Roger Clarke's Web-Site
© Xamax Consultancy Pty Ltd, 1995-2024

Infrastructure
& Privacy
Matilda
Roger Clarke's Web-Site© Xamax Consultancy Pty Ltd, 1995-2024 |
|
|||||
| HOME | eBusiness |
Information Infrastructure |
Dataveillance & Privacy |
Identity Matters | Other Topics | |
| What's New |
Waltzing Matilda | Advanced Site-Search | ||||
Preprint of a paper appearing in Computer Law & Security Report 22, 4 (July-August 2006) 287-297
Version of 30 April 2006
© Xamax Consultancy Pty Ltd, 2005-06
Available under an AEShareNet ![]() licence or a Creative
Commons
licence or a Creative
Commons  licence.
licence.
This document is at http://www.rogerclarke.com/II/Gurgle0604.html
Google began as yet another search-engine. Its owners have found a successful business model, have established additional lines of business, and have achieved quite dramatic growth and profitability. The now very rich and multi-facetted Google corporation is a 'newly big business', and is forthrightly challenging consumers, 'old big business', and competition, copyright, consumer and privacy laws.
Google Inc. is a classic case of late-mover advantage, and of survival of the dot.com boom-and-bust. The company has been highly successful, in terms of business-growth, capital-raising, revenue-growth, share-price, and even profitability. After a mere 7 years, it has already attracted Business School hagiography (e.g. Vise & Malseed 2005). But those are not the reasons for this article.
Google is unusual in being a corporation of vast scale and influence while it is still young, vigorous and brash. It is defining a new industry sector, and goes about its business quite differently from the large, long-established corporations whose patches it is trampling on. Google has thrown down the gauntlet to old-world corporations that are reliant on monopoly protections. It has many consumer-manipulative features, but they have to date stimulated only limited user resistance. And its modus operandi is directly confronting many aspects of the law.
This paper provides brief overviews of the new marketspaces and of Google's lines of business, and then analyses their impacts on competition, copyright, consumer and privacy laws.
The World Wide Web exploded into popular consciousness in 1993. The Web's function is to enable users to access content provided by others. All that the consumer has to do is provide a piece of client-software called a web-browser with the URL (Uniform Resource Locator, popularly referred to as a 'Web-address').
During the first few years of the Web, consumers discovered URLs by receiving them in an email, by seeing them on the sides of buses, by guessing them, and by following 'hot-links' from other Web-pages - the last of which became known as 'web-surfing'. As the volume of content increased, however, these became inadequate means for the escalating user-population to find what they were interested in accessing. New services were needed.
Discovery of content needles in the Web haystack depends on someone constructing an index of the available content. Techniques to do this have existed for centuries, at least since Hugh of St. Cher's biblical concordance in the 13th century. Within 30 years of the commencement of the digital era, in the 1970s and 1980s, software was developed to automate both the indexing of large volumes of text and the application of that index to the discovery of documents that matched individual users' needs.
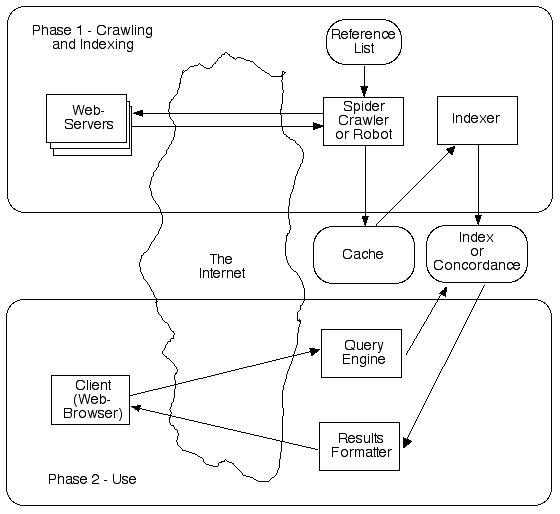
What came to be known as 'search-engines' applied these established techniques, and adapted and further developed them to suit the new context. The processes underlying search-engine services are depicted in Exhibit 1. People seeking content can key search-terms into a client, such as a web-browser. These are conveyed to a Query Engine, which looks up an Index, and passes the results to a Formatter, which provides a response to the user. This is only possible because, in an earlier phase, specialist software variously referred to as a web-spider, crawler or robot has trawled the net. A web-spider downloads web-pages, and places copies in intermediate storage, in a very particular application of the concept commonly referred to as Cache. An Indexer then creates an Index of the occurrences of words (or of strings of letters) that the downloaded web-pages contain.
Search engines drove the effectiveness, efficiency and useability of the Web to new levels. That in turn created new business opportunities. A large number of search-engines have been established, and many are still in existence. Altavista had the greatest impact in the period 1996-98, but its owners fumbled its intended transition from gratis service to 'monetiser' and 'wealth-generator'.
The Web of the mid-1990s was successful because it was very, very simple. A decade later, the Web is still nowhere near the sophisticated eLibrary envisaged by Bush, Engelbart and Nelson - the pioneers of hypertext between 1945 and 1970. Hordes of eager innovators are tugging and bullying the Web towards information services that are certainly more sophisticated, but crucially are more commercially profitable. Google is one of those innovators.
Google Inc. was established only in 1998, as a late entrant in the search-engine stakes. Users liked the company's service because it looked straightforward, and provided rapid response. The company attracted venture capital, achieved brand-recognition, projected an image of corporate responsibility, and 'captured eyeballs'. It was soon indexing a larger proportion of the Web than its competitors. By appearing to be reliable, and offering a user-interface that is (or at least has been) uncluttered by flashing banners and 'pop-ups', it sustained and expanded its user-base, grew very rapidly, and achieved dominance.
The company then raised huge amounts of cash through public share-offerings, enabling it to maintain and expand its index of vast volumes of data, and invest in growth through both R&D and acquisitions. It has generated substantial revenue based initially on targetted advertising, then on auctions of Adwords (Coy 2006) and later also on intermediated advertising through its Adsense service. There have been some hiccoughs, in particular concerns about 'click fraud' (e.g. Mann 2006), with a recent case reported to have gone against Google (Mills 2006). But such problems appear to be doing little to stem the flow of revenue.
