Roger Clarke's Web-Site
© Xamax Consultancy Pty Ltd, 1995-2024

Infrastructure
& Privacy
Matilda
Roger Clarke's Web-Site© Xamax Consultancy Pty Ltd, 1995-2024 |
|
|||||
| HOME | eBusiness |
Information Infrastructure |
Dataveillance & Privacy |
Identity Matters | Other Topics | |
| What's New |
Waltzing Matilda | Advanced Site-Search | ||||
Review Version of 19 December 2014
© Xamax Consultancy Pty Ltd, 2014
Available under an AEShareNet ![]() licence or a Creative
Commons
licence or a Creative
Commons  licence.
licence.
This document is at http://www.rogerclarke.com/EC/BDQF.html
The supporting slide-set is at http://www.rogerclarke.com/EC/BDQF.ppt and http://www.rogerclarke.com/EC/BDQF.pdf
The notion of 'big data' is examined, with reference to the quality of the data on which it is based, and the quality of the inferencing mechanisms applied to it. Significant deficiencies in quality assurance processes are identified, and antidotes proposed.
Proponents of 'big data' and 'big data analytics' proclaim a revolution. Meanwhile, corporate Board-rooms and government executives ask whether they are being offered vision or pie-in-the-sky.
This paper approaches the topic of 'big data' from the perspective of the sceptic rather than that of the enthusiast. It examines the extent to which decisions made on the basis of large-scale data collections are able to exhibit sufficient quality to be reliable. This in turn raises questions about the quality of the underlying data, and the reasonableness of merging or inter-relating data from disparate sources: "well-designed and highly functional [business intelligence] systems that include inaccurate and unreliable data will have only limited value, and can even adversely impact business performance" (Park et al. 2012).
In seeking an understanding of 'big data', clarity is needed about how it came to be. Disk-drive technology has continued its remarkable progress, to some extent in speed of access, but particularly in storage capacity. Meanwhile, the cost of solid-state storage has plummeted, resulting in the ready availability of affordable, small, robust, portable storage devices. One of the outcomes of these developments has been a change in the economics of data retention. Whereas there was once a financial incentive to destroy or at least archive old data, it has become cheaper to avoid the labour costs involved in evaluation, selection and deletion of data, by simply letting it accumulate.
A further enabler has been increasing capture of data at very low cost, with individuals initially conducting transactions directly with organisations' applications and more recently contributing social media postings. Organisations are also generating more data as a byproduct of business processes such as bar-code scanning and mobile-phone usage, through automated mechanisms such as toll-road monitoring and ticketing and payment schemes based on magnetic-stripes and chips, and through greatly increased use of sensors to conduct surveillance of relevant phsyical environments.
Common depictions of 'big data' are about excitement, not elucidation. All too typical of the genre is this effusive claim: "If the statistics ... say it is, that's good enough. No semantic or causal analysis is required. ... [M]assive amounts of data and applied mathematics replace every other tool that might be brought to bear. Out with every theory of human behavior, from linguistics to sociology. Forget taxonomy, ontology, and psychology. ... [F]aced with massive data, [the old] approach to science -- hypothesize, model, test -- is becoming obsolete. ... Petabytes allow us to say: 'Correlation is enough'" (Anderson 2008).
Consultants sponsoring the movement initially proposed that the key characteristics were 'volume, velocity and variety'. The earliest appearance of this frame appears to have been in Laney (2001). Subsequently, some commentators added 'value', while a few have recently begun to add a fifth, 'veracity', which appears to have originated with Schroeck et al. (2012). Such vague formulations even find their way into the academic literature, in the form of "data that's too big, too fast or too hard for existing tools to process". That theme pervades the definitions catalogued at OT (2013). The earliest usage of that expression is found by Google Scholar in a journal Editorial in mid-2012 (although Madden 2012 claims it as a "favorite", and neither as an original contribution nor even as being particularly helpful). The origins of Madden's expression may lie in populist garbling of "data whose size forces us to look beyond the tried-and-true methods that are prevalent at that time" (Jacobs 2009, p.44). Jacobs' depiction is appropriate within the field it was intended for - computer science research - but not in the applications arena. Another technologically-oriented definition links 'big data' to the use of massive parallelism on readily-available hardware.
A somewhat more useful characterisation for the purposes of business, government and policy analysis is "the capacity to analyse a variety of mostly unstructured data sets from sources as diverse as web logs, social media, mobile communications, sensors and financial transactions" (OECD 2013, p.12). This reflects the widespread use of the term to encompass not only data collections, but also the processes applied to those collections: "Big Data is ... scalable analytics" (Labrinidis & Jagadish 2012). To overcome this ambiguity of scope, this paper distinguishes between 'big data' and 'big data analytics'.
A broader view of 'big data' is as "a cultural, technological, and scholarly phenomenon that rests on the interplay of [three elements]" boyd & Crawford (2012, p.663). Their first two elements correspond to 'big data' and 'big data analytics'. Their third element, on the other hand, emphasises the importance of "mythology: the widespread belief that large data sets offer a higher form of intelligence and knowledge that can generate insights that were previously impossible, with the aura of truth, objectivity, and accuracy". One example of the myth-building endeavour is that practitioners are less commonly being labelled 'data analyst' and instead the saintly term 'data scientist' is in vogue.
The mythology, or as its proponents would prefer, the meme, has been spruiked in business school magazines (Lavalle 2012), by business school academics (McAfee & Brynjolfsson 2012), and by academics in other disciplines who might have been expected to temper their enthusiasm (Mayer-Schonberger & Cukier 2013). The high level of enthusiasm, coupled with these authors' willing suspension of disbelief, has given rise to counter-arguments, and to accusations such as "There's a mania around big data ..." (David Searls, quoted in Stilgherrian 2014a) and "Big data is an ideology" (Stilgherrian 2014b).
This paper tests the myth, meme, mania or ideology. It commences by defining terms relevant to the discussion. This is an intuitively foundational step in such a bold endeavour, yet one that the literature commonly shortchanges and even overlooks. The conceptual discussion provides a foundation for the analysis firstly of data quality and secondly of decision quality. The paper then unpacks the usage of the term 'big data' and categorises its applications. This enables an assessment of risks arising from it. These topics appear to be under-treated both in the academic literature and business practice. A framework for addressing the problems is proposed.
Various ontological and epistemological standpoints are possible. This analysis adopts a conventional perspective. It assumes the existence of a real world, consistent with ontological realism. It recognises that humans and their artefacts cannot directly capture that world but rather that they observe it in a filtered and selective manner, that they construct abstracted models of it, and that meaning is to a considerable extent imputed by the user of data (Clarke 1992b). Its epistemology therefore embraces empiricism, but sits between positivism and anti-positivism, or perhaps adopts a post-positivist view (Hirschheim 1985). From this perspective, a workable set of definitions can be proposed.
Data is any symbol, sign or measure accessible to a person or an artefact (Clarke 1992a). Two sub-categories need to be distinguished:
When data is gathered, it is measured against a scale:
The vast majority of real-world phenomena do not give rise to empirical data. For example, the variations in electromagnetic phenomena streaming across the universe are largely ignored, although recently a little of it has been sampled. Acts of data collection involve more or less conscious intent. The selection of what data is collected, how and when, reflects the collector's perceived purpose.
