the Internet and Web, which would facilitate the reversal of the gains in information openness and accessibility that had been achieved during the Web era.
Many of the challenges to the Web's original philosophy have not been political in nature, but rather straightforward attempts to achieve commercial advantage. Wired magazine displayed the first banner-ads in October 1994, giving rise to the claim that "There will be billboards along the Information Superhighway" (Schrage 1994). There have been continual manouevres to lure consumers to use for-profit 'portals', to put 'paywalls' around parts of the Web in order to fund content and services, and once having achieved control of consumers' eyes, to keep them inside these 'walled gardens'. Most of these attempts failed, partly because "consumers are smarter than media organisations thought" (Boutin 1998), and partly because the Web's architecture was hostile to them.
There have accordingly been many attempts to convert Web architecture from its inherently 'user-pull' orientation into a 'marketer-push' technology, and to re-engineer the function of the 'server' from service to control. Early versions of these developments are chronicled in Clarke (1999a). More recently, there have been concerted efforts to make browsers subsidiary to servers, by enabling servers to deliver code to the browser in order to control the device's behaviour, and through that code to gain as much control as practicable of the consumer's behaviour as well. Microsoft's highly permissive ActiveX technology lends itself to this, and extensions to Javascript and the HTTP protocol have extended the manipulation into non-Microsoft environments. The lofty-sounding ambitions declared for Web 2.0 have acted as a smoke-screen for deep-nested interference by servers with the operation of consumers' devices (Clarke 2008). The most recent version of the markup language, HTML5, delivered by the business consortium W3C, is highly facilitative of marketer activities, but highly privacy-intrusive from the consumer's perspective.
Meanwhile, since 2004, social networking services have emerged to exploit individuals' willingness to contribute content and expose the behaviour of themselves and other people. Endeavours to 'monetise' this phenomenon have led to the capture and inference of demographic profiles, and further architectural and procedural innovations in order to support the acquisition of advertising revenue.
Within organisations, there have been multiple, successive attempts to implement 'thin clients', in order to exercise control over employees' electronic behaviour. Since the explosion of smartphone adoption following the release of Apple's iPhone in 2007, and of tablets following Apple's iPad in 2010, suppliers have been seeking to exercise a related form of control over their customers. Controlled distribution of both software and content, and built-in spyware, have been complemented by constraints on device functionality. Many of these handsets are 'consumer devices' in the narrow sense of being 'dumbed-down' to the specific capabilities that the supplier is currently prepared to deliver to its customer. They may be built over a general-purpose computing platform, but providers are denying access to the platform's flexibility not only by consumers but even by developers. This provides the device-suppliers with customer lock-in, and hence protects high prices for software and services, and control over the rate of 'planned obsolescence'.
The Web was created by a computer scientist working in a particle physics laboratory in Geneva in 1989-93, as a convenient form of electronic publishing, featuring a very limited but useful sub-set of hypertext ideas. It was an idea whose time had come, and it over-ran its predecessors due to its capacity to deliver value and its simplicity of use, for content-consumer and originator/publisher alike.
This paper has identified pioneering activities in a single nation, Australia, during the period 1992-94. Key contributions were made by academics in disciplinary areas as diverse as bioinformatics, astrophysics, computer science, the humanities (in particular art history) and the social sciences, and by professional librarians. That foundation ensured that Australia has been as active as any country in the world in both content-contribution and content-consumption.
The developments noted in the Discussion section may lead future observers to perceive the quarter-century commencing in the early 1990s to have been the high-point of freedom of information to the public, with the World Wide Web as the trigger for a short period of prosumer power. It remains to be seen whether analyses conducted in the 2020s will find a broad information landscape, or a labyrinth of walled gardens that are controlled by economic interests, and that are heavily policed by law enforcement agencies.
Note: Wikipedia articles have been cited in those cases where no satisfactory reference has been located and the relevant Wikipedia article appeared to be comprehensive and reliable. The URLs shown below were most recently accessed variously in November 2011 and January 2012.