Google Inc. has diversified into a wide range of additional lines of business (as catalogued by itself, and by Wikipedia). Some of those businesses it has developed, variously by replicating existing ideas but adding new features, by outright innovation, by purchase and takeover. Consistently with conventional business strategy, these lines of business generally appear to be intended to 'cross-leverage' one another.
This paper reflects the state of play during April 2006. Multiple announcements occurred during the few months between the paper's initial drafting and its finalisation. It's unlikely that Google's portfolio as at the end of April has been fully reflected, and certain that further relevant developments will occur shortly, even while the article is in press.
For the purposes of the analysis conducted in the later parts of this article, it is useful to cluster Google's services into three segments, focussed respectively on discovery, content, and data about users.
Google's foundation service was, and remains, its search-engine. One of its apparent advantages is that its web-spider, called Googlebot, accesses a substantial proportion of the content that is accessible on the Web (i.e. it has a very well-developed Reference List). Googlebot re-visits sites at intervals that depend on the company's (automated) assessment of the popularity and frequency of update of the particular site. To cope with the vast scale of the undertaking, the spidering activities are performed continuously by a substantial number of devices.
Google's Query Engine is designed for speed rather than power: its enquiry language is among the weakest of all such products. This reflects the company's intention to appeal to the masses, rather than to the librarian or even the moderately well-educated researcher.
The Results Formatter, on the other hand, is an area in which Google's demonstrated performance has excelled. Given the massive scale of the Web, most search-terms generate very large numbers of 'hits'. The key challenge is to identify pages that are most likely to be of interest to the user. Google's particular 'precedence algorithm' or PageRank technique sorts the hits into a sequence that is usually helpful, and sometimes uncannily accurate. Some years ago, the company cheekily began offering an 'I feel lucky' option, which delivers the page that comes first in its rankings. On the one hand, this reflects the fact that a very large proportion of users are entertainment-oriented surfers rather than people on a mission to discover specific information; but, on the other, it signals the confidence that the company has in being able to frequently deliver something that its user will perceive to have value.
The company has developed a range of extensions to the basic service. Many of these are merely restrictions of the search-space to sub-sets of the index, such as searches only for images, or only of blogs. A variant is the experimental Froogle service, which invites searches for items for sale, and tries to restrict hits to suppliers of goods and services.
Any web-site that has attracted the attention of Googlebot can offer its visitors a local site-search. This takes about half-an-hour to implement, and is valued by the many small organisations and individuals who manage web-sites that have enough content that hierarchical menus are no longer a sufficient navigation mechanism. The availability of this service has recently been formalised as 'Customizable Google Free Site Search', with the apparent intention that it become a commercial service, or at least a somewhat controlled one.
A recent experimental extension of particular interest is Google Scholar. In this case, the search is restricted to materials of relevance in the academic world. This service differs somewhat from other scope-restricted searches in that it has been necessary to ensure that the crawler visits appropriate sites; and features have been added, such as a citation-count for each paper, and navigation to the papers that cite it.
An adjacent business line is Google Answers, which involves the company operating as an intermediary between consumers who want specific research undertaken, on the one hand, and suppliers claiming to have the expertise to perform such research. As with the search services more generally, Google was a late entrant into this market, but may be gaining market-share.
During its early years, Google won high marks from users for not massaging content or lists of hits (other than to the extent that its PageRank system has that effect). It was also viewed positively for being generally sympathetic to open information flows, and for not imposing censorship.
There is evidence of ongoing resistance by Google to government attempts at censorship, at least within the USA. For example, alone among the main players, it refused to yield up a sample of search-terms to assist the US Administration to analyse compliance with the much-disputed Child Online Protection Act (COPA). The initial ruling in the case by the US District Court for the Northern District of California, handed down on 17 March 2006, required Google to hand over the addresses of 50,000 randomly selected websites indexed by its search engine, but not a sample of the search terms used by site visitors (e.g. Sampson 2006).
On the other hand, there are claims that its rank-ordering mechanism is not even-handed. Because users are known to seldom follow very far down the list, giving a page a low rank opens any search-engine operator to accusations of bias, and perhaps censorship. An advice site for parents called KinderStart.com recently filed suit for violating its constitutional right of free speech, apparently because Google applied its known policy of penalising companies who try to trick the system into giving their sites a high ranking (Liedtke 2006).
Whether or not the KinderStart action has merit, Google is seen by some at least to be succumbing to government interventionism in content-offerings, which is substantial worldwide, and has been increasing. For example, like its competitors, Google filters pro-Nazi sites in Germany and France. This may be a legal requirement to the extent that the company operates in those countries. But it has also been accused of submitting to demands that are not well-founded in law (e.g. Faris 2005, McCullagh 2006a). The second of those articles resulted in a turnaround the following day (McCullagh 2006b). Nonetheless, particularly in the case of the PRC, Google is widely regarded as being at least complicit in large-scale content censorship
Without yet quite becoming a content-provider, various of Google's services are moving beyond mere discovery of content provided by others.
One extension of particular interest and value is Google News. This might be described as a news-report consolidation service. It provides users not only with links to recent news reports, but also allows a degree of customisation of the selection, and displays from Google's own cache the headline, source, and first line of text. This is discussed in more detail below, because of the negative reactions of some of the corporations whose content it draws on.
Another extension that merges into content-provision is Google Earth. This provides satellite imagery of the earth's surface, already at fairly high levels of resolution, although currently of uncertain age. It is accompanied by client-side software, and offers several levels of service and data precision, some gratis and some for-fee.
A further service called Google Base provides a gratis content-hosting service. The basic free-text search capabilities can be enhanced with metadata. Google Inc. appears to be adopting the role of publisher. It declares Editorial Guidelines and Program Policies, including the statement that "We reserve the right to exercise editorial discretion when it comes to the items we accept on our site".
Similarly, the emergent Google Video business line involves upload of the file to Google's servers, and the associated documents include reference to "our approval process". The Policy and Copyright Issues page includes the statement that "Currently, we conduct a preliminary review of videos for pornography or obscene material".
