Roger Clarke's Web-Site
© Xamax Consultancy Pty Ltd, 1995-2024

Infrastructure
& Privacy
Matilda
Roger Clarke's Web-Site© Xamax Consultancy Pty Ltd, 1995-2024 |
|
|||||
| HOME | eBusiness |
Information Infrastructure |
Dataveillance & Privacy |
Identity Matters | Other Topics | |
| What's New |
Waltzing Matilda | Advanced Site-Search | ||||
Final Version of 16 May 2018
Proc.
Bled
eConference, 17-20 June 2018
Roger Clarke and Kerry Taylor **
© Xamax Consultancy Pty Ltd, 2018 and Kerry Taylor
Available under an AEShareNet ![]() licence or a Creative
Commons
licence or a Creative
Commons  licence.
licence.
This document is at http://www.rogerclarke.com/EC/BDBP.html
The accompanying slide-set is at http://www.rogerclarke.com/EC/BDBP.pdf
The big data movement has been characterised by highly enthusiastic promotion, and caution has been in short supply. New data analytic techniques are beginning to be applied to the operational activities of government agencies and corporations. If projects are conducted in much the same carefree manner as research experiments, they will inevitably have negative impacts on the organisations conducting them, and on their employees, other organisations and other individuals. The limited literature on process management for data analytics has not yet got to grips with the risks involved. This paper presents an adapted business process model that embeds quality assurance, and enables organisations to filter out irresponsible applications.
Big Data and Data Analytics have attracted a great deal of attention. However, the techniques are now escaping from the laboratory with only a limited degree of maturity having been achieved. Unless businesslike approaches are adopted, the intentional looseness of academic experiments may become engrained in practice. The objective of the work reported here is to specify a business process whereby organisations can ensure that applications of data analytics satisfy both strategic and policy purposes and legal and ethical constraints.
A design science research approach was adopted (Brown et al. 1978, Hevner et al. 2004, Hevner 2007). Although primarily applied to the development of information technology artefacts, the approach is also relevant to socio-technical artifacts, including methods for applying technology (Gregor & Hevner 2013, p.337). As Peffers et al. (2007) acknowledges, "for design in practice, the Design Science Research Methodology (DSRM) may contain unnecessary elements for some contexts" (p.72). DSRM has accordingly been applied as a guide rather than as a specification.
The research commenced with problem identification and motivation, followed by definition of the objectives. This laid the foundation for design and development of the artefact. The approach adopted to the later phases was to consider a real-world case and demonstrate that the use of the method would have been likely to identify in advance the problems that arose in the case, and hence would have avoided harm and protected investment.
The paper commences with a brief review of the fields of big data and data analytics, sufficient to provide a basis for the analysis that follows. Representations of the data analytics business process are identified in text-books and the academic literature. The risks arising from data analytics activities are then considered, and techniques for identifying and addressing those risks are identified. Refinements to the conventional business process are proposed that enable data analytics to be conducted in a responsible manner. An initial evaluation of the proposed process is performed, by applying it to a case study.
Stripped of marketing prose, the term 'big data' merely means any relatively large data collection. The key characteristics were originally postulated as volume, velocity and variety (Laney 2001). Further factors were added later, including value and veracity (Schroeck et al. 2012). Such vague formulations as 'data that's too big, too fast or too hard for existing tools to process' pervade the definitions catalogued in OT (2013), Ward & Barker (2013), and De Mauro et al. (2015).
The term 'data analytics' has been used in technical disciplines for many years. It refers to the techniques whereby a data collection is used to draw inferences. Previous decades of work in statistical sciences, operations research, management science and data mining have delivered a very substantial array of analytical tools, and more are being developed. Chen et al. (2012) uses the term Business Intelligence and Analytics (BI&A), and distinguishes two phases to date. Those authors see BI&A 1.0 as being characterised by "data management and warehousing, reporting, dashboards, ad hoc query, search-based BI, [online analytical processing (OLAP)], interactive visualization, scorecards, predictive modeling, and data mining" (p. 1166). BIA 2.0, on the other hand, which has been evident since the early 2000s, is associated with web and social media analytics, including sentiment analysis, and associated-rule and graph mining, much of which is dependent on semantic web notions and text analysis tools (pp. 1167-68). The authors anticipated 'BIA 3.0', to cope with mobile and sensor-generated data. The term 'fast data' has since emerged, to refer to near-real-time analysis of data-streams (e.g. Pathirage & Plale 2015).
When considering how to manage data analytics activities, it is useful to distinguish categories of purpose to which big data analytics may be applied. See Table 1. Hypothesis testing involves quite different approaches from the drawing of inferences about populations, and from the construction of profiles. Further, whereas those three categories relate to populations, several other functions to which data analytics can be applied relate to individuals.
After Clarke (2017), Table 1
This approach evaluates whether a proposition is supported by the available data. The proposition may be a prediction from theory, an existing heuristic, or a hunch
This approach draws inferences about a population of entities, or about sub-populations. In particular, correlations may be drawn among particular attributes
This approach identifies key characteristics of some category of entities. For example, attributes and behaviours of a target group, such as 'drug mules', sufferers from particular diseases, or children with particular aptitudes, may exhibit statistical consistencies
A search can be conducted for individual entities that exhibit patterns associated with a particular, previously asserted or computed profile, thereby generating a set of entities of interest
This approach draws inferences about individual entities within the population. For example, a person may be inferred to have provided inconsistent information to two organisations, or to exhibit behaviour in one context inconsistent with behaviour in another
Statistical outliers are often disregarded, but this approach regards them instead as valuable needles in large haystacks, because they may represent exceptional cases, or may herald a 'flex-point' or 'quantum shift'
____________
On the basis of this brief overview, the following section presents a description of the conventional business processes for data analytics.