ACS (1995) 'Minister launches SBS multimedia Internet service at Multimedia Forum One' Australian Computer Soeciety, 9 March 1995, at http://www.tomw.net.au/sbs1.html
ANBG (1994) 'Annual Report - 1993-94' Australian National Botanical Gardens, September 1994, at http://anbg.gov.au/anbg/annual-report/annual-report-1994.html
Anderson N. (2007) 'The YouTube effect: HTTP traffic now eclipses P2P' Ars Technica, 19 June 19 2007, at http://arstechnica.com/news.ars/post/20070619-the-youtube-effect-http-traffic-now-eclipses-p2p.html
Andrews F.T. (2002) 'The telephone network of the 1960s' IEEE Communications Magazine 40, 7 (Jul 2002) 49 - 53
Andreessen M. (1993a) 'NCSA X Mosaic 0.5 released' Archived email, 23 January 1993, at http://1997.webhistory.org/www.lists/www-talk.1993q1/0099.html
Andreessen M. (1993b) 'NCSA Mosaic 1.0 released' Archived email, 21 April 1993, at http://1997.webhistory.org/www.lists/www-talk.1993q2/0128.html
ANUSF (1993) 'Annual Report _ 1993' Supercomputing Facility, Australian National University, January 1994, at http://anusf.anu.edu.au/annual_reports/annual_report93/
AUUG (1995) 'Proc Conf AUUG'95' (Sep 1995), at http://web.archive.org/web/20090406231446/http://csu.edu.au/special/conference/apwww95/program.html
Baran P. (2002) 'The beginnings of packet switching: some underlying concepts' IEEE Communications Magazine, IEEE 40, 7 (Jul 2002) 42 - 48
Barlow J.P. (1994) 'The Economy of Ideas', Wired 2.03 (March), at http://www.wired.com/wired/archive/2.03/economy.ideas_pr.html
Barlow J.P. (1996) 'A Declaration of the Independence of Cyberspace' Hotwired 4.06 (8 February), at http://www.wired.com/wired/archive/4.06/independence.html
Barry A. (1993) 'Information Access - Technologies and Services' Proc. Networkshop'93, Melbourne, at http://tony-barry.emu.id.au/pubs/1993/Networkshop.html
Barry A. (1995) 'Integrating Electronic Publishing and Information Provision at ANU' Proc. AusWeb'95, April 1995, at http://ausweb.scu.edu.au/aw95/publishing/barry/
Barry A. & Stanton D. (1994) 'CWIS access' Australian Library Review 11, 1 (1994), at http://tony-barry.emu.id.au/pubs/1994/alr.html
Berners-Lee T. (1993) 'Attention Server Administrators: are you on this list?' Email message, 1 July 1993, at http://groups.google.com/group/comp.infosystems.www/msg/3eae0315b1c6bcbb?hl=en
Berners-Lee T. (1995) 'The WorldWideWeb browser' W3C, undated, apparently of 1995, at http://www.w3.org/People/Berners-Lee/WorldWideWeb.html
Berners-Lee T. (1996) 'The World Wide Web: Past, Present and Future' W3C, August 1996, at http://www.w3.org/People/Berners-Lee/1996/ppf.html
Berners-Lee T. (1999) 'Weaving the Web', originally published 1999, republished in paperback by Harper Collins, 2000
Berners-Lee T. & Cailliau R. (1990) 'WorldWideWeb: Proposal for a HyperText Project' CERN, 12 November 1990, at http://www.w3.org/History/19921103-hypertext/hypertext/WWW/Proposal.html
Boston A.N. & Stockwell D.R.B. (1995) 'Interactive species distrbution, reporting, mapping and modelling using the World Wide Web' Computer Networks and ISDN Systems 28 (1995) 231-238
Boutin P. (1998) 'Pushover?' Wired 6.03 (March 1998), at http://www.wired.com/wired/archive/6.03/updata.html?pg=1