A particularly important initiative that involves content on a very large scale is Google Library, which is part of a broader Google Print project. This scheme, in collaboration with five leading libraries, involves the scanning of many books, the extraction of the text, the indexing of that text, and support for users in discovering segments of that text that satisfy their search-terms. This is also re-visited below, because of the furore it has unleashed.
The third cluster of services was summed up in a statement by Google's CEO to financial analysts: "We are moving to a Google that knows more about you" (reported in The New York Times of 10 February 2005, and subsequently in many other places).
The foundations for this are provided by the search-terms that each user keys into the search-form, and that are stored by Google. The search-terms are associated with the IP-address from which the user accessed the search-engine. Google encourages consolidation of the data against a username, by offering Google Accounts, and 'Personalizing Services'. The username is the individual's email-address. This is convenient for both the user and Google Inc., although for different reasons.
Google's basic services therefore provide the company with substantial and potentially sensitive information about its users, which generates opportunities for substantial financial returns. But the company is making sure that there will be more, of both.
One line of development was signalled by the launch in 2004 of a gratis web-mail service dubbed GMail. This has features that differentiate it from its predecessors such as Hotmail and Yahoo. One feature is huge storage space, which enables long-term retention of messages. Another is the auto-selection of ads for display to the subscriber. The impression given by the original announcement was that the selection criteria are based on text in the message from the subscriber's correspondent, but they could easily be upgraded to also reflect the subscriber's accumulated profile.
Another relevant business line is Google's offering within a recently-emerged category of web-based services. So-called 'social networking services' (SNS) have exploded in a manner reminiscent of the halcyon days of the mid-to-late 1990s, before 'the dot.com bust'. An SNS provides space where people can establish and expand networks of human contacts. It involves participants creating profiles for themselves that are variously straightforward, creative and downright dishonest. The orientation of such services ranges from social to business, and their functions include flesh-markets for new human relationships, for new employees, for new customer-supplier relationships, and for new strategic partnerships. Google's entrant in this market is called Orkut. Information about the features of the scheme appear to be available only to subscribers.
But these are mere side-plays. The key service in this cluster is Google Desktop. Tools to provide search capabilities across the user's own storage have been available for some time. For example, Apple delivered a tool on its Macintoshes in 1998 as Sherlock, more recently as Spotlight. A Microsoft offering for the dominant Wintel workstation environments is still awaited, and third parties have been busily filling the vacuum. Google is seeking to leverage off its recognition as the dominant search-tool on the public Web to become the dominant search-tool for users' private holdings as well.
When first launched, Google Desktop appeared to run entirely on the user's own machine, without any linkage out to Google's site, and no access to the data by Google Inc. But there was very little to ensure that this remained the case. As late as March 2006, the Google Desktop Terms and Conditions still contained no link to any Privacy Policy, and were easily read as enabling Google to use any personal data that it gathered in any manner it sees fit, now or at any time in the future.
Sure enough, on 9 February 2006, when Google released Desktop version 3, it included an extended service, called Search Across Computers. To deliver that service, Google transmits copies of users' files to Google servers, and keeps them there. This is a vast amount of personal data, that is in part sensitive, and which as a whole is sensitive. And it is largely unprotected by US law.
A Google executive was quoted as saying "We think this will be a very useful tool, but you will have to give up some of your privacy" (Hearn 2006). Centralised storage in Google servers may be a simple approach to providing a search-service that extends across multiple devices; but, contrary to Google Inc.'s implications, it is not necessary. As commentators quickly pointed out, the reason for it is to provide Google with control over people's devices and data. Microsoft tried a similar manoeuvre some years ago with its Passport service, and failed. Google clearly hopes that its offer will be more compelling, and that people everywhere will donate to Google every piece of data that they possess.
A further signal of Google Inc.'s intentions is its successful tender to the City of San Francisco to provide city-wide wireless access (e.g. Kopytoff 2006). The technology (understood to be Wifi, aka IEEE 802.11b/g) would enable the company to identify the user, to know the user's location within perhaps 50 metres, and hence to track the user's movements around the city. The Google service is to be available gratis, and funded through advertising. The information at the company's disposal is so rich that it can very accurately target the ads at each person's interests, and location.
These large, expanding and mutating clusters of services pose challenges to the interests of the many different categories of party that have an interest in contemporary electronic publishing. They also pose challenges to the operation of the law. This paper considers four key areas, the first being competition law.
Google dominates search-engine usage, particularly for the general public. But it is far from alone, and it does not appear to have any natural advantage that makes its market uncompetable. Most of its other lines of business, such as Earth, Orkut and Desktop, also do not have the field to themselves.
The limited resources of corporate regulators tend to be focussed on corporations whose dominance of a market segment arises from abuse of market power, rather than primarily because of the slowness or dullness of their competitors. Unless and until it is evident that Google has acted illegally, or has achieved monopoly-positions that are unable to be broken, regulators are unlikely to meddle with a corporation that is an investor's darling (busily 'generating wealth' - whether real or merely apparent), that is very large, and that possesses a great deal of cash to finance lawsuits and lobbying.
Google's moves into content, on the other hand, have given rise to concerns in some quarters that digitisation of old works creates the risk of some kind of monopoly over the content of published works, and hence of monopoly rents; and, worse yet, that the benefits might accrue to the wrong monopolist. There have been prior initiatives to digitise the world's literature, starting with Project Gutenberg in 1971. These were generally communitarian in nature, and not well-funded. But Google's deal with major libraries has stimulated parallel initiatives. One that appears to be head-to-head competitive is the joint project between the British Library and Microsoft announced in November 2005. Others are competitive with Google but collaborative among multiple players, such as the European Digital Library mooted in May 2005, and the Open Content Alliance (OCA) announced in October 2005.
Particularly in view of what might be a virile response from elsewhere in the private sector, it is not clear that a reasonable argument can be mounted that Google's Print and Library campaigns are anti-competitive. That view would need to be revised if, for example, Google were able to use its patents on scanning technology to lock competitors out of the market for an extended period. Otherwise, it would appear that this may emerge as a classic case of that (remarkably uncommon) phenomenon of successfully exploited first-mover advantage.