Data, may be compressed at the time it is captured, in particular through sampling, averaging and filtering of outliers. This is common where the data collected is voluminous. It occurs, for example, with data collected by environmental sensors, which may generate numbers on a sub-second cycle. The compression process embodies judgements, e.g. about the criteria for recognising outliers and the period over which to compute an average. These again generally reflect the perceived purpose for which the data is being collected.
A useful generic term for real-world phenomena such as computing devices, vehicles and animals is 'entities'. Many kinds of entities present differently in different contexts, e.g. a computing device runs multiple processes, and a human being has many identities, in work, home and play contexts. Attributes of (id)entities are represented by data-items. A record is associated with an (id)entity by means of an (id)entifier, which comprises one or more data-items that distinguish that particular (id)entity from others in the same category (Clarke 2009).
The data-items that relate to a particular (id)entity are commonly gathered into a 'record'. The impression of a real-world (id)entity that is contained in a record is usefully referred to as a 'digital persona' (Clarke 1994a, 2014a).
A set of like records is gathered into a 'data-file'. The more recent term 'database' encompasses complexes in which the data about each real-world (id)entity is distributed across a range of records, but in a sufficiently coordinated manner that a digital persona can be extracted whenever it is needed. For the purposes of this analysis, the term 'data collection' is used generically, to encompass both files and databases. Conceptually, a data collection can be regarded as a two-dimensional table, with each row describing some (id)entity in the real world - or at least purporting to do so, and each column containing data that represents a particular attribute of each of those (id)entities.
This leads to a further set of distinctions that is relevant to the analysis in this paper. This is among:
Data may in principle be converted among these forms, and in particular may be rendered anonymous by removing all (id)entifiers from it. In practice, however, in any rich data-collection, many records are vulnerable to re-identification procedures (Sweeney 2002, Acquisti & Gross 2009, Ohm 2010).
The term 'information' is used in many ways. Here it is quite specifically defined as data that has value. Informational value depends upon context. Until it is placed in an appropriate context, data is not information, and once it ceases to be in that context it ceases to be information (Clarke 1992a). The most common manner in which data can have value, and thereby become information, is by making a difference to a decision, which is a choice among alternative courses of action. Decision-making commonly involves both some degree of structuredness of process and data selection and some degree of political inter-play among actors.
Remarkably, these longstanding insights into information systems keep getting lost and have to be frequently rediscovered. For example, Marchand & Peppard (2013) criticise what they depict as being conventional thinking that information is "a resource that resides in databases" (which corresponds to 'data' as defined above), and recommend an approach that "sees information as something that people themselves make valuable" (p.106 - i.e. 'information' as defined above).
The term 'knowledge' is also subject to many interpretations, most of them naively assuming that it is merely a refinement of data. Under the approach adopted here, it refers to the matrix of impressions within which an individual situates newly acquired information (Clarke 1992b).
The notion of 'wisdom', meanwhile, is on an entirely different plane from data, information and even knowledge, because it involves judgements that resolve conflicting values, and that are exercised by devising and applying decision criteria to existing knowledge combined with new information.
Proponents of big data commonly co-opt the terms 'information' and 'knowledge' in order to imply that big data techniques, including 'machine learning', somehow produce outputs that are much more than mere 'data'. The definitions proposed above deny the claim that outputs from analytical techniques can reach directly into a human's internal matrix of impressions, still less that algorithms, rules or neural networks can exercise value judgements on behalf of individuals, groups and societies.
The set of definitions presented in this section is justified by its usefulness as a basis for examining questions such as 'what is big data?', and 'how effective is, and can be, big data analytics in supporting decision-making?'. The definitions are subject to attack from positivists for being too relativist. Little accommodation of positivist notions is attempted in this paper.
On the other hand, the definitions could be criticised from other perspectives for being too structured, mechanistic or simplistic. A summation of that view is found in Roszak (1986, pp.87,95,98,118,120,186-7): "[Data, even today], is no more than it has ever been: discrete little bundles of fact, sometimes useful, sometimes trivial, and never the substance of thought [and knowledge] ... The data processing model of thought ... coarsens subtle distinctions in the anatomy of mind ... Experience ... is more like a stew than a filing system ... Every piece of software has some repertory of basic assumptions, values, limitations embedded within it ... [For example], the vice of the spreadsheet is that its neat, mathematical facade, its rigorous logic, its profusion of numbers, may blind its user to the unexamined ideas and omissions that govern the calculations ... garbage in - gospel out. What we confront in the burgeoning surveillance machinery of our society is not a value-neutral technological process ... It is, rather, the social vision of the Utilitarian philosophers at last fully realized in the computer. It yields a world without shadows, secrets or mysteries, where everything has become a naked quantity".
The notion of data quality relates to the fitness of data for its intended purpose. In order to provide an appropriate foundation for analysis, a sufficiently comprehensive set of data quality factors is needed. The list in Table 1 reflects sources in the information systems and related literatures, including OECD (1980), Huh et al. (1990), van der Pijl (1994), Clarke (1995b, pp. 601-605), Wang & Strong (1996), Müller & Freytag (2003. pp. 8-10), English (2006), Piprani & Ernst (2008) and the ISO 8000 series emergent since 2009. In the terms of Wang & Strong (1996), the focus in this section is on 'intrinsic' and 'contextual' factors. More detailed analysis of these data quality attributes can be conducted in respect of particular categories of data. For example, Buckley (1997, pp.11-15) presents greater detail in respect of geographical data.
The term 'data integrity' reflects the tendency of data quality to deteriorate. The deterioration may result from a variety of causes, including degradation of the storage medium, changes arising from inappropriate processing, the efflux of time, and the loss of associated data. The notion of 'digital data curation' has emerged to refer to measures to sustain data integrity (Rusbridge et al. 2005). However, 'curation' requires that quality assurance processes be applied, to each data-item recorded for each (id)entity, at the time of collection, and throughout each data-item's life. For example:
An often-overlooked aspect of data quality is the handling of null values. In some contexts, a data-item is mandatory and an absence of content is invalid. In many circumstances, however, a data-item may be inapplicable, or the item may not have been collected. In occasional situations, absence of content is meaningful, as in the absence of a father's name on a 19th century birth entry.
It is expensive both to achieve a high level of data quality at the time of collection, and to sustain data integrity through its lifetime. It is therefore normal for organisations that collect, store and use data to compromise quality by trading it off against cost. As a consequence, inappropriate uses of data can only be avoided if information is available about the data's original and current quality, and about the quality assurance processes that have and have not been applied.
Data may have value to a person or organisation, and thereby become information, in a variety of contexts. For example, it may assist in the modelling of a particular problem-domain. The context of use most relevant to this paper is decision-making. This is partly because it is a very common context of use for data, but particularly because the impacts of data quality are direct. In addition to the intrinsic and contextual quality of data discussed above, three further factors are important determinants of decision-quality. These are the relevance of the data used, the meaning that is imputed to it, and the transparency of the decision mechanism.
Data is relevant to a decision if it can be shown that, depending on whether the data is or is not available to the decision-maker, a different outcome could result (Clarke 1995b, p. 600). The first test is whether a data-item could, in principle, be relevant to that category of decision. The second test is whether the value that the data-item adopts in a particular context is, in practice, relevant to the particular decision being made. If data fails either of the relevance tests, any use of it in the decision process is likely to result in inappropriate decisions with the potential for harmful outcomes.