Bush V. (1948) 'As we may think' The Atlantic Monthly, 1948. Republished in Greif I. (Ed.) 'Computer-Supported Cooperative Work: A Book of Readings, Morgan-Kaufmann, San Mateo Cal., 1988, at http://www.theatlantic.com/doc/194507/bush
Cailliau R. & Ashman H. (1999) 'Hypertext in the Web - a History' ACM Computing Surveys 31(4), December 1999, at http://www.cs.brown.edu/memex/ACM_HypertextTestbed/papers/62.html
CAUL (1995) 'Summary of Campus-Wide Information Service (CWIS) Survey Results' Council of Australian University Librarians, 23 June 1995, at http://www.caul.edu.au/surveys/cwis.htm
Cave C. (1994) 'The Joys, Savings & Benefits of an Internet Connection' Proc. Conf. AUUG, September 1994, pp. 61-70, in http://books.google.com.au/books?id=Zju3xMaLsGcC&pg=PA199&dq=AUUG+1994&hl=en#v=onepage&q=AUUG%201994&f=false
CERN (1992a) 'History to date', CERN, 3 November 1992, at http://www.w3.org/History/19921103-hypertext/hypertext/WWW/History.html
CERN (1992b) 'W3 servers', CERN, 3 November 1992, at http://www.w3.org/History/19921103-hypertext/hypertext/DataSources/WWW/Servers.html
CERN (1993) '' at http://tenyears-www.web.cern.ch/tenyears-www/
Ciolek T.M. (1998) 'Asian Studies and the WWW: a Quick Stocktaking at the Cusp of two Millennia' Proc. Pacific Neighbourhood Consortium (PNC) Annual Meeting, Academia Sinica, Taipei, Taiwan, 15-18 May 1998, at http://www.ciolek.com/PAPERS/pnc-taipei-98.html
Ciolek T.M. (1999) 'Global Networking: A Timeline' T. Matthew Ciolek, 1999, at http://www.ciolek.com/GLOBAL/milestones.html
Clarke R. (1993) 'AARNet Economics: How to Avoid Cooking the Golden Goose' Proc. Networkshop'93, Melbourne, at http://www.rogerclarke.com/II/AARNetEcs.html
Clarke R. (1995) 'Background to the Technology and the Issues' Overheads for a Public Seminar on the Regulation of Bulletin Board Systems, Senate Select Committee on Community Standards Relevant to the Supply of Services Utilising Electronic Technologies, Xamax Consultancy Pty Ltd, April 1995, at http://www.rogerclarke.com/II/BBSReg.html
Clarke R. (1997) 'Beyond the Dublin Core: Rich Meta-Data and Convenience-of-Use Are Compatible After All' Xamax Consultancy Pty Ltd, July 1997, at http://www.rogerclarke.com/II/DublinCore.html
Clarke R. (1999a) 'The Willingness of Net-Consumers to Pay: A Lack-of-Progress Report' Proc. 12th International Bled Electronic Commerce Conference, Bled, Slovenia, June 7 - 9, 1999, at http://www.rogerclarke.com/EC/WillPay.html
Clarke R. (1999b) 'Freedom of Information? The Internet as Harbinger of the New Dark Ages' First Monday 4, 11 (November 1999), at http://firstmonday.org/issues/issue4_11/clarke/
Clarke R. (2000) '"Information Wants to be Free ..."' Xamax Consultancy Pty Ltd, Canberra, February 2000, at http://www.rogerclarke.com/II/IWtbF.html
Clarke R. (2001) 'Paradise Gained, Paradise Re-lost: How the Internet is being Changed from a Means of Liberation to a Tool of Authoritarianism' Mots Pluriels 18 (August 2001), Special Issue on 'The Net: New Apprentices and Old Masters', at http://www.arts.uwa.edu.au/MotsPluriels/MP1801rc.html, PrePrint at http://www.rogerclarke.com/II/PGPR01.html
Clarke R. (2002) 'The Birth of Web Commerce' Xamax Consultancy Pty Ltd, 2002, at http://www.rogerclarke.com/II/WCBirth.html
Clarke R. (2004a) 'Origins and Nature of the Internet in Australia' Xamax Consultancy Pty Ltd, various versions on the Web and in print, most recently of 29 January 2004, at http://www.rogerclarke.com/II/OzI04.html