A remarkably small proportion of the multitude of papers on big data has as its focus the business process or life-cycle of data analytics. There is little evidence of a cumulative literature or a dominant authority referred back to by subsequent authors.
Chen et al. (2014) suggests four phases of "the value chain of big data", but from a process perspective the authors offer little more than four phase-names and a three-step breakdown of the second phase. Their phases are: data generation, data acquisition (comprising collection, transportation and pre-processing), data storage and data analysis. Jagadish et al. (2014) uses instead a five-step process, comprising: acquisition; extraction and cleaning; integration, aggregation, and representation; modeling and analysis; and interpretation. The framework of Pääkkönen & Pakkala (2015) involves seven process phases of source acquisition (implied), extraction, loading and preprocessing, processing, analysis, loading and transformation, and interfacing and visualisation.
Huang et al. (2015) has six steps, commencing with question formulation and proceeding to data collection, data storage and transferral, data analysis, report / visualisation, and evaluation. Phillips-Wren et al. (2015) uses the five phases of sources, preparation, storage, analysis, and access and usage. Elragal & Klischewski (2017) offer 'pre-stage', acquisition, preprocessing, analytics and interpretation. The Wikipedia entry for Predictive Analytics is somewhat more comprehensive, with Project Definition, Data Collection and Data Analysis, followed by Statistics, Modelling and Deployment, and culminating in a Model Monitoring phase. Text-book approaches include Provost & Fawcett (2013), which proposes the phases Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation and Deployment.
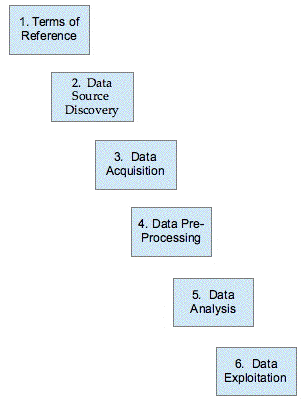
In Figure 1, a process model is presented that is a composite of the elements found in the above sources. However, it embodies a key refinement. The majority of the examples that have been identified omit any preliminary phase. It would arguably be too constraining to impose a 'requirements elicitation' phase on those data analytics activities that are oriented towards opportunity discovery and creation. On the other hand, some degree of framing is needed, even for creative work. The expression 'Terms of Reference' has accordingly been used for the first phase, to encourage pre-thinking about the project's context, but also to encompass degrees of formalisation ranging from 'question formulation' to 'requirements analysis'.
The subsequent phases will vary in their content depending on the nature and purpose of the particular project. The second, Data Source Discovery phase, covers such activities as search, evaluation, and negotiation of access. The third phase, Data Acquisition, deals with the collection or extraction of data from the identified source(s). In the fourth, Data Pre-Processing phase, data from various sources may be integrated and may be scrubbed, re-formatted, interpolated and/or modified. These lay the foundations for the fifth and sixth Data Analysis and Data Exploitation phases, including such activities as inferencing, interpretation, visualisation and application.
The following section discusses risks that arise from the conduct of data analytics and conventional approaches to the discovery and management of risks.
Most of the literature on big data and data analytics is concerned with the identification of opportunities, and much of it is highly upbeat and excited about the prospects. Some articles do, however, urge caution, e.g. "well-designed and highly functional [business intelligence] systems that include inaccurate and unreliable data will have only limited value, and can even adversely impact business performance" (Park et al. 2012). Elragal & Klischewski (2017) also express concern about completeness, correctness, and consistency. The following paragraphs briefly summarise the results of prior research by the first-named author on quality factors in big data and data analytics, reported in Wigan & Clarke (2013), and Clarke (2015, 2016a, 2016b, 2017).
Data quality factors comprise those characteristics that can be assessed at the time that the data is originally created. They include syntactical validity, appropriate association, appropriate signification, accuracy, precision and temporal applicability. Information quality factors, on the other hand, are those that can only be assessed at the time of use, and in the context of use. These include theoretical and practical relevance, currency, completeness, controls and auditability. Blithe claims are made about data quality not mattering when very large quantities of data are available. e.g. "the need to find a scrupulously accurate sample (the world of small data) has been overtaken by the availability of all of the data--much of it messy but in such volumes that new correlations can be found. In other words quantity trumps quality" (Turnbull 2014). Executives know not to take such claims at face value, because there are only limited and fairly specific circumstances in which they can be justified. Many of the purposes to which data analytics is put may be seriously undermined by low-quality data.
Claims are also rife in the data mining literature that data can be 'cleaned' or 'cleansed' (Rahm & Do 2000, Müller & Freytag 2003). Such processes are better described as 'wrangling' (Kandel et al. 2011), and are most honestly referred to as 'data scrubbing'. By whatever name, these techniques seek to address such problems as missing values, syntactical errors in data content, syntactical differences among apparently comparable data-items, low quality at time of capture, degraded quality during storage and missing metadata. Energetic as the endeavour may be, however, it seldom achieves a state reasonably described as 'clean'. Few of the processes described in the literature and applied in practice involve comparisons against an authoritative external reference, most of the processes are merely manipulations based on statistical analyses of the data-set itself, and the changes made as a result of such activities introduce errors.
