Roger Clarke's Web-Site
© Xamax Consultancy Pty Ltd, 1995-2024

Infrastructure
& Privacy
Matilda
Roger Clarke's Web-Site© Xamax Consultancy Pty Ltd, 1995-2024 |
|
|||||
| HOME | eBusiness |
Information Infrastructure |
Dataveillance & Privacy |
Identity Matters | Other Topics | |
| What's New |
Waltzing Matilda | Advanced Site-Search | ||||
Revision of 20 May 2016
Accepted for Proc. EISIC'16, Uppsala, 17-19 August 2016
© Xamax Consultancy Pty Ltd, 2015-16
Available under an AEShareNet ![]() licence or a Creative
Commons
licence or a Creative
Commons  licence.
licence.
This document is at http://www.rogerclarke.com/EC/BDQAS.html
The quality of inferences drawn from data, big or small, is heavily dependent on the quality of the data and the quality of the processes applied to it. Big data analytics is emerging from laboratories and being applied to intelligence and security needs. To achieve confidence in the outcomes of these applications, a quality assurance framework is needed. This paper outlines the challenges, and draws attention to the consequences of misconceived and misapplied projects. It presents key aspects of the necessary risk assessment and risk management approaches, and suggests opportunities for research.
A wide variety of data sources are applied in intelligence and security analysis, including open source intelligence, network traffic and social media postings. To the extent that the datafication of things and of people comes about, there will also be streams of data from eObjects (Manwaring & Clarke 2015). The US-originated literature is cavalier in its assumptions that all such data is subject to exploitation, even where it is generated by individuals for their own purposes, as with 'quantified self' / biological data (Swan 2013). European authors, cognisant of data protection laws, may be more wary about such assumptions, although this is counterbalanced by the very substantial exemptions enjoyed by some organisations in relation to intelligence and security analysis.
The longstanding 'data mining' label has been overtaken by the enthusiasm associated with 'big data'. This is commonly characterised as having the features of Velocity, Volume and Variety (Laney 2001). A sub-field of excitement may be emergent, under the catch-cry of 'fast data', and concerned with the near-real-time analysis of incoming data-streams (e.g. Pathirage & Plale 2015). Big data analytics promises a great deal. However, challenges need to be addressed. In particular, additional important features have been recognised, such as Value and Veracity (Schroek et al. 2012).
For the first decade, the literature consistently glossed over quality issues (e.g. Agrawal et al. 2011). Recognition of their significance has emerged, however, e.g. "well-designed and highly functional [business intelligence] systems that include inaccurate and unreliable data will have only limited value, and can even adversely impact business performance" (Park et al. 2012).
On the one hand, innovation is at risk of being stifled if accountants, auditors and lawyers begin exercising control too early in the incubation period for new processes. On the other hand, there are advantages in ensuring that the scope of the research conducted into big data methods and applications is sufficiently broad.
This paper seeks ways of protecting the big data analytics movement from choking on its own enthusiasm. It commences by delineating the challenges that need to be overcome in order to reliably extract value from data collections. This includes a suite of data quality and information quality factors. Risks are outlined, and measures identified whereby quality assurance can be embedded in analytical processes. Key research opportunities are identified.
This section establishes a foundation for the analysis by reviewing a range of factors that give rise to risk in big data analytics. Firstly, a number of categories of use are distinguished. Next, a set of data quality factors is identified, followed by a discussion of issues that arise from ambiguities in data meaning, from consolidation of multiple data sets, and from data scrubbing activities. Finally, quality and transparency concerns arising in relation to data analytics processes are outlined.
As an initial step, it is important to distinguish several categories of use of big data, because they have materially different risk-profiles. As depicted in Table 1, the first distinction is between uses that focus on populations and sub-populations, on the one hand, and those that are concerned about individual instances within populations, on the other.
One purpose for which big data appears to be frequently used is the testing of hypotheses. A more exciting and hence more common depiction of big data, as for data mining before it, is the discovery of characteristics and relationships that have not previously been appreciated. Related to this, but different from it, is the construction of profiles for sub-populations based on statistical consistencies.