Clarke R. (2004b) 'The Shopping Cart Model' Xamax Consultancy Pty Ltd, September 2004, rev. September 2009, at http://www.rogerclarke.com/EC/ShoppingCart.html
Clarke R. (2008) 'Web 2.0 as Syndication' Journal of Theoretical and Applied Electronic Commerce Research 3,2 (August 2008) 30-43, at http://www.jtaer.com/portada.php?agno=2008&numero=2#, Preprint at http://www.rogerclarke.com/EC/Web2C.html
Clarke R. & Worthington T. (1994) 'Vision for a Networked Nation: The Public Interest in Network Services' Proc. Conf. Int'l Telecomms Soc., Sydney, July 1994, at http://www.acs.org.au/president/1997/acsnet/acsnet.htm
Croft J. (1993) 'Launch of WWW - 8 July 1993', Australian National Botanic Gardens, at http://www.cpbr.gov.au/web-history/www-launch.html
Cybertelecom (2011) 'EMail History' Cybertelecom, undated, but apparently updated at September 2011, at http://www.cybertelecom.org/spam/history.htm
Davies, D. W. (2001) 'An historical study of the beginnings of packet switching' Computer Journal 44, 3 (2001) 152-62
DCMI (2011) '' Dublin Core Metadata Initiative, 2011, at http://dublincore.org/workshops/
Debreceny R. (2007) 'The Management of World Wide Web Resources in Australian Universities' Proc. ASCILITE'97, 7-10 December 2007, at http://www.ascilite.org.au/conferences/perth97/papers/Debreceny/Debreceny.html
Deja-Vu (2000) 'Web Timeline' Metamatrix, undated but apparently c. 2000, at http://dejavu.org/forsta.htm
Farrow J. (1998) 'Brief History of the Shakespeare Web-Site' University of Sydney, 19 November 1998, at http://www.cs.su.oz.au/~matty/Shakespeare/email.html
Festa P. (2001) 'Paul Kunz: Turning on the World Wide Web' ZDNet, 11 December 2001, at http://www.zdnet.com.au/paul-kunz-turning-on-the-world-wide-web-120262302.htm
Furth S.E. (1972) 'STAIRS - A user-oriented ful text retrieval system' Law and Computer Technology 5, 5 (Sep-Oct-1972) 114-119
Furuta R. (1992) 'Important papers in the history of document preparation systems: basic sources' Electronic Publishing 5, 1 (March 1992) 19-44
Garraghan G. (1946) `A Guide to the Historical Method' Fordham University Press, 1946
Gibson W. (1982) `Burning Chrome' Omni, July 1982
Gillies J. & Cailliau R. (2000) 'How the Web Was Born: The Story of the World Wide Web' Oxford University Press, 2000
Goldfarb C.F. (1981) 'A generalized approach to document markup' Proc ACM SIGPLAN SIGOA Symposium on Text Manipulation, SIGPLAN Notices 16, 6 (June 1981) 68-73
Goldschlager L.M. (1995) 'The WWW.AU Index of Australian Web Sites' Proc. AusWeb'95, April 1995, at http://ausweb.scu.edu.au/aw95/tools/goldschager/
Gottschalk L. (1969) `Understanding History' Knopf, 1969
Gray M. (1996) 'Web Growth Summary', 1993-95, at http://www.mit.edu/~mkgray/net/web-growth-summary.html
Green D. (2001) 'What was the first Australian WEB server?' Personal correspondence, Wed, 12 Dec 2001 02:49:17 +1100 (EST)
Hafner K. & Lyon M. (1998) 'Where Wizards Stay Up Late: The Origins of the Internet' Simon & Schuster, 1998
Henderson R.M. & K.B. Clark (1990) `Architectural Innovation: The Reconfiguration of Existing Product Technologies and the Failure of Established Firms' Administrative Science Quarterly 35, 1 (March 1990) 9-30