The intrinsic and contextual data quality factors discussed in the previous section then come into play. Data is collected for a purpose, and the data's accuracy, precision, timeliness and completeness reflect that purpose. For this reason, international standards limit the use of data to "the fulfilment of those purposes or such others as are not incompatible with those purposes" (the Purpose Specification Principle, OECD 1980), or to specified, explicit and legitimate purposes, with limitations placed on further uses "in a way incompatible with those purposes" (part of the Data Quality Principle, and commonly referred to as 'the finality principle', EU 1995).
Within a positivist framework, each data-item should be capable of having, and should have, a clear definition of its meaning, of the domain on which it is defined, and of the meaning of each of the values in that domain including the absence of a value (Clarke 1995b, pp. 598-600). In practice, however, the meaning of a great many data-items in a great many data-collections:
From the interpretivist perspective, the strict positivist view of data is naive, because the meaning of data is subject to interpretation by its users. Inappropriate interpretations are, however, very likely where data quality is low, provenance is unclear, definitions are lacking, or context is inadequate.
Consolidation of data from multiple sources magnifies the issues arising in relation to the meaning of data. The greatest dangers arise not from unusual data-items, but in respect of widely used but subtly different data-items. There are many variations in the meaning of apparently similar data-items in different data collections, such as spouse, child and income. For example, a data-item may be defined by the legislation under which a government agency or an agency program operates, and this may be materially different from common usage of the term, and from usages in other data collections within the same agency, and in other agencies and corporations.
Incompatibilities among data definitions can be addressed through harmonisation and standardisation processes. For example, EDI and eCommerce communities have tried to establish common glossaries. Further, because of the high percentage of errors arising from government data matching programs, attempts have been made to achieve a greater degree of correspondence among the definitions of terms such as the many aspects of income (Clarke 1995b, pp.599-600). Such initiatives have encountered considerable difficulties, however. In any case, they represent compromise of the primary objectives of each business line and each government program, in order to serve a secondary purpose.
For an individual or organisation to take responsibility for a decision, they need to be able to understand how the decision mechanism worked, and how it was applied to which data in order to reach that decision. The extent to which this understanding can be achieved varies, depending on the manner in which computing is applied. Six generations of application software production can be distinguished (Clarke 1991, 2014b). The first two (low-level 'machine language') generations are not relevant to the present discussion. The key characteristics of the later four, more abstract generations are summarised in Table 2.
Generation | 3 | 4 | 5 | 6 |
Type
| Algorithmic /
Procedural 'Programming Languages' | Declarative Languages ('4GLs') | Descriptive 'Expert Systems' (commonly rule-based) | Facilitative (summation of empirical evidence, e.g. neural networks) |
Model of the Problem-Domain | Implicit | Implicit | Explicit | Implicit |
Model of the Problem | Implicit | Explicit | None | None |
Model of the Solution | Explicit | Explicit (Pre-Defined)
| Implicit, as Data | None |
Process Transparency | Explicit | Explicit | Explicit Rules but Implicit Handling of Conflicts among Rules | Implicit (Comparison of a new instance with accumulated evidence) |
Decision Criteria Transparency | Explicit or at least Extractable | Explicit or at least Extractable | Implicit, and possibly Unextractable | None |
When applying the later (higher-numbered) generations of software production, "the decision, and perhaps action, has been delegated to a machine, and the machine's rationale is inscrutable. Even with 3rd generation software, the complexity of the explicit problem-definition and solution-statement can be such that the provision of an explanation to, for example, corporate executives, can be very challenging. The 4th, 5th and 6th generations involve successively more substantial abandonment of human intelligence, and dependence on the machine as decision-maker" (Clarke 2014b, p.250).
Concerns about the loss of transparency and of human control over decision-making have been expressed by a variety of authors both generally (Roszak 1986, Dreyfus 1992, boyd & Crawford 2012) and specifically, for example in the context of the law (Bennett Moses & Chan 2014).
The preceding analysis provides the basis for consideration of data and decision quality factors in the 'big data' arena.
In the Introduction, it was noted that definitions of the term 'big data' are varied, and are generally very loose. This section identifies the characteristics that are key to understanding its nature. It is first necessary to make a distinction that is commonly glossed over not only in business magazines, but also in formal literatures. Several kinds of data collection may qualify as 'big data'. These are:
Conceptually, the result of data consolidation is a very large two-dimensional table, with each row describing some (id)entity in the real world (or at least purporting to do so), and each column containing data that represents a particular attribute of each of those (id)entities. In practice, the table may be vast, and may not be actually constructed and stored in that form. Instead, the same effect may be achieved more efficiently by establishing linkages among multiple files, and depending on software to process the data as though the table existed.
The following sections consider in term several predecessor terms, the increasing prominence of longitudinal data collections, data scrubbing or cleansing, the application of analytical tools to 'big data' collections, and the functions that 'big data analytics' can be used to perform.
One early form of data consolidation was 'data warehousing'. This notion was a response to a problem common in the 1980s, whereby organisations had multiple data collections that were largely independent from one another (Inmon 1992, Kimball 1996). This could result in operational impediments, e.g. as a result of inconsistencies between two sources of data used for management planning and control decisions. It created even more serious difficulties for the conduct of analysis in support of strategic decision-making by executives. Data warehousing involves the extraction of data from two or more collections, and storage in a separate data collection. This enables analysts to manipulate the data structures and content without disrupting the underlying operational systems. Hence a data warehouse was "a subject oriented, nonvolatile, integrated, time variant collection of data in support of management's decisions" (Inmon 1992), or "a copy of transaction data specifically structured for query and analysis" (Jacobs 2010).
Whereas data warehousing was prevalent in the private sector, a technique called 'computer matching' or 'data matching' came into widespread use in government agencies. Computer matching is the comparison of machine-readable records containing data relating to many entities, in order to detect cases of interest. In most data matching programs, the category of entities that is targeted is human beings (Clarke 1994b, 1995a). Empirical research established that most matching programs were conducted with little or no regard for the quality of the data being matched, even though considerable evidence existed demonstrating that data quality was low, and that matching processes compounded errors rather than reducing them (Clarke 1995b).
Meanwhile, a naive 'databanks' movement that was prevalent during the 1960s (Clarke 1988) is currently enjoying a revival. The original initiatives foundered on the inadequacies of the technologies of the time, exacerbated by public disquiet. A new generation of public servants and technology providers is hard at work, seeking to develop a data collection, perhaps physically centralised but more likely virtual, containing most or all data that national governments hold about the people resident in the country. This approach is predicated on the restriction of every resident to a single identifier that must be used in all dealings with government, or on an effective means of linking the multiple identities that individuals have and that are associated with their multiple identifiers (Clarke 2006). Denmark has to a considerable degree achieved this aim (Pedersen et al. 2006), and countries as diverse as Estonia and Malaysia continue their developments (Economist 2014).
A key difference between the 1960s 'national databank' and the 2010s conception of the 'virtual national databank' is that vastly more data is available than was the case a half-century earlier. A great deal of that data is generated from frequent transactions that had previously been unrecorded, such as anonymous payments and anonymous use of public transport and roads. The data collections that are available to be plundered are no longer limited to government sources but also include very substantial corporate collections.
One of drivers of the 'big data' movement has been the collection of "repeated observations over time and/or space" (Jacobs 2009, p.40). The scale problem can be explained as the expansion of the conceptual table referred to earlier from two dimensions to three. The observations may be repeated very frequently, as occurs in millisecond timeframes in telemetry. Even communications between mobile phones and cell-towers occur in sub-second timeframes. In such circumstances, the depth and intensity of the third, longitudinal dimension (storing successive values over time) is far greater than the counts of rows (representing the (id)entities) or of columns (representing attributes of the (id)entities).