Although Google does not appear to currently pose major problems for competition law, the discussion of anti-competitive effects in relation to content draws attention to copyright law. It is therefore appropriate to consider that area next.
There are multiple facets of the collision between Google and the various forms of what it has become fashionable (and dangerous) to refer to as 'intellectual property law'. This section begins with a brief survey of copyright issues in the normal operations of search-engines. It then considers trademark aspects, and copyright impacts of Google's emergent content-publishing roles. Finally, conflict is identified between Google Inc.'s interests and those of major publishing corporations.
The mechanisms underlying the Internet in general, and the Web in particular, involve multiple copies being made of a file that is in most cases probably also a work (or works) for the purposes of copyright law. It is fairly easy to infer, however, that publishers of Web-pages, to the extent that they have the legal capacity to do so, grant a licence to the user of a web-browser to make such copies as are necessary for the operation of the Web.
But a web-crawler is not a web-browser, and its operations are not intrinsic to the operation of the Web. Hence, from the very beginnings of search-engine operations, there was considerable potential for their fundamental practices to be found to be copyright-infringing. In particular:
Reproduction of limited amounts of the content of each item is readily argued to be fair use or its equivalent. Further, web caching by 'online services providers' is generally protected in the U.S. under provisions of the Digital Millenium Copyright Act (DMCA) of 1998. This includes temporary caching for indexing purpose, which was approved, in the US at least, in 2002 in Kelly v. Arriba Soft Corp., (336 F.3d 811 9th Cir., 2003). Several subsequent cases have been reported in which Google's cache has been determined to be non-infringing (e.g. Bangeman 2006).
Google's service goes further than other search-engines, however, by also making files in its cache available to searchers in their entirety. A recent report suggests that US courts are increasingly approving not only of the existence of Google's cache, but also of links to items in that cache (von Lohmann 2006). It remains unclear, however, whether the courts will interpret all uses as being permitted, particularly third-party access to the cached file when the original file is accessible (Bercic 2005).
One factor that may be considered by the courts is respect for express denials of consent. Such denials can be found in the 'exclusion clauses' stored in robots.txt files on Web-sites. Google declares that it respects exclusion clauses, and it appears to do so. Another factor is the availability of opt-out for long-term caching, which may be enough to relieve a search-engine operator of liability for copyright infringement (Olsen 2003). On the other hand, doubts remain (e.g. Steward 2005).
American law has shown itself capable, on at least some occasions, of adapting reasonably quickly, and finding a balance appropriate to new capabilities delivered by new digital technologies. This is predicated, however, on very large dollops of money being available to support the necessary lobbying and to pursue test-cases. And it is not clear that the adaptations will be mirrored in other countries.
A brief note is necessary in relation to trademark battles. The Adwords technique used by Google enables advertisers to gain priority display-space when particular search-terms are nominated by the user. Trademarked terms have been used, and not infrequently acquired by competitors to the trademark-owner. In late 2003, a French tribunal held that Google France infringed registered trade marks in this manner. A similar decision in the U.S. Court of Appeals (9th Circuit) was reported in early 2004, although relating to another search engine (e.g. Tyacke & Higgins 2004, Atlee & McMahon 2005).
Even if Google's foundation services prove to be acceptable to the courts, some of its extensions into content may not. Google News came under attack in the courts in March 2005 by Agence France Press, which believes that the manner in which the service is designed infringes its copyright (e.g. Wright 2005). This point of view has gained support from the Paris-based World Association of Newspapers (WAN-Press 2006).
In another action, a litigant recently won an injunction against Google's practice of creating thumbnails of images it finds on web-sites (McCullagh 2006c). The judge was reported as saying that "[Google provides] an enormous public benefit, [but] existing legal precedents do not allow such considerations to trump copyright law".
The Google Earth web-site is almost devoid of information about copyright, or even terms of use, although marks asserting Google's ownership of copyright appear on many images. It appears that the service has been structured using conventional contract, agency and copyright licensing agreements. If that assumption is correct, then it would be reasonable to expect that such copyright disputes as arise in relation to the use of Google Earth will be settled under existing laws.
But that appears not to be the case with at least some of the complex of services in the Google Print / Google Library cluster. In many cases (e.g. out-of-copyright works held by organisations such as the Bodleian Library, and works for which the copyright-owner provides an appropriate licence), there would appear to be no sense in which the Google Library initiative is doing anything unusual, or could reasonably be claimed to infringe copyright law.
Some uncertainties exist in relation to works whose copyright-ownership is uncertain or whose copyright-owner cannot be contacted ('orphan works'). A recent report by the U.S. Copyright Office recommended amendments to the Act to require that 'reasonably diligent' search for the copyright-owner be undertaken, and that appropriate attribution be provided, but combined with limitation of remedies in such circumstances to 'reasonable compensation for use' (USCO 2006).
Far more contentious is Google Library's handling of works that are in-copyright, whose copyright-owners can be located, who have not provided licences, and who are not prepared to do so. (Copyright law does not provide for generic compulsory licensing, and hence in most circumstances a copyright-owner is able to refuse to provide a licence). Most of Google's partners appear to be restricting the arrangement to out-of-copyright books. But at least one is making in-copyright books available for scanning. The University of Michigan Library states that "Google will digitally scan and make searchable virtually the entire collection of the U-M library". It very much appears that Google is flexing its now-considerable muscle and proposing to scan, index and enable search over copyright works.
This undertaking involves at least the following steps that can be argued to breach copyright:
Unsurprisingly, the aggrieved have resorted to litigation to defend their position. Two separate actions have been launched in the U.S. District Court, one in September 2005 by the Authors Guild (Authors Guild v. Google Inc., No. 05 CV 8136, USDC SDNY 20 September 2005), and the other in October 2005 by five major book-publishers (The McGraw Hill Companies Inc et al v. Google Inc., 05 CV 8881 US DC SDNY 19 October 2005, discussed in TechLawJournal 2005 and Band 2006). The locations of the protagonists' Head Offices and of the lawsuits could hardly be a better vindication of the Lessig (2000) thesis about 'West Coast Code vs. East Coast Code'.