Decision quality factors must also be carefully considered, because otherwise the value of data analytics work will be undermined, and harm will arise if the results are relied upon for real-world decision-making. The meaning of individual data-items is frequently opaque, and may be assumed rather than being understood in sufficient depth, with the result that misunderstandings and mistaken assumptions readily occur. The many and varied analytical techniques all make assumptions about data and about context, and some of those assumptions are implicit rather than clearly stated. The preconditions for use of each technique may or may not be taught in parallel with the mechanics of the technique, and the significance of that information may or may not be grasped, and may or may not be remembered.
The rationale underlying the inferences that each data analytics technique gives rise to may be clear to the analyst, and may be successfully communicated to the decision-maker who relies on it. However, the transparency of rationale varies a great deal, and in many of the new techniques that have emerged during the last decade, is seriously lacking. Neural networks are largely empirical. They are not based on any formal model of a solution, of a problem, or even of a problem-domain (Clarke 1991, Knight 2017) Further, their behaviour may vary greatly depending on the training-set used and the nature of the instance run against the training-set. Similarly, the various forms of AI and machine learning (ML) that are being applied in this field, provide outputs, but seldom make available humanly-understandable explanations of how those outputs were achieved and what assumptions underlie them. Another approach that may suffer from the problem is 'predictive analytics', which is sometimes used in the very narrow sense of extrapolations of patterns derived from time-series rather than of the time-series themselves.
The plethora of quality factors that can undermine data analytics efforts give rise to considerable risks. Many of them are borne by the organisation that exploits the outputs of data analytics techniques. These include negative impacts on the quality of organisational decisions and actions, and hence on return on investment, and on policy outcomes. There may also be opportunity costs, to the extent that resources are diverted to big data projects that, with hindsight, could have been better invested in alternative activities with higher return.
Some risk are borne by other parties, however, because organisational decisions and actions affect other organisations and individuals. Decisions and actions that are unreasonable or even wrong can inflict harm ranging from inconvenience, via onerousness and inversion of the onus of proof, to serious economic, financial and/or psychological harm. Such problems may return to haunt the organisation whose actions gave rise to them, in such forms as reputational damage, lawsuits and additional regulatory imposts.
Wild enthusiasts such as Anderson (2008), McAfee & Brynjolfsson (2012) and Mayer-Schonberger & Cukier (2013) publish claims that science is obsolete and that the need is now to know, not to know why. Hard-headed directors, auditors and executives, on the other hand, seek assurance that authors of that ilk are unable to provide. Professionals and consultants support executives in managing risk, by means of a variety of tools. Quality assurance and formal risk assessment are well-known techniques and are the subject of copious documentation in both formal Standards (ISO 31000 and 31010, and the 27005 series) and commercial processes (ISACA COBIT, ITIL, PRINCE2, etc.). Risk assessment processes of these kinds are conducted from the organisation's own perspective. Where risks fall on other organisations and individuals, other techniques are needed. Relevant techniques include Technology Assessment (TA - Guston & Sarewitz 2002), Privacy Impact Assessment (PIA - Clarke 2009, Wright & De Hert 2012) and Surveillance Impact Assessment (Wright & Raab 2012).
The following section considers how the conventional process model identified in section 3 can be adapted in order to manage the risks identified in this section.
Previous research established a set of Guidelines for the conduct of data analytics in a manner that is responsible in terms of protecting the interests both of the organisation on whose behalf the activity is being performed and of other stakeholders (Clarke 2018). Those Guidelines provide a basis on which a business process can be established that addresses the weaknesses in existing approaches. The following sub-sections identify further process elements that need to be added to the conventional process depicted in Figure 1, present an adapted form of business process, and discuss alternative ways in which the proposed generic business model can be applied.
The purpose of the new artefact is to provide a basis whereby an organisation can ensure that problems arising during the data analytics process can be detected, and detected early. This enables appropriate measures to be put in place in order to address those problems. Two categories of process element need to be added to the conventional model described earlier: evaluation steps, and selection constructs that, under appropriate circumstances, loop the flow back to an earlier phase.
Awareness of risks is a crucial pre-condition for effective risk management, and hence there is a need for evaluation of both data and decision processes against quality standards. Cai & Zhu (2015) and Hastie & O'Donnell (2017), for example, each includes an outline of a data quality assessment process. A few authors, such as Koronios et al. (2014), expressly include one or more evaluation elements, and feedback or feedforward from those elements. In the Knowledge Discovery in Databases (KDD) community, a 'knowledge discovery process' has been proposed that recognises the need for loops back to earlier phases where data or processes fall short of reasonable standards (Fayyad et al. 1996, Han et al. 2011). Elragal & Klischewski (2017) discuss epistemological challenges in data analytics, the importance of understanding model assumptions, and the need for results to be assessed.