Considerable challenges arise from data consolidation, because of a variety of differences among the sources of data. In an endeavour to cope with this, the further notion of 'data scrubbing' arose. This is a process whereby data quality problems are identified or inferred, and changes are made in accordance with some form of business rule (Rahm & Do 2000). The alternative terms 'data cleansing' and 'data cleaning' are currently more popular. These more positive terms are only justifiable, however, if the process is effective.
The preceding sections have identified a range of quality problems that arise in the individual collections and from collection consolidation. These include poor accuracy, precision, timeliness and completeness, but also problems with data definitions, valid contents, and the definition of each value that the item may contain. Where two or more data-collections have been, or are to be, consolidated, some of these quality problems result in failure to match corresponding records, or in mistaken matching of two records that contains data about unrelated entities. A further critical challenge is the appropriate handling of missing data. A null value is of course valid in some circumstances, but not in others. Where a data scrubbing process interpolates a value for a data-item, assumptions are made, whether explicitly or by implication.
In principle, a range of approaches can be adopted to detecting data quality problems, and to changing data-items in order to rectify them:
Müller & Freytag (2003) refined previous models into a four-step process comprising data audit, workflow specification, workflow execution and post-processing / control. The authors' process description includes manual inspection by a `domain expert' (p. 12). However, the costs of manual processes are vastly higher than is the case with automated methods, and the scale of the data, of the data diversity, and hence of the instances that would in principle benefit from manual assessment is such that it is inevitable that very little manual intervention will occur.
The quality problems that the specific methods address are mostly syntactic. Remarkably, the existing literature includes few mentions of gathering the schema definitions for the original data-sources. Instead, definitions are inferred from the collection or the consolidation of collections. Moroever, the approaches focussed on are almost entirely internal cross-checking within available data, and rely on syntax-`repair' and statistical imputation.
The steps of identifying data quality problems and then solving them are seriously problematic, because it is seldom feasible to define processing algorithms or rules that are always correct. The process therefore inevitably gives rise to both false-positives (imaginary problems resulting in inappropriate changes) and false-negatives (problems that are not identified and not addressed).
In some circumstances, the trade-off may be, on the whole, highly beneficial, e.g. where physical addresses are compared with a reliable cadastral database, and spellings amended and current postal codes added. Even in the case of geo-coding, however, multiple schemes exist, and mappings among them are problematical. In other circumstances, such as attempts to correct mis-spelt or incomplete names and to reconcile inconsistencies among entries that appear to relate to the same entity, the absence of an authoritative data collection that can be used as a reference-point gives rise to outcomes of uncertain quality, but sometimes of very low quality.
As indicated earlier, the term 'big data' is commonly used to encompass not only data collections, but also the processes applied to those collections. An earlier term, used to refer to the processing of the contents of 'data warehouses', was 'data mining' (Fayyad et al. 1996, Ratner 2003, Ngai et al. 2009, Hall et al. 2009).
The term 'data analytics' has been used in technical disciplines for many years. It quickly became a mainstream term in the management field following Davenport (2006). An upbeat, commercial definition of 'big data analytics' is as follows: "two technical entities have come together. First, there's big data for massive amounts of detailed information. Second, there's advanced analytics, which is actually a collection of different tool types, including those based on predictive analytics, data mining, statistics, artificial intelligence, natural language processing, and so on. Put them together and you get big data analytics" (Russom 2011, p.6). It seems apt that the (fictional) inventor of the first robot in 1918/1921 was Rossum (Capek 1923).
A very substantial array of analytical tools exists, and more are being developed. To some extent, the term 'data mining' has been superseded by 'data analytics', although some writers use it to refer to a sub-set of the full range of mathematical and statistical approaches. Chen et al. (2012) use the term 'Business Intelligence and Analytics (BI&A)', and distinguish two phases to date. BI&A 1.0 was characterised by "data management and warehousing, reporting, dashboards, ad hoc query, search-based BI, [online analytical processing (OLAP)], interactive visualization, scorecards, predictive modeling, and data mining" (p. 1166). BIA 2.0, since the early 2000s, is associated with web and social media analytics, including sentiment analysis, and associated-rule and graph mining. Much of this work is dependent on semantic web notions and text analysis tools (pp. 1167-68). The authors anticipate the emergence of BIA 3.0, to cope with mobile and sensor-generated data.
Figure 1 provides a diagrammatic overview of the business processes and data-collections evident in the field of 'big data'.
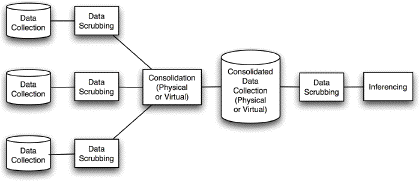
The over-excited business and other populist literatures present a vast array of applications of 'big data', across areas as diverse as marketing, mineral search, and public health. An assessment of quality factors is not well-served by listing applications based on business sectors. Table 3 proposes instead a set of categories that distinguishes the function that data analytics is being used to perform.
The quality of the inferences arising from big data analytics depends on a variety of factors, including:
To the extent that shortfalls in quality exist, and the inferences are used as the basis for actions, risks arise to the parties involved.
Some inferences from 'big data' are of the nature of 'ideas to be investigated'. There is no doubt that interesting and in some cases valuable information can be teased out of large data-sets. However, the correlations are usually of a low grade, and involve large numbers of confounding and intervening variables. Moreover, key variables may be missing from the model. More fundamentally, the inferencing techniques discover correlations, but seldom causality. This underlines a major problem with contemporary conventions. In complex systems, the notion of causality is an inappropriate concept to apply. This is because outcomes arise in circumstances that comprise a constellation of factors, none of which can be meaningfully isolated as 'the cause', or 'the proximate cause', or even 'a primary cause'. Models developed within the framework of general systems theory have a place for influence, but not for the naive concept of causality.
The uncertain quality of data and of decision processes leads to the inevitable conclusion that many inferences from 'big data' are currently being accorded greater credibility than they actually warrant. Inaccurate or unreasonable inferences will tend to result in resource misallocation - with consequential negative impacts on return on investment or public policy outcomes. In some cases, there will also be unjustified discrimination against particular population segments.
Trust and security issues also arise. Where the data identifies people, the re-purposing of data is already a breach of privacy expectations. Data consolidation involves a further breach, because the data is not merely applied to purposes outside the realm in which it was collected, but is also commonly disclosed to one or more further parties. Yet worse, the proliferation of copies of the data increases the risk of further disclosures, and consolidated data collections represent 'honey-pots' that attract more attempts to gain access to them, by more technically capable people.
Where the function being performed is population inferencing or profile construction, as distinct from inferencing about individuals, it is highly advisable for the data to be anonymised - and indeed the law of a relevant jurisdiction may require it. Unfortunately, in rich data collections it is often feasible for a significant proportion of the records involved to be able to be later re-identified, and hence the protection may be illusory. Some guidance is available about the critical techniques of deletion of specific rows and columns, generalisation or suppression of particular values and value-ranges, and data falsification (sometimes referred to using the polite euphemism 'data perturbation') - including micro-aggregation, swapping, adding noise and randomisation (UKICO 2012. See also Slee 2011, DHHS 2012). Depending on how data falsification is done, it may have a significant negative impact on the utility of the data not only for inferences about individuals, but also for population inferencing; but this remains an active area of research.