The copyright and trademark wars are far from over, as Google continues to push at the boundaries.
Most content-expressors want to retain control over at least some aspects of the content that they create. Copyright law has long provided rights to originators over copying and republication, over adaptation, and over republication of adapted works. But large, for-profit corporations have been attracted by the high-margin revenue that a monopoly enables, and they have come to control much of the content that is in demand, or that can be used to stimulate demand. By dominating channels to market, corporations have increasingly relegated individual originators to the role of employee or contractor.
In addition, a few forms of content (such as feature films, light entertainment series, and animation) require considerable investment, and result from creative work by teams rather than by a single primary originator. As a result, the various copyrights in such works are commonly owned by corporations from the outset.
The digital era has delivered new capabilities that have tended to reduce the scope for copyright-owners to exploit their monopoly. To counter this, the rich and powerful music and film industries have lobbied the U.S. Administration and Congress for substantially greater rights, for longer periods.
Protection of American corporations' investments in copyright and patents has been a national strategic priority since at least the Carter Administration (e.g. Heald 2005). In a turnaround from its nineteenth century position as a nation of copyright-breachers (e.g. Kahn 2004), the U.S. now dominates the generation of new ideas, and of innovation using them. It stands to gain from the provision to copyright-owners of much more substantial monopoly protections. So it has transformed copyright law from an innovation-motivated balance between the interests of owners and of users, to something much closer to a simple owner-monopoly.
The revenue-flows of U.S. corporations cannot be protected by U.S. law alone; so the U.S. Administration wants the world to fall into line with its new notion of copyright law. Remarkably, other parliaments appear to be unaware of their own nations' self-interests, and are succumbing to the USA's various multilateral and bilateral machinations to achieve alignment and harmonisation, or to simply impose their version of copyright law on other countries. In 2004, the Australian Government, an ultra-loyal ally in American foreign policy, ignored or was ignorant of the country's economic interests and was among the first to fall into line, through its acceptance of U.S.-dictated terms in the US-Australia 'Free Trade' Agreement.
As a result of these changes, novels, biographies, instruction manuals, learned works, sound-recordings, images and videos are subject to stronger and longer monopoly than has ever been the case in the past. The corporations that control large libraries of copyright materials have been granted greatly enhanced capabilities to wield market power over both consumers and content-intermediaries.
Opposition to this copyright expansionism has been evident for many years, e.g. Barlow (1994), Samuelson (1996), Lessig (2000), Zittrain (2003), Adelphi Charter (2005). The US-Australia FTA also drew vocal opposition, which was ignored by the Government and the Parliament. See Clarke (2004b). These opponents have argued against the 'corporate welfare' approach to copyright law, based on economic and social perspectives, and in particular on the vital role of free flows of information as an enabler of innovation.
The opponents of copyright expansionism have found an unlikely bedfellow. Copyright monopoly power is against the interests of the young, busy and rich Google Inc., dependent as it is on developing innovative, new services relating to content, copyright in which mostly belongs to other people. Although only formed in 1998, the company is already in excess of $5 billion annually in advertising revenue. Its allure as an investment gave it a market capitalisation in the second half of 2005 of $125 billion. On that measure, it is among the top 100 corporations worldwide. (If a comparison with GDP were meaningful, that would make Google larger than all but 35 of the world's c. 200 nations - falling between Malaysia and Argentina).
Google is a 'newly big business'; and its interests are strongly divergent from those of 'old big business'. Whereas 'old big business' sits fatly, exploits its monopolies and arranges extensions to them, 'newly big business' makes its money by adapting quickly to new contexts in order to realise the potentials lurking inside them, and creating new monopolies that it can dominate from the outset. Considerable, expensive action can be confidently anticipated, in courts of law, in the media. and in the offices of Ministers and accessible Parliamentarians.
From the preceding discussion of copyright laws, it might appear that Google's interests are aligned with those of content-accessors. On the other hand, the following section considers the challenges that Google presents to consumers and consumer protection laws.
The Web and search-engines began life in the mid-1990s as gratis services, socially-oriented, and socialist or communitarian in nature. The patterns have changed a great deal during the following decade, as business enterprises have sought ways to make money from the vast volumes of content and traffic. The social dimension is far from dead, but there is now a substantial economic dimension that is trying to swamp it.
Even since the commercialisation of the Internet, consumers have benefitted greatly from the Web, and the flood of readily accessible content made available on it. Search-engines, not least Google, have made golden needles discoverable within an increasingly large haystack. The first round unarguably brought massive consumer benefit, particularly given that the actual access to content was gratis - at least for those people with the necessary infrastructure available to them.
But the contemporary context is profit-oriented to the point of being seriously anti-social. It's therefore necessary to consider the extent to which the interests of consumers are holding up against the interests of the generally much more powerful corporations that control much of the available content. Of particular relevance are the interests of the less powerful consumers that are Google's primary target-market - individuals, small business enterprises, and associations.
In many circumstances, consumer rights are simply not respected by commercial providers of content on the Web. Commonly, terms are not negotiable, and in many cases are not even transparent. They are changeable at short notice. They do not survive takeover, or even change in management, or just in management policy. Old versions of terms are simply over-written, and cease to be discoverable. Communications from consumers to providers are ignored, and in many cases barriers are created to make it difficult for the consumer to work out how to send them in the first place. Recourse and enforcement are almost non-existent, not only across jurisdictions, but even within historically consumer-friendly jurisdictions. One interpretation is that the U.S. has successfully exported its marketer-friendly / low-regulation / consumer-hostile approach to the rest of the world.
Google looms as one of the most arrogant of the new generation of content-intermediaries, and appears set to carry its attitudes across into its content-provision business lines. Its terms are abrupt and invariant. Changes are made without notice, as the company sees fit: "We reserve the right to modify these Terms of Service from time to time without notice". Changes are not shown, no version-number or effective-date is provided, and prior versions are not available. Consumers who use the Adsense facility find similarly hostile terms, and inflexible application of them, as the company sees fit, without correspondence being entered into. Its terms for Gmail are particularly draconian.