Huurdeman A.A. (2003) 'The Worldwide History of Telecommunications' John Wiley, 2003
JE (1906) `Jewish Encyclopaedia: The unedited full-text of the 1906 Jewish Encyclopedia' Entry for Concordance, at http://www.jewishencyclopedia.com/articles/4584-concordance
Jordanova L. (2006) `History in Practice' Hodder Arnold, 2006
Kernighan B.W. (1973) 'A Typesetter-independent TROFF' Computing Science Technical Report No. 97, AT&T Bell Laboratories, Murray Hill, New Jersey, 1982, at http://www.skytel.co.cr/unix/research/acrobat/8203.pdf
Kidwai A.R. (2005) `Reference Works on the Qur'an in English: A Survey', , The Message of Islam, undated but apparently of 2005, at http://islamicstudies.islammessage.com/ResearchPaper.aspx?aid=386
Korporaal G. (2009) 'AARNet: 20 Years of the Internet in Australia: 1989-2009' AARNet, Canberra, 2009
Lamp J.W. (2004) `Index of Information Systems Journals' Deakin University, Geelong, versions 1994-2012, at http://lamp.infosys.deakin.edu.au/journals/
Lance K. (1995) 'The Nature of Network Traffic' University of Newcastle, September 1995
Ledwidge M. (1993) 'Cruising and Creating Hypertext with WHype' Honours Thesis, Basser Department of Computer Science, University of Sydney, October 1993, at http://thequality.com/people/michela/weblog/archives/docs/Crusing_and_Creating_Hypertext_with_WHype.pdf
Leiner B.M., Cerf V.G., Clark D.D., Kahn R.E., Kleinrock L., Lynch D.C., Postel J., Roberts L.G. & Wolff S. (1997) 'A Brief History of the Internet' ISOC, 1997, at http://www.isoc.org/internet/history/brief.shtml
Malone D. (2000) 'Early Irish Web Stuff', David Malone, undated but apparently of c. 2000, at http://www.maths.tcd.ie/~dwmalone/early-web.html
Mason J. (1993) 'W3 SERVERS', Justin Mason, at http://jmason.org/WWW-servers.txt
Mosaic (1994) 'Index of /home/whatsnew' Mosaic Communications Corp, at http://home.mcom.com/home/whatsnew/?C=N;O=D, mirror at http://shii.org/history/whatsnew/
Nallawalla A. (1994) 'Which Modem to Buy?' PC Update Online, Melbourne PC User Group, June 1994, at http://www.melbpc.org.au/pcupdate/9406/9406article2.htm
NCSA (1996) 'In the beginning there was NCSA Mosaic....' National Center for Supercomputing Application, undated, but apparently of 1996, at ftp://ftp.ncsa.uiuc.edu/Mosaic/Windows/Archive/MosaicHistory.html
NCSA (2009) 'About NCSA Mosaic' National Center for Supercomputing Application, 2009, at http://www.ncsa.illinois.edu/Projects/mosaic.html
Nelson T.H. (1965) 'Complex information processing: a file structure for the complex, the changing and the indeterminate' Proc. ACM 1965 20th National Conference, pp. 84-100, mirrored here
Nelson T.H. (1980) 'Literary Machines: The report on, and of, Project Xanadu concerning word processing, electronic publishing, hypertext, thinkertoys, tomorrow's intellectual revolution, and certain other topics including knowledge, education and freedom' Mindful Press, Sausalito, 1980 and subsequent editions
Netcraft (2010) 'Web Server Survey' Netcraft Ltd, April 2010, at http://news.netcraft.com/archives/web_server_survey.html
NLA (1995) 'National Library server launched' Gateways 15 (May 1995), National Library of Australia, at http://www.nla.gov.au/pub/gateways/archive/15/15.html#launch