Where the inferences, decisions and actions relate to individuals rather than populations or population-segments, risks arise to the people that the data relates or is thought to relate to. A common application of data matching has been fraud control, and it is only to be expected that techniques from the 'data analytics' tool-set will be used for such purposes. Inaccurate or unreasonable inferences about individuals result in costs to them, and in some cases signficant harm, particularly where the process is hidden or mysterious, and hence unchallengeable and uncorrectable.
Profiling involves searching for (id)entities whose digital persona exhibits a close fit to "a predetermined characterisation or model of infraction" (Marx & Reichman, 1984, p.429). These 'models of infraction' are often obscure, and may even be counter-intuitive (Clarke 1993). Another depiction of these approaches to isolating suspects is that they depend on 'probabilistic cause' rather than 'probable cause' (Bollier 2010, pp.33-34, referring to Marc Rotenberg). Considerable concerns have been expressed about the implications for individuals of the application of abstract profiles to big data (boyd & Crawford 2012, Croll 2012, Oboler et al. 2012, Wigan & Clarke 2013). The level of concern also depends on such factors as the sensitivity of the data, its intensity, and the extent to which it creates vulnerabilities for the individual. Some data collections represent a witch's brew of not merely demographic, psychographic and sociographic data about individuals, but also social network, experiential and geo-locational data.
In short, the concerns identified in this paper about data quality and decision quality in the context of 'big data' are not merely of academic interest, but have substantial implications for decision-makers at both managerial and executive levels, and for policy-makers. The impacts, and which actors suffer the consequences, will vary considerably, depending on such factors as which of the functions identified in Table 3 is being performed, the sector, the nature and quality of the data, and the nature of the (id)entities that the data represents.
Literature searches were conducted, in order to find prior work in this area, particularly within venues likely to be read by researchers and practitioners in 'big data'. Searches on variations of terms such as big data, data analytics, data quality, assurance, method and process identified multiple vacuous statements along the lines of 'data quality can be a problem', but very few sources that actually address the key questions of what the level of data quality is in 'big data', how it can be assessed, and what can be done about it.
During the predecessor, data mining era, one contribution was the notion of Data Quality Mining (DQM): "the deliberate application of data mining techniques for the purpose of data quality measurement and improvement. The goal of DQM is to detect, quantify, explain, and correct data quality deficiencies in very large databases" (Hipp et al. 2001). However, this aspiration was undermined by the unrealistic assumptions that "deficiencies occur only exceptional [sic] and that not the whole database is cluttered with noise". The DQM concept also focussed entirely on analysis within the data collection, without any external reference-point against which data quality could be assessed. This resulted in the notion of quality being reduced from the substantial set of factors identified in the sections above to mere internal consistency within the data collection (Luebbers et al. 2003, Brizan & Tansel 2006). Hipp et al. (2007) adopted "an approach that automatically derives the rules from the data itself", which had the effect of reducing the concept of 'accuracy' to the rule 'an outlier is inaccurate and anything else is accurate'.
The leading professional group in the area is the Association for Computing Machinery's Special Interest Group on Knowledge Discovery and Data Mining (ACM SIGKDD). Its curriculum proposal for a 2-unit course of study in data mining contained nothing about data quality and nothing about quality assurance, and the small amount about the selection of appropriate inferencing methods was swamped by the wide array of complex procedures (KDD 2006). Scans of the Proceedings of SIGKDD's premier event and of its Explorations Newsletter identified very few papers, workshops or tutorial sessions whose focus was on data or decision quality, or indeed on processes that might contribute to quality assurance.
Even balanced works like Bollier (2010) lack any attention to, and even any mention of, the term or even the concept. A popular aphorism in the area is "'bad data' is good for you", attributed to Jeff Jonas (Bollier 2010, p.13). But Jonas' proposition is not actually about data quality. Its focus is on data whose implications do not fit with the analyst's present precepts or judgements, and hence challenge them, and, in the original sense 'prove the rule'. Rather than being a new insight, however, this is a standard principle of logic and of scientific method.
Typical of the the few papers that touch on these topics is Fan & Bifet (2012) which identifies accuracy as being "controversial", but fails to address it. Giraud-Carrier & Dunham (2012) bemoan the absence of a tradition in computer science generally, and in this field specifically, of sharing negative results. Of seven articles in a Special Section of a leading information systems journal in December 2012 (MISQ 36, 4), most contained no mention whatsoever of data and decision quality issues and only one actually addressed any aspect of them. Mayer-Schonberger & Cukier (2013), meanwhile, merely hints at issues, and is clearly designed to enthuse readers rather than to encourage them to adopt a view tempered by an understanding of quality issues.
The literature on appropriate business processes for acquiring and consolidating big data, and applying big data analytics, is still not yet well-developed. Such process guidance as exists merely addresses internal consistency checks, overlooking intrinsic and contextual data quality, and omitting controls and audit (e.g. Guo 2013). Similarly, Marchand & Peppard (2013) propose five process guidelines, but they omit any meaningful consideration of the quality of the data and of the decision processes applied to it.
One of the few areas in which a significant literature appears to exist is in coping with 'variety' or 'heterogeneity' of data and inconsistencies among sources (Zhang 2013), but even the emergent focus on 'veracity' remains trapped within what Saha & Srivastava (2014) call 'logical data quality', i.e. mere internal consistency. A very recent article, Jagadish et al. (2014) mentions heterogenity, incompleteness and provenance (pp. 90-92), and notes that "a decision-maker has to examine critically the many assumptions at multiple stages of analysis" (p.90). However, the discussion's preliminary and general nature underlines the absence of insight into quality issues, and of an appreciation of the critical need for quality assurance measures.
The `veracity' theme was conceived by Schroek et al. (2012) as "Data uncertainty - Managing the reliability and predictability of inherently imprecise data types" (p. 4). Apart from being a very limited conception (precision rather than the full gamut of data quality factors), the authors merely `acknowledge' it as a constraint, and sustain the hype surrounding the big data movement, by "embracing" it. Veracity's frequent mention as a fourth (or sometimes fifth) element of big data is wafer-thin, and it has been overdue for serious analysis.
This call to arms recently appeared in a journal Editorial: "Big Data's success is inevitably linked to ... clear rules regarding data quality. ... High quality data requires data to be consistent regarding time ..., content ..., meaning ... , and data that allow for unique identifiability ... , as well as being complete, comprehensible, and reliable (Buhl & Heidemann 2013, pp. 66-67). To date, however, that call has been largely ignored. There remains a remarkable paucity of discussion of data quality and decision quality in the 'big data' literature. To the extent that such topics have been addressed, the treatment has been limited to those aspects of data quality that are amenable to automated analysis and amendment, through operations within the data collection itself.
The analysis presented in this paper leads to a number of conclusions:
The research community has a responsibility to counterbalance the breathless excitement about 'big data', by undertaking analyses of quality and quality assurance measures, and by providing guidance on how to detect and address poor data quality, and avoid low-quality inferencing and consequential negative impacts. Already, disciplines that observe 'big data' rather than practise it are publishing highly critical commentaries (e.g. boyd & Crawford 2012, Waterman & Bruening 2014, Greenleaf 2014, Bennett Moses & Chan 2014). Unless the disciplines that champion 'big data' and 'big data analytics' address the deficiencies that have been identified, critical commentaries are likely to have the effect of undermining the entire endeavour.