Among the uses of big data that focus not on populations but on individual instances, is the search for the unusual, such as outliers and needles in haystacks. Another is the search for 'instances of interest' variously those that have a reasonable match to a previously computed abstract profile, and those for which data from multiple sources exhibit inconsistencies.
Empirical data purports to represent a real-world phenomenon, but there are significant limitations on the extent to which the representation is effective. For example, only some data is collected, and only in respect of some aspects of the phenomenon. It may be compressed or otherwise pre-processed. And the data may not correspond closely to the attribute that it is intended to represent.
Assuring the quality of data collection processes can be expensive, and hence the quality at the time of collection may be low. For example, the frequency of calibration of measuring devices may be less than is desirable, and large volumes of data may need to be subject to sampling techniques, which may result in inaccuracies.
A second cluster of issues concerns the reliability of the association of data with a particular real-world entity or identity. Great reliance is placed on (id)entifiers of various kinds, but these too are just particular instances of data, and hence suffer from the same quality issues. In most cases, they are also highly amenable to obfuscation and falsification.
The degree of confidence arising from (id)entity authentication processes is also highly variable. It was noted above that the costs of quality assurance at time of collection act as a constraint on data quality. Similarly, the quantum of resources invested in authentication reflect the perceived needs of the organisation funding the collection process, but not necessarily the needs of organisations exploiting the data resource. A great deal of intelligence and security analysis is a secondary or derivative use rather than a primary purpose of the data, and hence these quality issues are highly relevant to the present context.
The wide range of requirements that need to be satisfied in order for data to exhibit sufficient quality to support reliable decision-making are listed in Table 2. This draws in particular on Wang & Strong (1996), Shanks & Darke (1998) and Piprani & Ernst (2008), as summarised in Clarke (2016).
The first group of quality attributes can be assessed at the time of collection. These 'data quality' factors include syntactical validity, the appropriateness of the association of the data with an (id)entity, and with a particular attribute of that (id)entity, together with the degree of accuracy and precision, and the data's temporal applicability.
The second group, termed in Table 2 'information quality factors', can only be judged at the time of use. They include the relevance of the data to the specific use to which it is being put, its currency, it completeness, and its dependability. Judgements about the suitability of data, and about the impact of quality factors on decision-making, are dependent on the creation, maintenance and accessibility of metadata. The quality of data generally falls over time, most significantly because of changes in context.
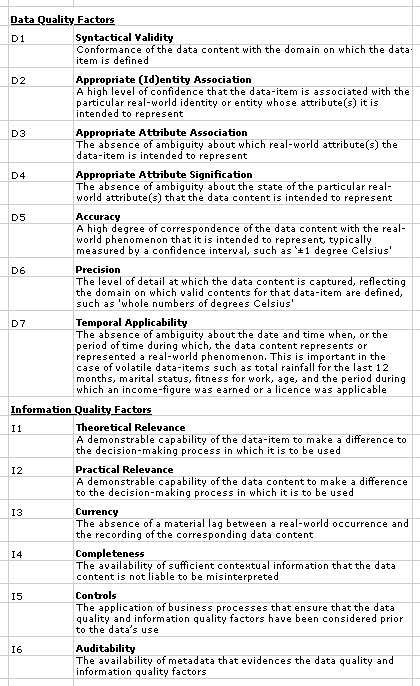
Working within a positivist framework, each data-item should be capable of having, and should have, clear definitions of each of the following (Clarke 1995, pp. 598-600):
In practice, however, the meaning of a great many data-items in a great many data-collections:
However, from the interpretivist perspective, a strictly positivist view of data is naïve, because the meaning of data is not imposed by the person who creates it, but rather is subject to interpretations by its users. Inappropriate interpretations are very likely, moreover, where data quality is low, provenance is unclear, definitions are lacking, or context is inadequate.
When data-sets are consolidated, rules are applied to achieve inter-relation between digital identities that exist within different frames of reference. Care is needed to specify precise mappings between data-items across the two or more data-sets. However, where any of the issues identified in the previous two sections exist, precise and reliable mapping is at least challenging, and inevitably gives rise to both false positives and false negatives.