Odlyzko A.M. (2003) 'Internet traffic growth: Sources and implications' in Optical Transmission Systems and Equipment for WDM Networking II, B. B. Dingel, W. Weiershausen, A. K. Dutta, and K.-I. Sato, eds., Proc. SPIE, vol. 5247, 2003, pp. 1-15, at http://www.dtc.umn.edu/~odlyzko/doc/itcom.internet.growth.pdf
Pam A. (1995) 'Where World Wide Web Went Wrong' Proc. AUUG'95, AUUG, archived at http://web.archive.org/web/20080829014758/http://www.csu.edu.au/special/conference/apwww95/papers95/apam/apam.html
Peter I. (2004) `Early Internet - History of PC networking' The Internet History Project, 2004, at http://www.nethistory.info/History%20of%20the%20Internet/pcnets.html
Reid B.K. (1980) 'A high-level approach to computer document formatting' Conference Record of the Seventh Annual ACM Symposium on Principles of Programming Languages, (January 1980).
Reid R. H. (1997) 'Architects of the Web: 1,000 Days that Built the Future of Business' Wiley, New York, 1997
Rogers E.M. (1962) 'Diffusion of Innovations' The Free Press, New York, 1962, 5th Edition , 2003
Rogers E.M. & Shoemaker F.F. (1971) `Communication of Innovations: A Cross-Cultural Approach' Free Press, 1971
Russell A.L. (2006) ''Rough Consensus and Running Code' and the Internet-OSI Standards War' IEEE Annals of the History of Computing 28, 3 (July-Sept 2006) 48 - 61
Salford (2011) 'The birth of electrical communications -- 1837' NNTR, University of Salford, undated but apparently of 2011, at http://www.cntr.salford.ac.uk/comms/ebirth.php
Sanders T. (1993) 'Internet Hypertext is Here' AUUG Newsletter 14, 6 (December 1993) 95-96, reprinted from USENIX ;login: 18, 5, in in http://minnie.tuhs.org/Archive/Documentation/AUUGN/AUUGN-V14.6.pdf
Schrage M. (1994) 'Is Advertising Dead?' Wired 2.02 (February 1994), at http://www.wired.com/wired/archive/2.02/advertising_pr.html
Sewell W. Jr (2005) `Logics of History: Social Theory and Social Transformation' University of Chicago Press, 2005
SGML-UG (1990) 'A Brief History of the Development of SGML' SGML Users' Group, 11 June 90, at http://www.sgmlsource.com/history/sgmlhist.htm
Smoliar S.W. (1983) 'Review of 'Literary machines' by Ted Nelson' Newsletter, ACM SIGSOFT Software Engineering Notes 8, 5 (October 1983) 34-36
Standage T. (1998) 'The Victorian Internet' Walker & Company, 1998
Stewart W. (2000) 'Mosaic -- The First Global Web Browser' The Living Internet, 2000, at http://www.livinginternet.com/w/wi_mosaic.htm
Stumpers F.L. (1984) 'The history, development, and future of telecommunications in Europe' IEEE Communications Magazine 22, 5 (May 1984) 84 - 95
Tuomi I. (2002) `Networks of Innovation: Change and Meaning in the Age of the Internet' Oxford University Press, 2002
W3C (1992) 'World Wide Web' World Wide Web Consortium, 3 November 1992, at http://www.w3.org/History/19921103-hypertext/hypertext/WWW/TheProject.html
W3C (2000) 'A Little History of the World Wide Web', at http://www.w3.org/History.html
Wedeles L. (1966) 'Prof. Nelson TalkAnalyzes P.R.I.D.E.' Vassar Miscellany News February 3, 1965, at http://faculty.vassar.edu/mijoyce/MiscNews_Feb65.html
Worthington T. (1994) 'Hi-Tech Tourist on the European Information Highway and Recent Developments on the Global Information Infrastructure' TomW Communications Pty Ltd, July 1994, at http://www.tomw.net.au/hitech.html