Various tests need to be performed, and appropriate locations need to be identified at which each test can be applied. Established techniques of quality assurance (QA) and risk assessment (RA) can be brought to bear, including requirements elicitation, interviews with executive, managerial, supervisory and operational staff, and review of the data. Similarly, the conventional classification of risk management (RM) strategies can be applied, distinguishing proactive strategies (avoidance, deterrence, prevention, redundancy), reactive strategies (detection, reduction/mitigation, recovery, insurance) and non-reactive strategies (self-insurance, graceful degradation, graceless degradation).
Where significant impacts may arise outside the organisation, the additional techniques of impact assessment (IA) and impact management (IM) are needed. These activities develop an appreciation of the contexts, needs and values of external stakeholders. Many external stakeholders are users of, or at least participants in, the system in question. However, it is important not to overlook 'usees', by which is meant organisations, but more commonly individuals, who are affected by the system without directly participating in it (Clarke 1992, Fischer-Hübner & Lindskog 2001, Baumer 2015). Developing the necessary appreciation generally depends on consultation with representatives or and/or advocates for the various external stakeholder groups.
In this sub-section, the conventional model that was presented in Figure 1 is adapted, by building in evaluation steps and conditionally redirected flows. A general framework is provided by professional standards in the areas of QA, RA and IA, and RM and IM. More specifically, the adapted model reflects the specific risk factors identified in the Guidelines for the responsible conduct of data analytics (Clarke 2018). A copy of the Guidelines is provided as an Appendix to the present paper.
The adapted business process is presented in Figure 2. The discussion in this section intentionally uses general and even vague expressions, in order to accommodate the considerable diversity of purposes to which data analytics is put, as discussed earlier, in section 2 and Table 1.
During Phase 1 - Terms of Reference, it is advantageous to not only clarify the problem or opportunity that is the project's focus, but also the governance framework that applies, the expertise required within the team, and the legal compliance and public expectations that are relevant to the activity (paras. 1.1-1.3 of the Guidelines). These provide reference-points that support subsequent evaluation steps.
After Phase 2 - Data Source Discovery, the Evaluation step needs to reconsider section 1 of the Guidelines (G1.1-1.3). Of particular significance is the legality of the intended acquisition and use of the data. This step also needs to examine the extent to which the team has understood the problem-domain (G2.1) and the nature of the data sources, including the data's provenance, purposes of creation, definitions, and quality (G2.2). Depending on the conclusions reached in the evaluation step, it may be necessary to return to Phase 1 and re-cast the Terms of Reference, or even to abort the project.
After Phase 3 - Data Acquisition, the largely theoretical evaluation of data quality that was undertaken after Phase 2 needs to be complemented by practical assessment against the full suite of data quality and information quality factors discussed in section 4, including the incidence and impact of missing data and non-conformant data (G2.2). The effects of any merger, scrubbing, identity protection or data security measures undertaken prior to the data coming under the control of the project team must also be assessed (G2.3-2.8).
After Phase 4 - Data Pre-Processing, the effects of all merger, scrubbing, identity protection and data security measures undertaken by or for the project team must be assessed (G2.3-2.8). In addition to data and information quality factors, a look-ahead to the Data Analysis phase is advisable, in order to anticipate any further issues with data characteristics that may arise, such as incompleteness, inconsistency, and format and measurement scale incompatibilities.
It may transpire that the project flow needs to depart from the mainstream. For example, it may be that the project should be held in Phase 4 until further work relevant to data quality is performed. Alternatively, it may be necessary to loop back to the 3rd phase, e.g. by re-acquiring the data using different parameter-settings or procedures, or to the 2nd phase, to acquire data from alternative sources, or even to the 1st phase, in order to re-conceive the project.
After Phase 5 - Data Analysis, the evaluation step needs to consider all of Guidelines 3.1-3.6. These relate to the adequacy of the expertise applied to the analytics, the nature of, and the intrinsic assumptions underlying, the relevant analytical techniques, the nature of the data, the compatibility of the data and the technique, and the transparency of the rationale for inferences drawn. Where the data or the inferences drawn involve sensitivity and/or the actions taken as a result are likely to be particularly impactful, a look-ahead may be advisable, in particular by performing some preliminary reality testing (G4.3).
After Phase 6 - Data Exploitation, it is important to apply all of Guidelines 4.1-4.11. These involve appreciation of the impacts (e.g. by workshopping with staff and others with familiarity with the relevant parts of the real world), internal cost/benefit and risk assessment, where relevant external impact assessment, reality testing, the design, implementation and testing of safeguards (such as metricated pilots, interviews, feedback processes, feedback evaluation), proportionality checking, contestability, testing of the understandability of the decision-rationale, and review and recourse. Depending on the nature and potential impact of the actions that are being considered, it may be advisable to commence the evaluation process at an early stage in this phase, rather than at the end of it.
