Roger Clarke's Web-Site
© Xamax Consultancy Pty Ltd, 1995-2024

Infrastructure
& Privacy
Matilda
Roger Clarke's Web-Site© Xamax Consultancy Pty Ltd, 1995-2024 |
|
|||||
| HOME | eBusiness |
Information Infrastructure |
Dataveillance & Privacy |
Identity Matters | Other Topics | |
| What's New |
Waltzing Matilda | Advanced Site-Search | ||||
Version of 5 March 1989
Published in Expert Systems 6,3 (August 1989)
Translated into Japanese and re-published in Nikkei AI (Winter, 1990)
© Xamax Consultancy Pty Ltd, 1987-89
This document is at http://www.rogerclarke.com/SOS/KBTL.html
As Knowledge-Based Technology (KBT) becomes commercially exploitable, large financial commitments are being made, and businessmen are increasingly concerned to protect those investments. The nature of property rights in software is outlined. Issues arising in relation to software in general, and KBT in particular, are considered, and some significant areas of uncertainty are identified.
It should not be assumed that investment in KBT-based products and applications automatically gives rise to property rights in the resulting software. Investors and technologists should seek legal advice as to whether, in the relevant legal jurisdictions, copyright or other intellectual property rights apply to their software. Further, they should take the steps necessary to establish and retain such rights.
Expert systems, an active area of research for three decades, are discussed in this paper under the more descriptive and more operationally definable term Knowledge-Based Technology (KBT). In recent years claims have been made, not just by marketing interests, but also by well-respected researchers, that KBT is graduating into a commercially exploitable technology (e.g. [27], [22], [2], [4], [10], [34], [44]). Many large corporations and government agencies have been reported as having embarked upon pilot projects, and some claim to have already implemented worthwhile applications.
Given that practical applications are being made of a new, and potentially very powerful technology, then it is important that consideration be given to the legal framework within which disputes regarding expert systems products will be resolved. There has been little discussion in the literature to date (see however [29], [46], [13]. More general discussions of information technology and the law include [43], [39], [37], [23], [12], [38], [21] and [7]).
This paper commences with a brief definition of key terms used in KBT. It then discusses the legal framework of ownership rights, and identifies areas of difficulty applying to software in general, and KBT-based software in particular.
The term 'expert system' has proven to be subject to an inconveniently wide range of interpretations. The word 'expert' may either refer to the source of the knowledge captured into the software, or to the nature or standard of performance expected of it . The word 'system' may be understood very broadly, or may refer to a specific piece of software, as in the term 'payroll system'. In addition, the term has been associated with a high degree of independence from the mainstream information technology into which it now needs to be absorbed.
As used in this paper, the term 'knowledge-based technology' (KBT) means the application of a set of analytical and programming techniques and tools. Beyond the techniques and tools themselves, KBT therefore also encompasses the manner in which they are applied, and the education, training and organisational structure and infra-structure which support their use.
Because the field is still so new, the set of techniques and tools is explained somewhat differently by leading texts (e.g. [1], [19], [18]). They may be broadly classified into three groups:
Conventional requirements analysis and software engineering technology deals with procedures or algorithms which access precisely structured data, whereas KBT places the emphasis on 'knowledge'. Few authorities make clear what they mean by this term. In practice, the dominant manner in which it is used is as that which can be expressed in the form of antecedent-consequent-rules. At the operational level, knowledge is used in contemporary KBT to mean sets of rules and heuristics pertaining to some problem-domain, expressed as IF-THEN-ELSE constructs. Rules are 'deep knowledge' based on causal models, whereas heuristics are 'surface knowledge' based only on correlation or intuition. The important discontinuity compared to conventional software development technology, is that the problem-solver no longer needs to think down at the level of the procedures and data which underlie the knowledge, and can therefore cope with more difficult problem-domains.