No expansion of consumer protection to cope with these abuses is currently in prospect. As copyright-owners and their agents increasingly flex the powers granted to them by the U.S. Congress and subsidiary parliaments such as Australia's, the interests of content consumers seem likely to be lost in the surge of copyright supremacist activity. There is little comfort to be had in the recent Tunis Declaration of the World Summit on the Information Society that "We call for the development of national consumer protection laws and practices, and enforcement mechanisms where necessary ..." (WSIS 2005, para. 47), not least given that the document was published by the International Telecommunications Union.
The final section shifts from the economic dimension of content-access and consumption to the social dimension, and considers the challenges that Google presents for privacy law.
The Web and search-engines have delivered enormous benefits; but they have also undermined the longstanding protection of 'privacy through obscurity'. The risk is compounded by the emergence of long-term archival services, such as the Internet Archive Wayback Machine. See, for example, Clarke (1998, 1999), Noguchi (2004) and Aljifri & Sánchez Navarro (2004).
Since the 1980s, electronic data discovery services have been targeted at debt collectors, private detectives and criminals. The Web has increased the market reach of longstanding services, many of dubious legality, such as DebtDIY. But the Web has also resulted in the electronic publication of a flood of other personal data, such as postings to lists, fora and blogs, mentions in the media, records of participation in events, letters to the editor, and court reports. These are discoverable through search-engines, and many people now take advantage of the new opportunity. A new breed of specialist services has been launched, such as ZoomInfo, the most successful of which will doubtless be mopped up by Google in the near future. The motivations of the users of these services are variously constructive (e.g. to prepare for a forthcoming meeting) and otherwise (e.g. for stalking, harassment, and extortion).
The sensitivity of some the data is a serious concern. To that must be added the huge problem of pitifully low data quality. Web content is commonly out-of-date, incomplete, uncorroborated, unsourced, or lifted out of its original context without so much as a reference to what that context was. Inevitably, many of the hits are spurious, and relate to another person with a similar name. Some of the content is inaccurate, and some is mischievous or downright scurrilous, as captured by the sceptical epithet 'It's on the Web; it must be true'. The case study of the John Siegenthaler entry in Wikipedia, in May-December 2005, highlighted both the weaknesses and strengths of the Wikipedia model and process, and the necessity of scepticism when reading web-content.
The Google search-engine is the most intrusive of all Web facilities. The foundation is laid by the size of its cachement. But the company has exacerbated the problem by providing many additional services and ensuring that data arising from the use of each of them is able to be correlated with that arising from all of the others.
Given the privacy-threatening nature of its data practices, it would be reasonable to expect that Google would be especially careful in its structuring of privacy protections. But that is not the case: its Privacy Policy falls far short of people's needs.
As at mid-December 2005, Google provided a master Privacy Policy statement, and a shorter version called Google Privacy Policy Highlights. These appeared to apply to all services, including the search-engine and all restricted-search services. There was a supplementary statement for Google Desktop, but none at that stage for Google Earth. Google Print and Google Groups had their own, but they appeared to be merely copies of the master statement.
An analysis of Google's master Privacy Policy statement identifies many serious causes for concern (Clarke 2005). Google's use of cookies is extremely intrusive. Any and all of the personal data that it has available is used for the "display of customized content and advertising". The company misunderstands (or abuses) the concept of 'consent'. Data disclosure to affiliates is uncontrolled. Data appears to be retained indefinitely, and the claim is made that, even if someone requests deletion of specific data, the request can be declined if the company wants to keep it for "legitimate business purposes". In any case, it appears unlikely that the undertakings could be enforced, especially not by individuals. The U.S. has only an extremely watered-down version of genuine privacy protections called the 'Safe Harbor Privacy Principles' (DOC 2000a), and U.S. federal agencies have been highly unhelpful to consumers, as evidenced by the vacuous advice in FAQ No 11: Dispute Resolution and Enforcement (DOC 2000b).
It gets worse.
There is a supplementary privacy statement for Orkut. Google would appear to be free to apply to its own purposes personal data provided to Orkut, including inter-subscriber messages, and the membership of social networks. Some 'social networking services' entice users to disclose personal data about their friends, business contacts or acquaintances, and even to upload their complete address-book (Clarke 2004a). It is unclear from the limited information that is openly available whether Orkut indulges in that practice.
Gmail is a special case that requires closer attention. The privacy implications of email are often overlooked. Most email content was written in unguarded moments, in expectation of limited distribution and ephemerality. The expectation may prove to be unwarranted, because there is an increasing risk of email becoming available to indexing software. For example, private email may escape onto lists by being forwarded by recipients to other parties; and it may be subject to pre-trial discovery, sub poena or search warrant, and hence find its way into court records. It is also increasingly subject to extremist, largely uncontrolled 'anti-terrorism' powers that parliaments in the USA, parts of Europe, and Australia have granted to national security and law enforcement agencies.
Every user's Internet Access Provider (IAP) maintains logs of traffic, in some cases including content. Every user's email-Internet Service Provider (ISP) maintains an email database. In the case of webmail-only services (such as Hotmail, Yahoo and GMail), the retention-period is highly uncertain. In all of these cases, the traffic-details and text are subject to unexpected use and to both legally authorised and unauthorised disclosure, often without notification to the individuals who thought it was 'their' mail.
Google's Gmail represents the extremity of untrustworthiness in email-provision. It was the subject of an open letter from Privacy Rights Clearing House at the outset in 2004. Detailed analyses are in Templeton (2004) and EPIC's FAQ. Gmail subscribers are subject to targeted ads based on text from senders. Google is in a strong position to correlate the ads with other data it holds, including, if and when it chooses to do so, with the content of outbound emails. It also has ready access to the social networks that the individual belongs to. How rich a profile does an advertiser need to enable the manipulation of consumer behaviour, and to become a honeypot that attracts interest from other marketers, and from law enforcement and other government agencies seeking specific personal data to extract, and large datasets to mine? The company refuses to explain the circumstances under which it releases its subscribers' information, and the number of occasions on which it has done so.