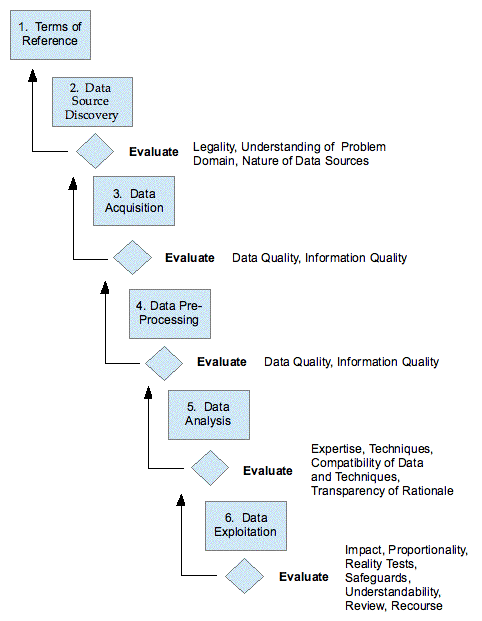
The adapted business process features the same phases as the conventional model. Evaluation steps have been specified after each phase, together with guidance in relation to circumstances in which looping back to prior phases is desirable and even essential. The adapted model enables the identification of problems at any early stage, and hence the implementation of measures to address them. It therefore fulfils the declared objective of the research, which was to specify a business process whereby organisations can ensure that applications of data analytics satisfy both strategic and policy purposes and legal and ethical constraints.
The business process model in Figure 2, and the Guidelines on which it was to a considerable extent based, were expressed in somewhat abstract terms. That was necessary in order to achieve sufficient generality to enable application in a range of circumstances.
One dimension of diversity among projects is the category of purpose, as discussed in section 2 and Table 1. Another way in which projects differ is their degree of embeddedness within a corporate framework. In the case of a standalone project, each phase and each evaluation step may need to be planned and performed as a new activity. At the other extremity, every phase and every step may be tightly constrained by existing corporate policies and practices, perhaps in the form of an industry standard or a proprietary process management framework imposed by or on the organisation.
Another factor to consider in applying the model to a project is the extent to which the project is ground-breaking or novel. A less painstaking approach can reasonably be adopted where the project falls into a well-known category, and is being conducted by a team with both expertise and experience in relation to the problem-domain, the data-sets, the data analytic techniques, the pitfalls, the stakeholders and their interests, and the project's potential impacts.
The following section makes an initial contribution to the evaluation of the proposed business process.
In Peffers et al. (2007), two related phases are defined towards the end of the design research approach. These distinguish 'demonstration' of the use of the artifact to solve one or more instances of the problem (by means of experimentation, simulation, case study, proof, or other appropriate activity), from 'evaluation', which involves more formal observation and measurement of the new artefact's effectiveness in addressing the stated objectives. The research reported in this paper included a demonstration step, based on a case study.
Centrelink is the Australian government agency responsible for distributing welfare payments. During the second half of 2016, Centrelink launched a new system that was intended to improve the efficiency of the agency's processes whereby control is exercised over overpayments. The new Online Compliance Intervention (OCI) system featured simple data analytics that were used to draw inferences about likely overpayments of welfare payments, combined with automated decision-making. The implementation resulted in a large proportion, and very large numbers, of unjustified and harmful actions by the agency, which gave rise to serious public concern and two external investigations, which in turn forced the agency to make multiple changes to the scheme.
This represents a suitable test-case for the artefact developed in this research project. The data analytics used were trivially simple, but the big data collections that were matched were not. The project was real - and, indeed, for many of the people affected by it, all too real. It involved all steps of the life-cycle. In addition, unlike most private sector data analytics projects, it was subject to the glare of publicity, and is documented by two substantial and independent reports. A 3,000-word case study was prepared by the first-named author, based on the two reports and about 20 substantive media articles. It is provided as Supplementary Material in support of the present paper.
The major problems arising in the case appear to have resulted from a small number of factors. The most critical issue was that the new system implicitly assumed that the annual income declared by welfare recipients to the taxation agency could be divided by 26 in order to establish a reliable estimate of the income that each of them earned in each fortnight of that year. Many welfare recipients, on the other hand, earn some and even all of their small incomes from short-term, casual and/or seasonal employment, and hence they work variable numbers of hours per fortnight. This has the inevitable result that their income is unevenly distributed across the year, and an assumption of even distribution is seriously problematical. Centrelink failed to appreciate how significant that issue was, and remained in denial 12 months after implementation.
The generic business process proposed in Figure 2 includes within Phase 1 - Terms of Reference the establishment of a governance process, identification of the expertise required within the team, and consideration of the legal compliance and public expectations that are relevant to the activity. If the team had included people with strong familiarity with both the real world of benefit recipients and the relevant data models, together with experienced data analysts, then the unreasonableness of the assumption of income being evenly distributed over a period would have been obvious. Similarly, if the agency's legal obligations, and the vulnerability of many of its clients, had been clear in the minds of the team-members, they would have taken greater care in considering the potential impacts of the design. Even if these framing elements had been overlooked, any and all of the five evaluation steps across the recommended life-cycle would have been very likely to identify this major problem well in advance of implementation. In particular, it would have become clear that the design process needed to include consultation with the operational staff, the taxation agency, and advocates for welfare recipients' interests.
A second major problem was the abandonment of checks with employers, which Centrelink had identified as an avoidable cost. The agency sought to transfer these costs to the recipients; but this proved to be unreasonable, partly because of many recipients' cognitive and performative limitations, and partly for systemic reasons. Had the proposed business process model been used, the unreality of this key assumption might also have been uncovered during one of the early-phase evaluation steps; but at the very least it would have become apparent during Phase 6 - Data Exploitation.