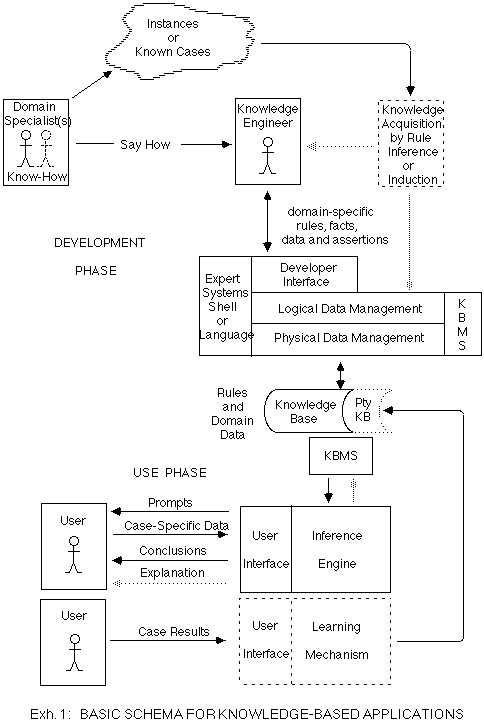
Exhibit 1 provides a model of the development and use of KBT as it is currently practised. It omits technical detail, but includes the relevant elements and relationships. During the Development Phase, knowledge is extracted from one or more people with specialised knowledge in the relevant domain. Such a person is usually referred to in the literature as an 'expert', but the more general term 'domain specialist' is less pretentious and more general. In some cases it may be possible for the domain specialist to feed the knowledge directly into a 'knowledge-base', but more usually an intermediary analyst/programmer (referred to as a 'knowledge engineer') captures it using some appropriate language and supporting software.
At some later time, a user, without reference to either the domain specialist or the knowledge engineer, consults the knowledge-base. He provides information about some event or situation within the problem domain. The software draws inferences, by applying the rules stored in the knowledge-base to the case-specific data and the more general (domain-specific) data stored in the knowledge-base. A result is provided to the user, in the form of a diagnosis, prognosis, recommendation, decision, etc, depending on the nature of the application. In addition, an explanation may be provided, showing the argument whereby the software reached its conclusion.
In addition to these fundamental elements, Exhibit 1 also incorporates three emergent areas of KBT:
Ownership rights in software are established through intellectual property law, a conventional term used to refer to a set of related areas of substantive law (e.g. [35]). As far as computer software is concerned, the most important of these is copyright ([29], [24], [40], [14], [28], [23], [25]). The term also includes patents, (registered) designs, (registered) trade marks, trade secrets and sui generis (specific-purpose) approaches such as chip protection legislation. In different circumstances, each of these heads of intellectual property law has significance for software.
The various forms of intellectual property law had long maturation periods, and each addresses specific economic needs. Copyright protects expressions of ideas (i.e. the form rather than the content of the work), whereas patents protect ideas. Patents provide a much more substantial protection than copyright, but require the applicant to jump a very high hurdle, take a long time to be awarded, and apply only for a relatively short time. Few items of software have qualified for patent protection ([17]).
Copyright law substantially predates computers. It originated in the United Kingdom as a result of pressure on the Crown from a guild called the Stationers Company, which represented letter-writers, illuminators, bookbinders and booksellers. As a result of the introduction of the printing press around the 1470s, these professions felt their investment in 'literary works' to be threatened, and lobbied (if the reader will excuse the modern word) for protection of their rights. Cases won in the courts were in due course codified and extended by an Act of Parliament - 8 Anne c.19 of 1709 ([32], [35] pp.57-70). That it took 240 years to get this statute on the books is in part testimony to the turbulence of the times, including the Civil War. In part, however, it could be taken to be indicative of the reaction time of governments to new technologies.