Exciting though business strategy may be, corporate Boards and their equivalents in government agencies, and chief executives, have governance responsibilities, which they satisfy by ensuring the conduct of risk assessment and risk management processes, as described in the ISO 31000 (generic) and 27000 (information-specific) families of process standards.
At the management level, risk management is operationalised as quality assurance processes. The ISO 9000 series of process standards is too vague to provide guidance in this area. An ISO 8000 series is intended to address data quality, but has languished. It is, moreover, rooted in positivist thinking and hence its scope is limited to the mechanistic aspects of data management (Benson 2009). "ISO 8000 simply requires that the data elements and coded values be explicitly defined. ... ISO 8000 is a method that seeks to keep the metadata and the data in sync ... ISO 8000 provides guidance on how to track the source of data, this is called provenance" (Benson 2014). This is helpful as far as it goes, but it falls far short of providing adequate guidance to organisations considering the use of 'big data'.
Table 4 draws on the analysis conducted above, in order to propose a framework within which organisations can work to extract value from 'big data', while managing the risks. It is predicated on the assumption that the organisation already has a sufficiently mature governance framework, encompassing risk assessment, risk management and quality assurance - in the absence of which directors and executives need to pause and reconsider before adopting big data techniques.
This paper has drawn on existing insights into quality factors in data and decision-making, extracted the key characteristics of the 'big data' movement, identified and analysed the problems, and proposed a framework within which the problems can be addressed. The 'big data' movement is beset with a vast array of challenges. The academic literature in the area has failed to adequately reflect and analyse those challenges, and has in effect been a contributor to the problem, rather than to the solution. Organisations are at serious risk of assuming that 'big data' and 'big data analytics' are of strategic significance, without appreciating the challenges, and without access to guidance as to how to address those challenges.
Acquisti A. & Gross R. (2009) `Predicting Social Security Numbers from Public Data' Proc. National Academy of Science 106, 27 (2009) 10975-10980
Anderson C. (2008) 'The End of Theory: The Data Deluge Makes the Scientific Method Obsolete' Wired Magazine 16:07, 23 June 2008, at http://archive.wired.com/science/discoveries/magazine/16-07/pb_theory
Bennett Moses L. & Chan J. (2014) `Using Big Data for Legal and Law Enforcement Decisions: Testing the New Tools' UNSW L. J. 37, 2 (September 2014), Special Issue on Communications, Surveillance, Big Data and the Law, at http://www.unswlawjournal.unsw.edu.au/issue/volume-37-no-2
Benson P.R. (2009) 'Meeting the ISO 8000 Requirements for Quality Data' Proc. MIT Information Quality Industry Symposium, July 2009, at http://mitiq.mit.edu/IQIS/Documents/CDOIQS_200977/Papers/01_05_T2C.pdf
Benson P.R. (2014) 'ISO 8000 Update - Peter Benson Interview' Data Quality Pro, July 2014, at http://dataqualitypro.com/data-quality-pro-blog/iso8000-peter-benson-update
Bollier D. (2010) 'The Promise and Peril of Big Data' The Aspen Institute, 2010, at http://www.ilmresource.com/collateral/analyst-reports/10334-ar-promise-peril-of-big-data.pdf
boyd D. & Crawford K. (2012) 'Critical Questions for Big Data' Information, Communication & Society, 15, 5 (June 2012) 662-679, DOI: 10.1080/1369118X.2012.678878, at http://www.tandfonline.com/doi/abs/10.1080/1369118X.2012.678878#.U_0X7kaLA4M
Brizan D.G. & Tansel A.U. (2006) 'A Survey of Entity Resolution and Record Linkage Methodologies' Communications of the IIMA 6, 3 (2006), at http://www.iima.org/CIIMA/8%20CIIMA%206-3%2041-50%20%20Brizan.pdf
Buckley G. (1997) 'Introduction to GIS' BioDiversity GIS, 1997, at http://www.innovativegis.com/basis/primer/primer.html
Buhl H.U. & Heidemann J. (2013) `Big Data: A Fashionable Topic with(out) Sustainable Relevance for Research and Practice?' Editorial, Business & Information Systems Engineering 2 (2013) 65-69, at http://www.bise-journal-archive.org/pdf/01_editorial_36315.pdf
Capek K. (1923) `R.U.R (Rossum's Universal Robots)' Doubleday Page and Company, 1923
Chen H., Chiang R.H.L. & Storey V.C. (2012) 'Business Intelligence and Analytics: From Big Data to Big Impact' MIS Quarterly 36, 4 (December 2012) 1165-1188, at http://ai.arizona.edu/mis510/other/MISQ%2520BI%2520Special%2520Issue%2520Introduction%2520Chen-Chiang-Storey%2520December%25202012.pdf
Clarke R. (1988) 'Information Technology and Dataveillance' Comm. ACM 31,5 (May 1988), PrePrint at http://www.rogerclarke.com/DV/CACM88.html
Clarke R. (1991) 'A Contingency Approach to the Software Generations' Database 22, 3 (Summer 1991) 23 - 34, PrePrint at http://www.rogerclarke.com/SOS/SwareGenns.html
Clarke R. (1992a) 'Fundamentals of 'Information Systems' Xamax Consultancy Pty Ltd, September 1992, at http://www.rogerclarke.com/SOS/ISFundas.html
Clarke R. (1992b) 'Knowledge' Xamax Consultancy Pty Ltd, September 1992, at http://www.rogerclarke.com/SOS/Know.html
Clarke R. (1993) 'Profiling: A Hidden Challenge to the Regulation of Data Surveillance' Journal of Law and Information Science 4,2 (December 1993), PrePrint at http://www.rogerclarke.com/DV/PaperProfiling.html
Clarke R. (1994a) 'The Digital Persona and its Application to Data Surveillance' The Information Society 10,2 (June 1994) 77-92, PrePrint at http://www.rogerclarke.com/DV/DigPersona.html
Clarke R. (1994b) 'Dataveillance by Governments: The Technique of Computer Matching' Info. Technology & People, 7,2 (June 1994), PrePrint at http://www.rogerclarke.com/DV/MatchIntro.html
Clarke R. (1995a) 'Computer Matching by Government Agencies: The Failure of Cost/Benefit Analysis as a Control Mechanism' Information Infrastructure & Policy 4,1 (March 1995), PrePrint at http://www.rogerclarke.com/DV/MatchCBA.html
Clarke R. (1995b) 'A Normative Regulatory Framework for Computer Matching' J. of Computer & Info. L. 13,3 (June 1995), PrePrint at http://www.rogerclarke.com/DV/MatchFrame.html
Clarke R. (2006) 'National Identity Schemes - The Elements' Xamax Consultancy Pty Ltd, February 2006, at http://www.rogerclarke.com/DV/NatIDSchemeElms.html
Clarke R. (2009) 'A Sufficiently Rich Model of (Id)entity, Authentication and Authorisation' Proc. IDIS 2009 - The 2nd Multidisciplinary Workshop on Identity in the Information Society, LSE, London, 5 June 2009, PrePrint at http://www.rogerclarke.com/ID/IdModel-1002.html
Clarke R. (2014a) 'Promise Unfulfilled: The Digital Persona Concept, Two Decades Later' Information Technology & People 27, 2 (Jun 2014) 182 - 207, PrePrint at http://www.rogerclarke.com/ID/DP12.html
Clarke R. (2014b) 'What Drones Inherit from Their Ancestors' Computer Law & Security Review 30, 3 (June 2014) 247-262, PrePrint at http://www.rogerclarke.com/SOS/Drones-I.html
Croll A. (2012) 'Big data is our generation's civil rights issue, and we don't know it: What the data is must be linked to how it can be used' O'Reilly Radar, 2012
Davenport T.H. (2006) 'Competing on analytics' Harvard Business Review, January 2006, at http://www.insightdata.com.au/mirror/hbr/CompetingOnAnalyticsHBR2006.pdf
DHHS (2012) 'Guidance Regarding Methods for De-identification of Protected Health Information in Accordance with the Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule' Department of Health & Human Services, November 2012, at http://www.hhs.gov/ocr/privacy/hipaa/understanding/coveredentities/De-identification/guidance.html
Dreyfus H.L. (1992) 'What Computers Still Can't Do: A Critique of Artificial Reason' MIT Press, 1992
Economist (2014) `Digital identity cards: Estonia takes the plunge: A national identity scheme goes global' The Economist, 28 June 2014, at http://www.economist.com/news/international/21605923-national-identity-scheme-goes-global-estonia-takes-plunge
English L.P. (2006) 'To a High IQ! Information Content Quality: Assessing the Quality of the Information Product' IDQ Newsletter 2, 3, July 2006, at http://iaidq.org/publications/doc2/english-2006-07.shtml
EU (1995) 'Directive 95 / 46/EC of the European Parliament and of the Council, 24 October 1995, on the protection of individuals with regard to the processing of personal data and on the free movement of such data', European Union, October 1995, at http://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:31995L0046&from=EN
Fan W. & Bifet A. (2012) 'Mining big data: current status, and forecast to the future' ACM SIGKDD Explorations 14, 2 (December 2012) 1-5
Fayyad U., Piatetsky-Shapiro G. & Smyth P. (1996) 'From Data Mining to Knowledge Discovery in Databases ' AI Magazine 17, 3 (1996) 37-54, at http://aaaipress.org/ojs/index.php/aimagazine/article/download/1230/1131..