A third problem was the automation of both debt-raising and the commencement of debt collection. The triggers were nothing more than non-response by the targeted welfare recipient, or their failure to deliver satisfactory evidence to prosecute their innocence of the accusation. The previous system had involved considerable computer-based support, but also a number of manual steps. Under the new, naive system of suspicion-generation, the case-load leapt more than 30-fold, from 20,000 p.a. to 10-20,000 per week. This overwhelmed the support services, resulting in a complete log-jam of enquiries and complaints, and escalating numbers of auto-generated debts and debt-collection activities. Several of the elements making up this compounding problem could have been intercepted early in the process, and all of them would have become apparent at latest during the Phase 6 evaluation steps, if the business process in Figure 2 had been applied.
The Centrelink case demonstrates the benefits of inserting QA elements between the successive phases, and the insertion of loops where problems are found. It also provides the valuable insight that a conventional requirements analysis that incorporated interviews with operational staff, followed by internal risk assessment, may well have been sufficient to prevent much of the harm, but that these alone would have very likely missed some key factors. Because the system directly affected 'usees', external impact assessment was necessary, including consultation with advocacy organisations.
Conventional business processes for data analytics lack three important features: a preliminary, planning phase; evaluation steps; and criteria for deciding whether a project needs to be looped back to an earlier phase. On the basis of established theories and prior research into risk assessment of data analytics projects, an adapted business process model was proposed, which makes good those deficiencies. A recent case was considered in the light of the adapted model.
The implications for practice are clear. Data analytics embodies many risks. Organisations that conduct or commission data analytics projects are subject to legal obligations. In some contexts, such as highly-regulated industry sectors, these may be fairly specific; but in any case company directors are subject to broad responsibilities in relation to the management of risk. The concerns of consumers and citizens are increasing, the media is eager to snowball cases of large organisations treating people badly, and social media has provided means for the public to escalate issues themselves. Investors, board rooms and executives will demand that a balance is struck between data exploitation and due care. QA, RA and RM, and IA and IM, need to be applied. The adapted business process shows how.
The research reported here can be strengthened in a number of ways. It is built primarily on academic work, because reliable reports of active data analytics projects are difficult to acquire. A much stronger empirical base is needed, such that actual business processes can be better understood, and the adapted model's efficacy can be evaluated. The model is, for the reasons explained above, generic in nature. It requires tailoring to the various specific contexts identified above, and further articulation.
A number of implications can be drawn for research in the area. Observation of practice, and publications arising from it, are likely to encounter nervousness on the part of project teams and the organisations for whom the project is undertaken. Some concerns will relate to competitive, commercial and strategic factors, and others to ethical, legal and political considerations. Academic projects to apply data analytics tools need to incorporate controls at a much earlier stage than is currently the case, to ensure that the transitions from research to IR&D, and on to live use, are not undermined by the late discovery of quality issues. The work reported here accordingly provides a substantial contribution to both practice and research.
Elsevier Pre-Publication Version here



Anderson C. (2008) 'The End of Theory: The Data Deluge Makes the Scientific Method Obsolete' Wired Magazine 16:07, 23 June 2008, at ://archive.wired.com/science/discoveries/magazine/16-07/pb_theory
Baumer E.P.S. (2015) 'Usees' Proc. 33rd Annual ACM Conference on Human Factors in Computing Systems (CHI'15), April 2015
Brown H., Cook R. & Gabel M. (1978) 'Environmental Design Science Primer' Advocate Press, 1978
Cai L. & Zhu Y. (2015) 'The Challenges of Data Quality and Data Quality Assessment in the Big Data Era' Data Science Journal 14 (2015) 2, at http://doi.org/10.5334/dsj-2015-002
Cao L. (2016) 'Data science: nature and pitfalls' IEEE Intelligent Systems 31, 5 (September/October 2016) 66-75, at http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=7579413
Cao L. (2017) 'Data science: a comprehensive overview' ACM Computing Surveys 50, 3 (October 2017), at http://dl.acm.org/ft_gateway.cfm?id=3076253&type=pdf