Importantly, the privacy threats are not limited to Gmail subscribers. The messages that people send to Gmail addresses are examined, they are retained long-term, the content and email-address are subject to largely uncontrolled use and disclosure, and correspondence with someone is enough to enable an inference of association with a social network.
The doctrine of privity of contract and the manifold weaknesses and patchiness of privacy laws together suggest that people who send messages to Gmail addresses simply have no rights at all in relation to the content of those emails. Consequently, some people decline to send to Gmail addresses. Many more would be likely to do so if they fully appreciated the risks that they face.
The whole is far greater than the sum of the parts. Google is structuring its business portfolio in order to achieve cross-leveraging. The consolidation of information about the behaviour of users of multiple Google-provided services is a particularly valuable form of cross-leveraging. At this stage in its development, Google Inc. has at least the following streams of data about its users available to it:
There is no evidence that the Google corporation has yet moved to bring the full power of data mining technology to bear on this rapidly growing mound of data. But that would in any case be a strategically unwise manoeuvre at this early stage.
US privacy laws remain very limited, and largely unenforceable. The impetus that was building towards generic privacy legislation in the US (e.g. Clarke 1999) was interrupted by the terrorist attacks of September 2001, and has only recently resumed (e.g. Economist 2005). Google Inc.'s vast hoards of personal data are available for exploitation by the company, its business partners, and governments with which it is friendly, or with which it chooses to cooperate. When the company chooses to make its move, neither its privacy policy nor the law will represent any significant barrier to its freedom of action.
The previous sections have demonstrated that Google Inc. is posing substantial challenges to the law. But the challenges to the company's competitors are more forthright. Google is a newcomer to the big end of town. New money is always brash; but Google is big new money. The courts are assured of good sport in the next few years, as corporations that are dependent on copyright-monopolies take up Google's gauntlets. Elephants will be battling over copyright, and perhaps over aspects of competition law as well.
The apparent alignment of user interests with Google in the copyright arena does not carry over into consumer rights and privacy. The early, socially-oriented era of the Web is being swamped by the contemporary dominance of corporate interests. The tensions among human, corporate and government interests on the Internet are now very high, and are mostly being resolved against the interests of individuals. There is little sign of collective organisation among consumers of Internet services, although occasional breakouts in community fora do force minor adjustments to corporate positions.
There are continual reports in the media to the effect that Google Inc. abides by its alleged motto "You can make money without doing evil". Those reports are seriously misleading. If their premise were true, then the company would be being put to the test, as its growth and diversification put enormous temptations in front of its executives.
For example, there is increasing suspicion that the rank-ordering algorithm is being compromised in order to advantage paid advertisements over unpaid hits. Two further examples arose as this article was being prepared. Reports were published of a deal between Google and Time-Warner that included "a plan that may display more graphical ads on some of Google's traditionally sparse Web pages" (Liedtke 2005). This would perhaps not be 'evil', but it would certainly be a departure from one of the highly-valued features that underpinned the service's explosive growth. The second example related to inflated click-through statistics in the Adsense program (Mann 2006).
An examination of Google's alleged motto is instructive. Google is emphatically not built on the normative statement that 'the company should not do evil'. Two variants are evident on the web-site. One is merely as number 6 of 'Ten things Google has found to be true', and the statement is actually descriptive, not normative: "you can make money without doing evil". The other variant is the statement "Our informal corporate motto is `Don't be evil'". This is vague and completely non-binding. It appears as part of a so-called `Code of Conduct' which, firstly, appears in the `investor' part of Google's web-site rather than being communicated to customers, and, secondly, omits any form of protection for the company's users. (The Code arguably provides far more protection for cats than for users, in that para. IIe flippantly warns them off Google Inc. premises).
Google Inc.'s aphorism about evil has an apposite corollary: "You can make money without doing evil; but you can make more money by doing evil". On that basis, and given the obligations of corporations under law, the epithet arguably implies that evil should be done. Google Inc. would rationally see it as being in the company's best interests to gather more personal data, to cross-correlate it, to mine it, to exploit its users, and indeed to exploit anyone else who falls within the scope of its increasing market power.
Consumer, beware. But Google is big enough, and virile enough, that major corporations that are dependent on monopolies provided by copyright, and by copyright law extensions, need to be wary too.
Adelphi Charter (2005) 'Adelphi Charter' Adelphi Charter Commission, 2005
Aljifri H. & Sánchez Navarro D. (2004) 'Search engines and privacy' Computers & Security 23, 5 (July 2004) 379-388
Atlee S.D. & McMahon B.F. (2005) 'Search Terms: The Use of Trademarked Terms by Web Search Pages Has Challenged Traditional Boundaries of Trademark Protection' Los Angeles Lawyer 28 (November, 2005) 38
Band J. (2006) 'Copyright owners v. The Google Print Library Project' Ent. L.R. 2006, 17(1), 21-24
Bangeman E. (2006) 'Google cleared in cache copyright case, forced to hand over e-mail in another' Ars Technica, 17 March 2006
Barlow J.P. (1994) 'The Economy of Ideas: A framework for patents and copyrights in the Digital Age' Wired 2.03 (March 1994)