Gable G.G. (2010) 'Strategic information systems research: An archival analysis' The Journal of Strategic Information Systems 19, 1 (2010) 3-16
Giraud-Carrier C. & Dunham M.H. (2012) 'On the Importance of Sharing Negative Results' ACM SIGKDD Explorations 12,2 (December 2010) 3-4
Greenleaf G. (2014) 'Abandon all hope?' Foreword, UNSW L. J. 37, 2 (September 2014) 636-642, Special Issue on Communications, Surveillance, Big Data and the Law, at http://papers.ssrn.com/sol3/Papers.cfm?abstract_id=2490425
Guo P. (2013) 'Data Science Workflow: Overview and Challenges' ACM Blog, 30 October 2013, at http://cacm.acm.org/blogs/blog-cacm/169199-data-science-workflow-overview-and-challenges/fulltext
Hall M., Frank E., Holmes G., Pfahringer B., Reutemann P. & Witten I.H. (2009) 'The WEKA Data Mining Software: An Update' SIGKDD Explorations 11, 1 (2009), at http://www.sigkdd.org/sites/default/files/issues/11-1-2009-07/p2V11n1.pdf
Hipp J., Guntzer U. & Grimmer U. (2001) 'Data Quality Mining - Making a Virtue of Necessity' Proc. 6th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery (DMKD 2001), pp. 52-57, at http://www.cs.cornell.edu/Johannes/papers/dmkd2001-papers/p5_hipp.pdf
Hipp J., Müller M., Hohendorff J. & Naumann F. (2007) 'Rule-Based Measurement of Data Quality in Nominal Data' Proc. 12th Int'l Conf. on Information Quality, Cambridge, 2007, at http://mitiq.mit.edu/ICIQ/Documents/IQ%20Conference%202007/Papers/RULE-BASED%20MEASUREMENT%20OF%20DATA%20QUALITY%20IN%20NOMINAL%20DATA.pdf
Hirschheim R. (1985) 'Information systems epistemology: An historical perspective' Chapter 2 in Mumford E. et al. (eds.) 'Research Methods in Information Systems', North-Holland, Amsterdam, 1989, pp. 13-35, at http://ifipwg82.org/sites/ifipwg82.org/files/Hirschheim_0.pdf
Huh Y.U., Keller F.R., Redman T.C. & Watkins A.R. (1990) 'Data Quality' Information and Software Technology 32, 8 (1990) 559-565
Inmon B. (1992) 'Building the Data Warehouse' Wiley, 1992
Jacobs A. (2009) 'The Pathologies of Big Data' Communications of the ACM 52, 8 (August 2009) 36-44
Jagadish H.V., Gehrke J., Labrinidis A., Papakonstantinou Y., Patel J.M., Ramakrishnan R. & Shahabi C. (2014) 'Big data and its technical challenges' Communications of the ACM 57, 7 (July 2014) 86-94
KDD (2006) 'Data Mining Curriculum: A Proposal' ACM KDD SIG, Version 1.0, April 2006, at http://kdd.org/curriculum/CURMay06.pdf
Kimball R. (1996) 'The Data Warehouse Toolkit' Wiley, 1996
Labrinidis A. & Jagadish H.V. (2012) 'Challenges and Opportunities with Big Data' Proc. VLDB Endowment 5, 12 (2012) 2032-2033, at http://vldb.org/pvldb/vol5/p2032_alexandroslabrinidis_vldb2012.pdf
LaValle S., Lesser E., Shockley R., Hopkins M.S. & Kruschwitz N. (2011) 'Big Data, Analytics and the Path From Insights to Value' Sloan Management Review (Winter 2011Research Feature), 21 December 2010, at http://sloanreview.mit.edu/article/big-data-analytics-and-the-path-from-insights-to-value/
Luebbers D., Grimmer U. & Jarke M. (2003) 'Systematic Development of Data Mining-Based Data Quality Tools' Proc. 29th VLDB Conference, Berlin, Germany, 2003, at http://www.vldb.org/conf/2003/papers/S17P02.pdf
Madden S. (2012) 'From databases to big data' Editorial, IEEE Internet Computing (May/June 2012) 4-6
McAfee A. & Brynjolfsson E. (2012) 'Big Data: The Management Revolution' Harvard Business Review (October 2012) 61-68
Marchand D.A. & Peppard J. (2013) 'Why IT Fumbles Analytics' Harvard Business Review 91,4 (Mar-Apr 2013) 104-112
Marx G.T. & Reichman N. (1984) 'Routinising the Discovery of Secrets' Am. Behav. Scientist 27,4 (Mar/Apr 1984) 423-452
Mayer-Schonberger V. & Cukier K. (2013) 'Big Data: A Revolution That Will Transform How We Live, Work and Think' John Murray, 2013
Müller H. & Freytag J.-C. (2003) 'Problems, Methods and Challenges in Comprehensive Data Cleansing' Technical Report HUB-IB-164, Humboldt-Universität zu Berlin, Institut für Informatik, 2003, at http://www.informatik.uni-jena.de/dbis/lehre/ss2005/sem_dwh/lit/MuFr03.pdf
Ngai E.W.T., Xiu L. & Chau D.C.K. (2009) 'Application of data mining techniques in customer relationship management: A literature review and classification' Expert Systems with Applications, 36, 2 (2009) 2592-2602
Oboler A., Welsh K. & Cruz L. (2012) 'The danger of big data: Social media as computational social science' First Monday 17, 7 (2 July 2012), at http://firstmonday.org/htbin/cgiwrap/bin/ojs/index.php/fm/article/view/3993/326
OECD (1980) 'Guidelines on the Protection of Privacy and Transborder Flows of Personal Data' OECD, Paris, 1980, mirrored at http://www.rogerclarke.com/DV/OECDPs.html
OECD (2013) 'Exploring Data-Driven Innovation as a New Source of Growth: Mapping the Policy Issues Raised by "Big Data"' OECD Digital Economy Papers, No. 222, OECD Publishing, at http://dx.doi.org/10.1787/5k47zw3fcp43-en
Ohm P. (2010) 'Broken Promises of Privacy: Responding to the Surprising Failure of Anonymization' 57 UCLA LAW REVIEW 1701 (2010) 1701-1711, at http://www.patents.gov.il/NR/rdonlyres/E1685C34-19FF-47F0-B460-9D3DC9D89103/26389/UCLAOhmFailureofAnonymity5763.pdf
O'Reilly T. (2005) 'What Is Web 2.0? Design Patterns and Business Models for the Next Generation of Software' O'Reilly 30 September 2005, at http://www.oreillynet.com/lpt/a/6228