Remarkably, the applicability of copyright law to software has been uncertain until very recently. For many years, doubt was expressed about whether copyright did or even should subsist in software. In 1970, Breyer [3] specified the conditions under which economic grounds for applying copyright to software would exist. Niblett [30] judges that these were fulfilled by the early 1980s, and Prescott [33] further argues that "copyright law was unimportant in the practical world of computers until the advent of the microcomputer".
In the United States, the applicability of copyright to computer programs was established only in 1982 (in Williams Electronics v. Artic International) and was based on the 1980 amendment to the Copyright Act. Apple Computer Inc., feeling the ravages of unauthorised copying of its Apple II hardware and software, set out to establish clearly the scope of its rights. The judgement in Apple v. Franklin (1983) made clear that copyright applies to the source code, to the 'object code' - more accurately 'executable code', and to executable code stored in ROM. In a number of other countries the company has had similar successes, e.g. in Canada in Mackintosh v. Apple (1987).
However, there have been failures too. In the test-case in Australia (Apple v. Computer Edge, in 1983-86), the courts decided that software was not copyrightable ([41], [6]). An amendment to the Copyright Act was rushed through Parliament in mid-1984, but has not yet been tested in the courts. In the United Kingdom, although legal commentators generally considered that software was copyrightable, the Copyright Act was amended in 1985 to make the coverage explicit. However, neither the old nor the new provisions have been tested before the courts.
The most fundamental problem is that there is real doubt about the long-term suitability of copyright as the means of providing property rights in software. For example, Menell [26] argues that copyright has generally been concerned with literary and other artistic works, whereas utilitarian works have been traditionally protected by patent and trade secrets laws. Indeed, the major justifications for using copyright were that it was relatively well understood, and that it was easily and quickly obtained.
Software is what economists call a 'public good' (because it is difficult to exclude people who did not pay for it from using it; and additional users do not deplete the supply of the good). However, many of the improvements in information technology are incremental, such that the developer of a new product substantially replicates, but somewhat improves upon, the features of an existing product. It is therefore against the public interest to give the originator of software an ability to preclude others from copying it. This is especially clear in the area of user interfaces, where there is a positive advantage in encouraging standardisation. Since copyright tends to create a substantial monopoly power, a better sui generis (general-purpose) protective framework may in time emerge.
To return to the current situation, there remain many countries in which the applicability of copyright law to software is not yet clear, and some where government commitment to ensure its applicability cannot be assumed. Even in countries where copyright has been explicitly defined to apply to software, areas of doubt remain. The United Kingdom has considered further amending the Copyright Act to clarify the law as it relates to software - but there have been suggestions as to how those clarifications should themselves be clarified (e.g. [42]). Canada amended its Act in 1988, because even though the courts had found in favour of Apple, as copyright owner, the judgements had raised some areas of doubt (e.g. [15]). In Australia, although the Government legislated in 1984 to explicitly include software within the copyright umbrella, the Attorney-General has recently referred some outstanding matters of concern to its Copyright Law Review Committee (e.g. [16]).
Even in the U.S., where direct copying of software clearly violates copyright law, doubts remain concerning what may be termed 'non-literal forms of copying' [26]. In several recent cases, courts have held (in the specific instances that have come before them) that copyright protection extended to the overall structure, sequence and organisation of the application program, even including the text and artwork of screen displays and other aspects of the user interface. These have come to be referred to as 'look and feel' cases.
Of the matters which remain in doubt in at least some jurisdictions, many involve deeply technical legal issues, such as the boundaries between 'ideas' (which are in general not protected by copyright) and 'expressions of ideas' (which are); and the precise meaning of 'a substantial portion' of a work. Other problems are semantic in nature, with judges making interpretations of such terms as 'language' and 'code' which information technologists find, to say the very least, surprising ([6]).
Some of the most fundamental difficulties arise from the variety of forms in which software can exist. Software may originate in one form, be translated into another for actual use, and may pass through one or more intermediate translations and forms. The original form may be procedural/algorithmic in nature, or declarative, or merely descriptive. The clear identification of these forms, and the manner in which the law treats them, requires more careful analysis than has been applied in the past (see [8] for an analysis from the viewpoint of product liability).