Worthington T. (1998) 'Demonstration of the Australian Defence Web Home Page' Paper for Frontiers in Aerospace and Defence stream of SEARCC'98, 8 July 1998, at http://www.acs.org.au/president/1998/past/dodweb.htm
WVL (2008) 'History of the Virtual Library' WWW Virtual Library, updates to 2008, at http://vlib.org/admin/history
Zimmermann H. (1980) 'OSI Reference Model--The ISO Model of Architecture for Open Systems Interconnection' IEEE Transactions on Communications 28, 4 (Apr 1980) 425 - 432
Only a limited number of snapshots of the NCSA What's New pages have been located. This Appendix has drawn on Mosaic (1994), in order to extract announcements of Australian web-sites from 1 Jun 1993 to 31 May 1994, together with 2 prior entries and 1 interpolated entry drawn from other sources:
There appear to be very few publications that tell the story of the early years of the Web from the perspective of a particular country. But see Malone (2000) for 'Early Irish Web Stuff'.
In Australia, my own contributions to the emergence of the Web were minuscule, but I was one of the early beneficiaries of other people's efforts. The preparation of this paper has drawn on the published literature, but to a very considerable extent also on information contributed by many correspondents. Of particular value were contributions by Tony Barry (formerly Deputy Librarian at the ANU) and Matthew Ciolek (ANU College of Asia and the Pacific). I also acknowledge many contributions received in response to RFIs, and to RFCs relating to early drafts of this and the predecessor paper, particularly from within the link (Internet policy-watchers) community.
The reviewers and the editor of a Special Edition of the Journal of Information Technology, Frank Land, provided substantial comments which forced me to clarify and communicate the theoretical basis on which the narrative was developed, to the considerable benefit of the paper's quality.
Errors, omissions and imprecisions are inevitable in a work of this nature, and are of course mine alone, and readers are encouraged to draw problems with the text to my attention.
Roger Clarke is Principal of Xamax Consultancy Pty Ltd, Canberra. He is also a Visiting Professor in the Cyberspace Law & Policy Centre at the University of N.S.W., and a Visiting Professor in the Research School of Computer Science at the Australian National University.
| Personalia |
Photographs Presentations Videos |
Access Statistics |
 |
The content and infrastructure for these community service pages are provided by Roger Clarke through his consultancy company, Xamax. From the site's beginnings in August 1994 until February 2009, the infrastructure was provided by the Australian National University. During that time, the site accumulated close to 30 million hits. It passed 65 million in early 2021. Sponsored by the Gallery, Bunhybee Grasslands, the extended Clarke Family, Knights of the Spatchcock and their drummer |
Xamax Consultancy Pty Ltd ACN: 002 360 456 78 Sidaway St, Chapman ACT 2611 AUSTRALIA Tel: +61 2 6288 6916 |
Created: 18 April 2010 - Last Amended: 30 December 2012 by Roger Clarke - Site Last Verified: 15 February 2009
This document is at www.rogerclarke.com/II/OzWH.html
Mail to Webmaster - © Xamax Consultancy Pty Ltd, 1995-2022 - Privacy Policy
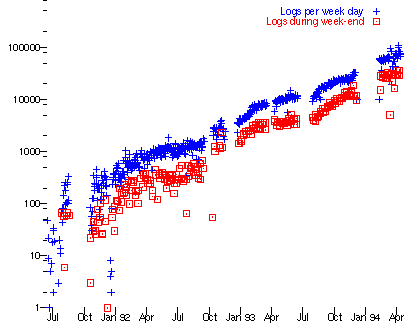{kind=link}