OT (2013) 'Definitions of Big Data' OpenTracker.com, apparently of April 2013, at http://www.opentracker.net/article/definitions-big-data
Park S.-H., Huh S.-Y., Oh W. & Han A.P. (2012) 'A Social Network-Based Inference Model for Validating Customer Profile Data' MIS Quarterly 36, 4 (December 2012) 1217-1237, at http://www.is.cityu.edu.hk/staff/sangphan/mobility/papers/BI_MISQ_%5BHAN,%2520Sang%2520Pil%5D.pdf
Pedersen C.B., Gøtzsche H., Møller J.Ø. & Mortensen P.B. (2006) 'The Danish Civil Registration System: A cohort of eight million persons' Danish Medical Bulletin 53, 4 (November 2006) 441-9, at http://www.danmedbul.dk/Dmb_2006/0406/0406-artikler/DMB3816.htm
van der Pijl G. (1994) 'Measuring the strategic dimensions of the quality of information' Journal of Strategic Information Systems 3, 3 (1994) 179-190
Piprani B. & Ernst D. (2008) 'A Model for Data Quality Assessment' Proc. OTM Workshops (5333) 2008, pp 750-759
Rahm E. & Do H.H. (2000) 'Data cleaning: Problems and current approaches' IEEE Data Eng. Bull., 2000, at http://dc-pubs.dbs.uni-leipzig.de/files/Rahm2000DataCleaningProblemsand.pdf
Ratner B. (2003) 'Statistical Modeling and Analysis for Database Marketing: Effective Techniques for Mining Big Data' CRC Press, June 2003
Roszak T. (1986) 'The Cult of Information' Pantheon 1986
Rusbridge C., Burnhill P., Seamus R., Buneman P., Giaretta D., Lyon L. & Atkinson M. (2005) 'The Digital Curation Centre: A Vision for Digital Curation' Proc. Conf. From Local to Global: Data Interoperability--Challenges and Technologies, Sardinia, 2005, pp. 1-11, at http://eprints.erpanet.org/archive/00000082/01/DCC_Vision.pdf
Russom P. (2010) 'Big Data Analytics' TDWI / IBM, 2011, at http://public.dhe.ibm.com/common/ssi/ecm/en/iml14293usen/IML14293USEN.PDF
Saha B. & Srivastava D. (2014) 'Data Quality: The other Face of Big Data', Proc. ICDE Conf., March-April 2014, pp. 1294 - 1297
Schroeck M., Shockley R., Smart J., Romero-Morales D. & Tufano P. (2012) `Analytics : The real world use of big data' IBM Institute for Business Value / Saïd Business School at the University of Oxford, October 2012, at http://www.ibm.com/smarterplanet/global/files/se__sv_se__intelligence__Analytics_-_The_real-world_use_of_big_data.pdf
Slee T. (2011) 'Data Anonymization and Re-identification: Some Basics Of Data Privacy: Why Personally Identifiable Information is irrelevant' Whimsley, September 2011, at http://tomslee.net/2011/09/data-anonymization-and-re-identification-some-basics-of-data-privacy.html
Stilgherrian (2014a) ' Big data is just a big, distracting bubble, soon to burst' ZDNet, 11 July 2014, at http://www.zdnet.com/big-data-is-just-a-big-distracting-bubble-soon-to-burst-7000031480/
Stilgherrian (2014b) 'Why big data evangelists should be sent to re-education camps' ZDNet, 19 September 2014, at http://www.zdnet.com/why-big-data-evangelists-should-be-sent-to-re-education-camps-7000033862/
Sweeney L. (2002) 'k-anonymity: a model for protecting privacy' International Journal on Uncertainty, Fuzziness and Knowledge-based Systems 10, 5 (2002) 557-570, at http://arbor.ee.ntu.edu.tw/archive/ppdm/Anonymity/SweeneyKA02.pdf
UKICO (2012) 'Anonymisation: managing data protection risk: code of practice' Information Commissioners Office, November 2012, at http://ico.org.uk/for_organisations/data_protection/topic_guides/~/media/documents/library/Data_Protection/Practical_application/anonymisation-codev2.pdf
Wang R.Y. & Strong D.M. (1996) 'Beyond Accuracy: What Data Quality Means to Data Consumers' Journal of Management Information Systems 12, 4 (Spring, 1996) 5-33
Waterman K.K. & Bruening P.J. (2014) 'Big Data analytics: risks and responsibilities' International Data Privacy Law 4, 2 (June 2014), at http://idpl.oxfordjournals.org/content/4/2/89.abstract
Wigan M.R. & Clarke R. (2013) `Big Data's Big Unintended Consequences' IEEE Computer 46, 6 (June 2013) 46 - 53, PrePrint at http://www.rogerclarke.com/DV/BigData-1303.html
Zhang D. (2013) 'Inconsistencies in Big Data' Proc. 12th IEEE Int. Conf. on Cognitive Informatics & Cognitive Computing (ICCI*CC'13)
This version has benefited from valuable feedback from Kasia Bail, Lyria Bennett Moses, Russell Clarke and David Vaile.
Roger Clarke is Principal of Xamax Consultancy Pty Ltd, Canberra. He is also a Visiting Professor in the Cyberspace Law & Policy Centre at the University of N.S.W., and a Visiting Professor in the Research School of Computer Science at the Australian National University.
| Personalia |
Photographs Presentations Videos |
Access Statistics |
 |
The content and infrastructure for these community service pages are provided by Roger Clarke through his consultancy company, Xamax. From the site's beginnings in August 1994 until February 2009, the infrastructure was provided by the Australian National University. During that time, the site accumulated close to 30 million hits. It passed 65 million in early 2021. Sponsored by the Gallery, Bunhybee Grasslands, the extended Clarke Family, Knights of the Spatchcock and their drummer |
Xamax Consultancy Pty Ltd ACN: 002 360 456 78 Sidaway St, Chapman ACT 2611 AUSTRALIA Tel: +61 2 6288 6916 |
Created: 15 August 2014 - Last Amended: 19 December 2014 by Roger Clarke - Site Last Verified: 15 February 2009
This document is at www.rogerclarke.com/EC/BDQF.html
Mail to Webmaster - © Xamax Consultancy Pty Ltd, 1995-2022 - Privacy Policy