In order to attract the protection of copyright, an owner must comply with certain requirements at the time the software is created. Moreover, retention of the protection is also conditional on certain factors. The qualification requirements vary considerably between jurisdictions, but in some countries (including, importantly, the U.S.A.) at least some of the conditions can be expensive to comply with, or are impractical.
There are also lingering doubts concerning works which originate in machine-readable form, since they may not be visible or otherwise humanly perceivable, as copyright law generally requires. Problems may therefore arise in relation to graphic designs, computer art, music and databases which come into being with the aid of computers. The same applies to text created using word processing software and text-editors, and therefore to poems, novels and business reports. Software usually originates as computer-readable text, or, as Computer-Aided Software Engineering (CASE) begins to have an impact, as computer graphics. In any country where capture of the original version of a work onto a medium which was not humanly readable is held to disqualify the work from copyright protection, property rights in software would be affected.
A further problem is referred to by Hofstadter ([20] p.607) as 'meta-authorship'. Consider software which generates product names using a random letter generator, and filters them using rules relating to linguistics, rudeness and the style-norms of the particular field (e.g. pharmaceuticals, breakfast cereals, cars, or indeed expert system shells). Who owns the result of applying such a product - the person on whose behalf the parameters were supplied (who made a contribution of very limited originality), or the person who owns the generator? Indeed, does anyone own it? Computer-generated music, program-generated business graphics, and the vast numbers of 'fourth generation' program generators and application generators raise the same issue. In the vast majority of jurisdictions, it is entirely unclear whether copyright in computer-generated software exists, and if so to whom it belongs.
The law is still struggling to adapt to computers 4-5 decades after their invention. It would be surprising if a technology such as KBT, at the forefront of IT, did not raise some additional issues. This section identifies five.
Where KBT is implemented using conventional languages and data-management software, it probably enjoys the same level of protection as does any other software. However, KBT's aim is to break out of certain strictures placed upon the analyst/developer by conventional development infrastructures.
The most common form of knowledge-bases is as sets of inter-related rules, expressed in a manner that enables processing by a particular kind of run-time interpreter called an 'inference engine'. Such a knowledge-base is therefore not 'software' in the conventional sense of a sequence of instructions intended to determine the actions of a computer. As a result, courts in some jurisdictions may choose not to construe knowledge-bases to be software for the purposes of copyright. They might treat them as some other type of work to which copyright applies, or they might find them to be uncopyrightable.
Where a KBT application comprises a number of specially-written components, copyright is likely to at least exist in relation to those which are software, e.g. to the developer interface, data management, inference engine or user interface. If the knowledge-base is only usable in conjunction with such specially-written components, the lack of property rights in the knowledge-base may not be of great concern. However, productivity is being sought in KBT, and it is increasingly common for third party components to be used, particularly for inference and knowledge management. The smaller the proportion of the KBT application which was custom-written, the less likely it would be that the product as a whole would be treated by the court as software. Yet it is in just such cases, where the knowledge-base is readily usable via generally available software, that copyright protection for the investment would be particularly important.
The concepts upon which conventional information technology are based have created some difficulties for the courts, for example in distinguishing between data and the media on which it is stored, and between data and programs. KBT poses far greater challenges. The notion of 'knowledge' implicit in KBT is, from the perspective of the relevant branches of philosophy, far from all-embracing (e.g. [36], [45], [11]). However, it is still a very rich intellectual concept, more abstract than many others with which the law has to grapple. The following example is intended to clarify one important aspect of the difficulties with which the courts, and hence purveyors and purchasers of KBT, will have to cope.
KBT pilot projects have been undertaken in a number of organisations to capture the expertise of a person whose services are about to be lost to them, typically due to retirement. Until now, these projects have been perceived very positively by management, and have involved a highly regarded knowledge engineer. The behavioural phenomenon popularly called the 'fishbowl effect' has generally been sufficient to ensure the goodwill of the domain specialist.