Chen H., Chiang R.H.L. & Storey V.C. (2012) 'Business Intelligence and Analytics: From Big Data to Big Impact' MIS Quarterly 36, 4 (December 2012) 1165-1188, at http://ai.arizona.edu/mis510/other/MISQ%2520BI%2520Special%2520Issue%2520Introduction%2520Chen-Chiang-Storey%2520December%25202012.pdf
Chen M., Mao S. & Liu Y. (2014) 'Big Data: A Survey' Mobile Network Applications 19 (2014) 171?209, at http://www.ece.ubc.ca/~minchen/min_paper/BigDataSurvey2014.pdf
Clarke R. (1991) 'A Contingency Approach to the Application Software Generations' Database 22, 3 (Summer 1991) 23 - 34, PrePrint at http://www.rogerclarke.com/SOS/SwareGenns.html
Clarke R. (1992) 'Extra-Organisational Systems: A Challenge to the Software Engineering Paradigm' Proc. IFIP World Congress, Madrid, September 1992, PrePrint at http://www.rogerclarke.com/SOS/PaperExtraOrgSys.html
Clarke R. (2009) 'Privacy Impact Assessment: Its Origins and Development' Computer Law & Security Review 25, 2 (April 2009) 123-135, at http://www.rogerclarke.com/DV/PIAHist-08.html
Clarke R. (2015) 'Quasi-Empirical Scenario Analysis and Its Application to Big Data Quality' Proc. 28th Bled eConference, Slovenia, 7-10 June 2015, PrePrint at http://www.rogerclarke.com/EC/BDSA.html
Clarke R. (2016a) 'Big Data, Big Risks' Information Systems Journal 26, 1 (January 2016) 77-90, PrePrint at http://www.rogerclarke.com/EC/BDBR.html
Clarke R. (2016b) 'Quality Assurance for Security Applications of Big Data' Proc. European Intelligence and Security Informatics Conference (EISIC), Uppsala, 17-19 August 2016, PrePrint at http://www.rogerclarke.com/EC/BDQAS.html
Clarke R. (2017) 'Big Data Prophylactics' Chapter 1 in Lehmann A., Whitehouse D., Fischer-Hübner S., Fritsch L. & Raab C. (eds.) 'Privacy and Identity Management. Facing up to Next Steps' Springer, 2017, pp. 3-14, at http://www.rogerclarke.com/DV/BDP.html
Clarke R. (2018) 'Guidelines for the Responsible Application of Data Analytics' Forthcoming, Computer Law & Security Review 34, 3 (Jul-Aug 2018), PrePrint at http://www.rogerclarke.com/EC/GDA.html
De Mauro A., Greco M. & Grimaldi M. (2015) 'What is big data? A consensual definition and a review of key research topics ' Proc. AIP 1644 (2015) 97 (2015), at http://big-data-fr.com/wp-content/uploads/2015/02/aip-scitation-what-is-bigdata.pdf
Elragal A. & Klischewski R. (2017) 'Theory-driven or process-driven prediction? Epistemological challenges of big data analytics' Journal of Big Data 4. 19 (2017), at https://journalofbigdata.springeropen.com/articles/10.1186/s40537-017-0079-2
Fayyad U., Piatetsky-Shapiro G. & Smyth P. (1996) 'The KDD Process for Extracting Useful Knowledge from Volumes of Data' Commun. ACM 39, 11 (November 1996) 27-34
Fischer-Hübner S. & Lindskog H. (2001) ' Teaching Privacy-Enhancing Technologies' Proc IFIP WG 11.8 2nd World Conference on Information Security Education, Perth, Australia (2001)
Gregor S. & Hevner A. (2013) 'Positioning Design Science Research for Maximum Impact' MIS Quarterly 37, 2 (June 2013 ) 337-355, at https://ai.arizona.edu/sites/ai/files/MIS611D/gregor-2013-positioning-presenting-design-science-research.pdf
Guston D.H. & Sarewitz D. (2001) 'Real-time technology assessment' Technology in Society 24 (2002) 93-109, at http://archive.cspo.org/documents/realtimeTA.pdf
Han J., Kamber M. & Pei J. (2011) 'Data mining: concepts and techniques' Morgan Kaufmannn, 3rd Edition, 2011
Hastie R. & O'Donnell A. (2017) 'Training Pack: Responsible Data Management' Oxfam, August 2017, at https://protection.interaction.org/2004-2/
Hevner A.R. (2007) 'A three cycle view of design science research' Scandinavian Journal of Information Systems 19, 2 (2007) 4
Hevner A.R., March S.T., Park J. & Ram S. (2004) 'Design science in information systems research' MIS Quarterly 28, 1 (2004) 75-105
Huang T., Lan L., Fang X., Min J. & Wang F. (2015) 'Promises and Challenges of Big Data Computing in Health Sciences' Big Data Research 2, 1 (March 2015) 2-11
Jagadish H.V., Gehrke J., Labrinidis A., Papakonstantinou Y., Patel J.M., Ramakrishnan R. & Shahabi C. (2014) 'Big data and its technical challenges' Communications of the ACM 57, 7 (July 2014) 86-94
Kandel, S., Heer, J., C. Plaisant, C., Kennedy, J., van Ham, F., Henry-Riche, N., Weaver, C., Lee, B., Brodbeck, D. & Buono, P. (2011) 'Research directions for data wrangling: visualizations and transformations for usable and credible data' Information Visualization 10. 4 (October 2011) 271-288, at https://idl.cs.washington.edu/files/2011-DataWrangling-IVJ.pdf
Knight W. (2017) 'The Dark Secret at the Heart of AI' 11 April 2017, MIT Technology Review https://www.technologyreview.com/s/604087/the-dark-secret-at-the-heart-of-ai/
Koronios A., Gao J. & Selle S. (2014) 'Big Data Project Success ? A Meta Analysis' Proc. PACIS 2014, p.376, at http://aisel.aisnet.org/pacis2014/376
Laney D. (2001) '3D Data Management: Controlling Data Volume, Velocity and Variety' Meta-Group, February 2001, at http://blogs.gartner.com/doug-laney/files/2012/01/ad949-3D-Data-Management-Controlling-Data-Volume-Velocity-and-Variety.pdf
McAfee A. & Brynjolfsson E. (2012) 'Big Data: The Management Revolution' Harvard Business Review (October 2012) 61-68