Bercic B. (2005) 'Protection of Personal Data and Copyrighted Material on the Web: The Cases of Google and Internet Archive' Information & Communications Technology Law 14, 1 (March 2005) 17-24
Clarke R. (1998) 'Information Privacy On the Internet: Cyberspace Invades Personal Space' Telecomm. J. Aust. 48, 2 (May/June 1998)
Clarke R. (1999) 'Internet Privacy Concerns Confirm the Case for Intervention' Commun. ACM 42, 2 (February 1999) 60-67
Clarke R. (2004a) 'Very Black 'Little Black Books' Xamax Consultancy Pty Ltd, February 2004
Clarke R. (2004b) 'The Free Trade Agreement Provisions in Chapter 17 relating to Copyright and Patent Law' Submission to the Joint Committee on Treaties, Xamax Consultancy Pty Ltd, 6 April 2004
Clarke R. (2005) 'Evaluation of Google's Privacy Statement against the Privacy Statement Template of 19 December 2005' Xamax Consultancy Pty Ltd, December 2005
Coy P. (2006) 'The Secret To Google's Success: Its innovative auction system has ad revenues soaring' Business Week, 6 March 2006
DOC (2000a) 'Safe Harbor Privacy Principles' U.S. Department Of Commerce, 21 July 2000
DOC (2000b) 'FAQ No 11: Dispute Resolution and Enforcement' U.S. Department Of Commerce, 21 July 2000
Economist (2005) 'Demon in the machine: Privacy laws gain support in America, after a year of huge violations' The Economist, 1 December 2005
Faris S. (2005) '"Freedom": No documents found' Salon, 16 December 2005
Heald P.J. (2005) 'American Corporate Copyright: A Brilliant, Uncoordinated Plan' Journal of Intellectual Property Law 12 (2005) 489
Hearn L. (2006) 'New Google feature has strings attached' The Age, 9 February 2006
Kelly v. Arriba Soft Corp., 280 F.3d 934 (9th Cir. 2002)
Khan B.Z.Z. (2004) 'Does Copyright Piracy Pay? The Effects of U.S. International Copyright Laws on the Market for Books, 1790-1920' Working Paper No. W10271, U.S. National Bureau of Economic Research, January 2004, at http://ssrn.com/abstract=495776
Kopytoff V. (2006) `Wi-Fi plan stirs Big Brother concerns ?Log-on rule would allow Google to track users' whereabouts in S.F.' San Francisco Chronicle 8 April 2006, at http://www.sfgate.com/cgi-bin/article.cgi?f=/c/a/2006/04/08/BUGROI5S5J1.DTL
Lessig L. (2000) 'Code and Other Laws of Cyberspace' Basic Books, 2000
Liedtke M. (2005) 'America Online, Google seal $1B deal' Business Week, 20 December 2005
Liedtke M. (2006) 'Web site files complaint against Google' SiliconValley.com 17 March 2006
McCullagh D. (2006a) 'No booze or jokes for Googlers in China', News.com, 26 January 2006
McCullagh D. (2006b) 'Google fixes China search bugs' News.com, 27 January 2006
McCullagh D. (2006c) 'Nude-photo site wins injunction against Google' News.com, 21 February 2006
Mann C.C. (2006) 'How Click Fraud Could Swallow the Internet' Wired 14.01 (January 2006)
Mills E. (2006) 'Google to settle click fraud suit with $90m?' Silicon.com, 9 March 2006
Noguchi Y. (2004) 'Online Search Engines Help Lift Cover of Privacy' Washington Post, Monday, February 9, 2004; Page A01
Olsen S. (2003) 'Google cache raises copyright concerns' Cnet, 9 July 2003
Sampson G. (2006) 'Federal judge grants DOJ limited access to Google search records' Jurist 18 March 2006
Samuelson P. (1996) 'The Copyright Grab' Wired 4.01 (January 1996)
Steward S. (2005) 'The DMCA protects search engine page caching, indexing, etc.? Not so fast' O'Reilly Developer Weblogs, 7 November 2005
TechLawJournal (2005) 'Major Book Publishers Sue Google for Digitizing Copyrighted Books' TechLawJournal October 19, 2005
Templeton B. (2004) 'Privacy Subtleties of GMail' April 2004
Tyacke N. & Higgins R. (2004) 'Searching for trouble - keyword advertising and trade mark infringement' Computer Law & Security Report 20, 6 (November-December 2004) 453-465
USCO (2006) 'Report on Orphan Works' U.S. Copyright Office, 31 January 2006
Vise D. & Malseed M. (2005) 'The Google Story' Delacorte, 2005
von Lohmann F. (2006) 'Nevada Court Rules Google Cache is Fair Use', Electronic Frontiers Foundation, 25 January 2006
WAN-Press (2006) 'Newspaper, Magazine and Book Publishers Organizations to Address Search Engine Practices', World Association of Newspapers, 31 January 2006
Wright N. (2005) 'Copyright infringement case brought against Google by AFP' EarthTimes Sat, 19 Mar 2005
WSIS (2005) 'Tunis Agenda for the Information Society' World Summit on the Information Society, WSIS-05/TUNIS/DOC/6(Rev.1)-E ,18 November 2005
Zittrain J. (2003) 'The Copyright Cage' Legal Affairs, July-August-2003
Roger Clarke is Principal of Xamax Consultancy Pty Ltd, Canberra. He is also a Visiting Professor in the Cyberspace Law & Policy Centre at the University of N.S.W., a Visiting Professor in the E-Commerce Programme at the University of Hong Kong, and a Visiting Professor in the Department of Computer Science at the Australian National University.
My thanks to Matthew Rimmer of the Law Faculty at the Australian National University, who stimulated this paper by inviting me to present user perspectives in a seminar on 'Google: Infinite Library, Copyright Pirate, or Monopolist?', at the National Institute of Social Sciences and Law, A.N.U., Canberra, on 9 December 2005. My thanks also to the other presenters at that seminar, and for the challenges they presented, and to Prof. Graham Greenleaf of U.N.S.W., founder of the AustLII and WorldLII repository and retrieval services for legal resources, for his comments on an earlier version of this paper.
| Personalia |
Photographs Presentations Videos |
Access Statistics |
 |
The content and infrastructure for these community service pages are provided by Roger Clarke through his consultancy company, Xamax. From the site's beginnings in August 1994 until February 2009, the infrastructure was provided by the Australian National University. During that time, the site accumulated close to 30 million hits. It passed 65 million in early 2021. Sponsored by the Gallery, Bunhybee Grasslands, the extended Clarke Family, Knights of the Spatchcock and their drummer |
Xamax Consultancy Pty Ltd ACN: 002 360 456 78 Sidaway St, Chapman ACT 2611 AUSTRALIA Tel: +61 2 6288 6916 |
Created: 8 December 2005 - Last Amended: 2 April 2006 by Roger Clarke - Site Last Verified: 15 February 2009
This document is at www.rogerclarke.com/II/Gurgle0604.html
Mail to Webmaster - © Xamax Consultancy Pty Ltd, 1995-2022 - Privacy Policy