Consider the same project in the absence of the aura of importance and novelty. Where the domain specialist declines the invitation to express his know-how in understandable terms, by what means can an employer seek to enforce his will, and his moral and (presumed) legal right? Laws of the relevant jurisdiction (e.g. those relating to trade secrets, confidence and Official Secrets) might preclude the person from divulging the knowledge to a third party (assuming that the law treats 'knowledge' in the same way that it does 'information'). Employment law might preclude the person from using the knowledge to the advantage of himself or a future employer. Employment law might even provide an enforceable right to the employer regarding the divulging of specific information or data (e.g. what was said in a telephone conversation with a client). However, it appears very unlikely that the law provides employers with anything approaching a property right in the knowledge of their employees.
If this is so, then employers will not be able to legally enforce their requirements (e.g. that employees express their 'rules of thumb', comment on the knowledge-engineer's drafts and prototypes, identify difficult instances, or test the knowledge-base). Senior professionals and managers are likely to comply with reasonable requests, but the ability of employers to persuade operational, supervisory and technical employees to cooperate would probably be harmed, particularly in industries and companies with an unfavourable industrial relations climate. Such matters will become increasingly important as the flush of KBT's youthful enthusiasm fades, the technology becomes routinised, and the calibre, presence, patience and prescience of knowledge engineers decreases.
The situation is even less clear in relation to the knowledge of persons whose relationship with the organisation is not of the nature of an employment contract. Remembering the homily that "a consultant is someone who borrows your watch to tell you the time, then keeps your watch", organisations would be well-advised to establish clear contractual obligations if they want to be able to enforce contractors and consultants to divulge know-how they develop in the course of providing services.
The programmer who writes software is its author, and prima facie its first owner. However, work performed under a contract of employment or service belongs to the employer. Where software is developed for another party, the terms of contract between the programmer or his employer, and the client, may explicitly or implicitly transfer ownership to the client.
Difficulties can arise where several persons can lay claim to being the author. Where several programmers write different portions of a single product, it is usually straightforward to determine ownership on the basis of simple contractual terms. More difficult issues may arise with KBT-based products, of which the following two are apparent.
A knowledge engineer is merely, or at least essentially, encapsulating the knowledge of one or more domain-specialists. Parties with arguable rights of ownership of the resulting product are not only the developer and his client, but also the domain-specialist(s).
With conventional software packages, situations seldom arise in which a user can claim that modifications he has undertaken are sufficiently substantial as to give him an interest in the resulting product. However, many packaged knowledge-bases may be delivered in such a way as to be user-extensible, e.g. by the modification of existing rules, or the addition of new ones. Since even small changes to the original knowledge-base may result in significant differences in the product's functions and output, some users may develop a legally arguable case to have some rights in the modified product.
Beyond shared authorship, KBT is at particular risk of encountering the 'meta-authorship' problem, whereby a court might construe the software not to be an original work involving intellectual effort by a human or other legal person. Two aspects are apparent.
There has been considerable progress in the automation of rule-induction, whereby 'surface' (correlation-based) rules are generated from a set of cases. Often these tools are used to assist the knowledge-engineer. However, researchers claim that it is at least feasible for the resulting rules to be directly entered into a knowledge-base, perhaps providing the entire content of the knowledge-base.
Where automated knowledge acquisition is applied, it is unclear whether copyright exists in the generated rules, and if so to whom it belongs. Contenders include the organisation for whom the induction process was performed, the owner of the copyright in the cases (if any exists), and the owner of the induction software. Note that the discussion is complicated by the uncertainties as to whether knowledge-bases are subject to copyright, and whether multiple copyrights in a knowledge-base whose rules come from different sources need to be disentangled.