Marchand D.A. & Peppard J. (2013) 'Why IT Fumbles Analytics' Harv. Bus. Rev. (Jan-Feb 2013) 2-9
Mayer-Schonberger V. & Cukier K. (2013) 'Big Data: A Revolution That Will Transform How We Live, Work and Think' John Murray, 2013
Müller H. & Freytag J.-C. (2003) 'Problems, Methods and Challenges in Comprehensive Data Cleansing' Technical Report HUB-IB-164, Humboldt-Universität zu Berlin, Institut für Informatik, 2003, at http://www.informatik.uni-jena.de/dbis/lehre/ss2005/sem_dwh/lit/MuFr03.pdf
OT (2013) 'Definitions of Big Data' OpenTracker.com, apparently of April 2013, at http://www.opentracker.net/article/definitions-big-data
Pääkkönen P. & Pakkala D. (2015) 'Reference Architecture and Classification of Technologies, Products and Services for Big Data Systems' Big Data Research 2, 4 (2015) 166-186, at https://www.sciencedirect.com/science/article/pii/S2214579615000027/pdfft?md5=5af642001f750f63eaeb3fbe35f5ccdc&pid=1-s2.0-S2214579615000027-main.pdf
Park S.-H., Huh S.-Y., Oh W. & Han A.P. (2012) 'A Social Network-Based Inference Model for Validating Customer Profile Data' MIS Quarterly 36, 4 (December 2012) 1217-1237, at http://www.is.cityu.edu.hk/staff/sangphan/mobility/papers/BI_MISQ_%5BHAN,%2520Sang%2520Pil%5D.pdf
Pathirage M. & Plale B. (2015) 'Fast Data Management with Distributed Streaming SQL' arXiv preprint arXiv:1511.03935, at http://arxiv.org/abs/1511.03935
Peffers K., Tuunanen T., Rothenberger M. & Chatterjee S. (2007) 'A design science research methodology for information systems research' Journal of Management Information Systems, 24, 3 (2007) 45-77, at http://www.sirel.fi/ttt/Downloads/Design%20Science%20Research%20Methodology%202008.pdf
Phillips-Wren G., Iyer L.S., Kulkarni U. & Ariyachandra T. (2015) 'Business Analytics in the Context of Big Data: A Roadmap for Research' Commun. AIS 37, 23
Provost F. & Fawcett T. (2013) 'Data Science for Business' O'Reilly, 2013
Rahm E. & Do H.H. (2000) 'Data cleaning: Problems and current approaches' IEEE Data Eng. Bull., 2000, at http://dc-pubs.dbs.uni-leipzig.de/files/Rahm2000DataCleaningProblemsand.pdf
Schroeck M., Shockley R., Smart J., Romero-Morales D. & Tufano P. (2012) `Analytics : The real world use of big data' IBM Institute for Business Value / Saïd Business School at the University of Oxford, October 2012, at http://www.ibm.com/smarterplanet/global/files/se__sv_se__intelligence__Analytics_-_The_real-world_use_of_big_data.pdf
Turnbull M. (2014) 'Benefiting from big data the government's approach' Address by the Minister for Communications (and soon afterwards, the Prime Minister) to the Australian Information Industry Association, April 2014, at https://www.malcolmturnbull.com.au/media/benefiting-from-big-data-the-governments-approach
Ward J.S. & Barker A. (2013) 'Undefined By Data: A Survey of Big Data Definitions' arXiv, 2013, at https://arxiv.org/pdf/1309.5821 Wigan M.R. & Clarke R. (2013) 'Big Data's Big Unintended Consequences' IEEE Computer 46, 6 (June 2013) 46 - 53, PrePrint at http://www.rogerclarke.com/DV/BigData-1303.html
Wright D. & De Hert P. (eds) (2012) 'Privacy Impact Assessments' Springer, 2012
Wright D. & Raab C.D. (2012) 'Constructing a surveillance impact assessment' Computer Law & Security Review 28, 6 (December 2012) 613-626
This paper benefited from feedback from several colleagues, including Dr Bernard Robertson-Dunn.
Roger Clarke is Principal of Xamax Consultancy Pty Ltd, Canberra. He is also a Visiting Professor in the Cyberspace Law & Policy Centre at the University of N.S.W., a Visiting Professor in the E-Commerce Programme at the University of Hong Kong, and a Visiting Professor in the Research School of Computer Science at the Australian National University.
Kerry Taylor is an Associate Professor (Data Science) in the Research School of Computer Science at the Australian National University. She has previously worked on a UN 'big data' project with Australian Bureau of Statistics, and spent 20 years at CSIRO as a principal research scientist in the polyonymous IT research division. She has also worked as an IT practioner in consulting, publishing, education and government, in Sydney, Montreal and Oxford.
| Personalia |
Photographs Presentations Videos |
Access Statistics |
 |
The content and infrastructure for these community service pages are provided by Roger Clarke through his consultancy company, Xamax. From the site's beginnings in August 1994 until February 2009, the infrastructure was provided by the Australian National University. During that time, the site accumulated close to 30 million hits. It passed 65 million in early 2021. Sponsored by the Gallery, Bunhybee Grasslands, the extended Clarke Family, Knights of the Spatchcock and their drummer |
Xamax Consultancy Pty Ltd ACN: 002 360 456 78 Sidaway St, Chapman ACT 2611 AUSTRALIA Tel: +61 2 6288 6916 |
Created: 3 January 2018 - Last Amended: 16 May 2018 by Roger Clarke - Site Last Verified: 15 February 2009
This document is at www.rogerclarke.com/EC/BDBP.html
Mail to Webmaster - © Xamax Consultancy Pty Ltd, 1995-2022 - Privacy Policy