The idea of machine-learning involves an existing knowledge-base being automatically modified on the basis of cases resolved by the knowledge-base itself. This of course represents a first-order control loop, and therefore presumes a meta-process which monitors the basic process. It does not at this stage appear to be an exploitable sub-technology, but is discussed earnestly in the literature, and could put in an early appearance in a conventional experimental environment, such as defense applications.
KBT-based software which incorporates machine-learning creates additional questions about authorship and hence ownership. A software developer would be likely to regard the modifications to the knowledge-base as resulting directly from the original author's work. But it is arguable that they derive from the particular 'experience' the software has gained from the cases the user has presented to it. In that case (since the software and computer are not themselves legal entities which can possess property), the user may reasonably argue for a legally enforceable financial interest in the resulting product.
The third generation of procedural languages enabled programmers to express a problem-solution in a convenient form. The current fourth generation of program and application generators enables the developer to delegate the solution to the computer, such that the concern is not with a problem-solution, but with a clear definition of the problem. A knowledge engineer operates at a significantly more abstract level than does a conventional software developer. KBT focuses not on problem-solutions, not even on problems, but on the problem-domain. It relieves the developer of the need to formulate explicit definitions of problems which are to be solved. If they exist at all, the problem-definitions are not within the knowledge-base, nor the case-specific data, nor the inference engine. Each problem-definition is implicit within a particular process or case, which is an ephemeral combination of elements of many different components. The software developer is therefore relatively remote from the problems which the software will later address.
There are at least three respects in which KBT embodies even greater levels of abstraction. One is the concept of 'meta-rules', the higher-order criteria whereby a choice is made among several contending lower-order rules (e.g. depth-first or breadth-first search). The second is machine-learning, whereby a software component may modify the knowledge-base (i.e. add new rules or change existing rules) as a result of case 'experience'. There are no doubt researchers already working on higher-order learning mechanisms, whereby a software component would monitor the success/failure of each learned modification to the knowledge-base, adapting the learning rules or algorithms. In due course this approach may well disappoint in much the same way as cybernetics (in the sense of cascades of nested control loops) has not fulfilled early expectations. But at the very least it is likely to have its 'season in the sun', with at least some applications becoming operational.
A knowledge-base's performance may be significantly changed by modification of a single rule. Hence even relatively simple machine-learning might bring a KBT application quickly to the point at which it could be credibly argued before a court to exhibit autonomous behaviour. The link between a product and the effort invested by its developer plays a significant role in intellectual property law. Hence, the courts may decline to recognise property rights in KBT applications which incorporate a significant element of machine learning. Clearly, the equally worrisome question as to who might be held responsible for harm arising from autonomous behaviour must also be addressed ([5] 101-38, [9]).
A third respect in which KBT exhibits yet higher levels of abstraction is in the emerging techniques based on the 'connectionist' or 'neural' machine concept. In effect these techniques enable empirical knowledge to be stored in the form in which it arises, rather than pre-processed into production rules. This yet higher level of abstraction (a sixth generation?) will pose even greater challenges to intellectual property law, because the domain understanding shown by, and the contribution to the software's development made by, the engineer (or trainer?) will be quite small.
Ownership rights are only one kind of protection for the developers' interests. For example, many KBT applications will be unusable other than by a particular, highly-specialised professional, or within a particular corporate context. However, depending on the context of the product or application, property rights may be one of the important elements in ensuring ongoing investment in new applications of new technologies.
Many developers blithely assume that their investment and efforts earn them the protection of ownership rights. In some jurisdictions, such as Australia until mid-1984, these assumptions have turned out to be unjustified; and in many other jurisdictions and circumstances, the law remains unclear. Investors in KBT products and applications should avoid placing undue dependence on property rights. Where other forms of protection are insufficient, they should seek legal advice firstly as to whether copyright or other intellectual property law is applicable, and secondly as to the requirements to establish and retain such rights.
Because of the law's uncertainty and slow rate of change, the pioneers of any new technology are likely to encounter unexpected and frustrating difficulties. It is very difficult to force the law to adapt to technological change. The courts generally avoid changing the law for policy reasons, believing that law reform is the role, even the exclusive role, of Governments. Meanwhile, Governments try to avoid legislating on complex technological matters that they do not understand, particularly matters which offer little in the way of votes or campaign funds.
If KBT is to fulfil its promise, it is necessary for Governments to consider whether, and if so in what manner, intellectual property rights in knowledge-bases should exist, and to make such changes in the law as are necessary to remove ambiguities. In order to make Governments aware of the problem, it is necessary for affected organisations within the information technology industry to commission authoritative legal opinions, prepare briefing papers, decide the legislative measures required, and lobby for them.
[1] Barr A. & Feigenbaum E.A. (Eds.) 'The Handbook of Artificial Intelligence' Vols 1 and 2 Kaufman 1981, 1982
[2] Blanning R.W. 'Expert Systems for Management: Research and Applications' J. of Info. Sci. 9 (1985) 153-62
[3] Breyer S. 'The Uneasy Case for Copyright: A Study of Copyright in Books, Photocopies and Computer Programs' 84 Harvard L. Rev. 281 (1970)
[4] Buchanan B.G. 'Expert Systems: Working Systems and the Research Literature' Expert Systems 3,1 (January 1986) 32-51
[5] Capper P. & Susskind R. 'Latent Damage Law: The Expert System' Butterworths, London, 1988
[6] Clarke R. 'Judicial Understanding of Information Technology: The Case of the Wombat ROMs' Comp. J. 31,1 (Feb 1988) 25-33
[7] _______ 'Legal Aspects of Knowledge-Based Technology' J of Info Technology 3,1 (March 1988)
[8] _______ 'Who is Liable for Software Errors?' forthcoming in Comp. Law & Security Report 5,1 (May/Jun 1989)
[9] _______ 'Liabilities Arising from Knowledge-Based Technology' Working Paper, 1989
[10] Connell N.A.D. 'Expert Systems in Accountancy: A Review of Some Recent Applications' Acc. & Bus. Rev. 77,67 (Summer 1987)
[11] Dreyfus H.L. & Dreyfus S.E. 'Mind Over Machine' Free Press, 1986, 1988
[12] Edwards C. & Savage N. (Eds.) 'Information Technology and The Law' Macmillan 1986
[13] Frank S.J. 'What AI Practitioners Should Know About the Law' AI Mag 9,1&2 (Spring, Summer 1988)
[14] Graham R.L. 'The Legal Protection of Computer Software' Comm ACM 27,5 (1984) 422-6
[15] Gray B.W. 'Copyright in Computer Software' Comp. Law & Security Report 4,2 (Jul/Aug 1988) 11-15
[16] Greenleaf G.W. 'Software Copyright: FAST and loose amendments' 62 ALJ 6 457-61 (Jun 1988)
[17] Hanneman H.W.A.M. 'The Patentability of Computer Software' Kluwer 1985
[18] Harmon P. & King D. 'Expert Systems' Wiley 1985
[19] Hayes-Roth F. et al. 'Building Expert Systems' Addison-Wesley 1983
[20] Hofstadter D.R. 'Gödel, Escher, Bach: An Eternal Golden Braid' Penguin 1980 Orig. published by Basic Books 1979
[21] I/S Analyzer 'Information and the Law' I/S Analyzer 26,1 (Jan 1988)
[22] Johnson T. 'The Commercial Exploitation of Expert System Technology' Ovum London 1984
[23] Keet E.E. 'Preventing Piracy: A Business Guide to Software Protection' Addison-Wesley 1985
[24] Lechter M.A. 'Protecting Software and Firmware Developments' IEEE Computer 73-82 (1981)
[25] Menell P.S. 'Tailoring Legal Protection for Computer Software' 39 Stan. L. Rev. 1129 (1987)
[26] _______ 'An Analysis of the Scope of Copyright Protection for Application Programs' forthcoming 41 Stan. L. Rev. (1989)
[27] Michaelsen R. & Michie D. 'Expert Systems in Business' Datamation Nov. 1983
[28] Millard C.J. 'Legal Protection of Computer Programs and Data' Sweet & Maxwell 1985
[29] Niblett B. 'Legal Protection of Computer Programs' Oyez 1980
[30] _______ 'Copyright Protection of Computer Programs' in Campbell C. (ed.) 'Data Processing and the Law' Sweet & Maxwell, London, 1984
[31] Nycum S.H. et al. 'Artificial Intelligence and Certain Resulting Legal Issues' The Computer Lawyer (May 1985) 1-10
[32] Patterson L.R. 'Copyright in Historical Perspective' Vanderbilt, Nashville (1968)
[33] Prescott P. 'Copying and Microcomputers' in Campbell C. (ed.) 'Data Processing and the Law' Sweet & Maxwell, London, 1984
[34] Quinlan J.R. (Ed.) 'Applications of Expert Systems' Addison-Wesley 1987
[35] Ricketson S. 'The Law of Intellectual Property' Butterworths 1984
[36] Roszak T. 'The Cult of Information' Pantheon, New York 1986
[37] Scott M.D. 'Computer Law' Wiley 1984
[38] Smedinghoff T.J. 'The Legal Guide to Developing, Protecting and Marketing Software' Wiley 1986
[39] Soma J.T. 'Computer Technology and The Law' McGraw-Hill 1983
[40] Sterling J.A.L. & Hart G.E. 'Copyright Law in Australia' Legal Books, 1981
[41] ________ 'Reproducing and Adapting Computer Programs' Comp. Law & Security Report 3,3 (Sep/Oct 1987) 21-3
[42] ________ 'The Copyright, Designs and Patents Bill 1987' Comp. Law & Security Report 3,5 (Jan/Feb 1988) 2-9
[43] Tapper C. 'Computer Law' 3rd Ed Longman 1983
[44] von Weissenfluh D. 'Überblick über Einsatzgebiete betrieblicher Expertensysteme' ('Overview of Application Areas of Operational Expert Systems') Arbeitsbericht Nr. 15 Institut für Wirtschaftsinformatik Uni. Bern 1987
[45] Winograd T. & Flores F. 'Understanding Computers and Cognition' Ablex, 1986
[46] Zeide J.S. & Liebowitz J. 'Using Expert Systems: The Legal Perspective' IEEE Expert (Spring 1987) 19-22
Williams Electronics v. Artic International (1982) 685 F.2d 875
Apple v. Franklin (1983) U.S. Court of Appeals for the Third Circuit Judgment No. 82-1582 (30 Aug. 1983)
Mackintosh Computers & others v. Apple Computer Inc. & another (1987) 9 IPR 621-48
Computer Edge Pty. Ltd v. Apple Computer Inc. (1986) 60 ALJR 313
| Personalia |
Photographs Presentations Videos |
Access Statistics |
 |
The content and infrastructure for these community service pages are provided by Roger Clarke through his consultancy company, Xamax. From the site's beginnings in August 1994 until February 2009, the infrastructure was provided by the Australian National University. During that time, the site accumulated close to 30 million hits. It passed 65 million in early 2021. Sponsored by the Gallery, Bunhybee Grasslands, the extended Clarke Family, Knights of the Spatchcock and their drummer |
Xamax Consultancy Pty Ltd ACN: 002 360 456 78 Sidaway St, Chapman ACT 2611 AUSTRALIA Tel: +61 2 6288 6916 |
Created: 27 July 2000 - Last Amended: 27 July 2000 by Roger Clarke - Site Last Verified: 15 February 2009
This document is at www.rogerclarke.com/SOS/KBTL.html
Mail to Webmaster - © Xamax Consultancy Pty Ltd, 1995-2022 - Privacy Policy