Even where reliable matching or merger is feasible, it is all-too-common for limited attention to be paid to the challenges identified in the preceding sections relating to data quality issues and uncertainties about the meaning of data. The issues arising in relation to the meaning of data are magnified where data from multiple sources is consolidated. The greatest dangers arise not from unusual data-items, but in respect of widely used but subtly different data-items. There are many variations in the meaning of apparently similar data-items in different data collections, such as spouse, child and income. For example, a data-item may be defined by the legislation under which a government agency or an agency program operates, and this may be materially different from common usage of the term, and from usages in other data collections within the same agency, and in other agencies and corporations.
As regards data quality, merger of data-sets is highly likely to result in quality levels no better than those of the lowest-quality sources. Quality levels may be much lower than that, however, where inconsistencies exist among the qualifications for inclusion of the instance in the data-set, the data-item definitions, the domains on which the data-items are defined, and the quality assurance techniques applied at the time the data was created. And of course, where data-item definitions are vague, it may be difficult to conduct an assessment of the extent of the inconsistencies.
Processes are applied to data-sets in order to address data quality issues. The terms 'cleansing' and 'cleaning' have come into vogue (Rahm & Do 2000, Müller & Freytag 2003), but the original notion of 'scrubbing' is more apt, because the extent to which cleanliness is actually achievable is highly varied and success is far from assured (Widom 1995, Chaudhuri & Dayak 1997). Some of the deficiencies that data scrubbing seeks to address include missing values, syntactical errors in data content, syntactical differences among apparently comparable data-items, low quality at time of capture, degraded quality during storage and missing metadata.
The standard of the literature in this area is a cause for considerable concern. In principle, it is necessary to inspect and adapt data on the basis of some external authority. An example of this process is spell-checking of street and location-names, checks of the existence of street-numbers, and postcode/zipcode interpolation and substitution. Unfortunately, authoritative, external sources are available for only a small proportion of data-items. As a result, most of the literature deals with internal checks within data-sets and rule-based checks (e.g. Jagadish et al. 2014). While such approaches are likely to deliver some improvements, they also inevitably result in spurious interpolations and corrections.
Even more disturbing is the limited extent to which the literature discusses quality audits of the outcomes of data scrubbing processes. Proponents of the techniques blithely assume that a set of transformation rules that is derived at least in part, and often to a considerable extent, from the data-sets that are being manipulated, reliably improve the correspondence between the data and the real world phenomena that the data is presumed to represent. Reliance should not be placed on changes made by data scrubbing operations, unless and until the assumptions and the results have been subjected to reality tests.
A further set of issues arises in relation to big data analytics, and to the decisions that may be made based on the inferences drawn. Quite fundamentally, assurance is needed that the techniques applied to the data are appropriate, given the nature of the data. A common problem is the blind application of powerful statistical tools, many of which assume that all data is on a ratio scale, whereas some or even all of the data may be only on cardinal, ordinal or merely nominal scales. Mixed-mode data is particularly challenging to analyse. Guidance in relation to the applicability of the various approaches to different categories of data can be difficult to find, and the need for reflection on the risks involved is all-too-easily overlooked.
Uncertainties can arise in relation to the 'meaning' of data, at the syntactic and semantic levels, and in some contexts at the pragmatic level as well. Transparency in relation to the data relied upon can be very limited. In practice, transparency is highly variable, and in some circumstances non-existent.
A summation of the sceptic's view of data and its use in decision-making is found in Roszak (1986, pp. 87, 95, 98, 118, 120): "[Data, even today], is no more than it has ever been: discrete little bundles of fact, sometimes useful, sometimes trivial, and never the substance of thought [and knowledge] ... The data processing model of thought ... coarsens subtle distinctions in the anatomy of mind ... Experience ... is more like a stew than a filing system ... Every piece of software has some repertory of basic assumptions, values, limitations embedded within it ... [For example], the vice of the spreadsheet is that its neat, mathematical facade, its rigorous logic, its profusion of numbers, may blind its user to the unexamined ideas and omissions that govern the calculations ... garbage in - gospel out".
The quality of decisions made by humans is subject to the boundedness of human rationality and what may be referred to as bias (Nozick 1994, pp. 100-106), or as ill-justified selectivity or myopia. In particular, what comes to a person's mind is only a sub-set of the person's relevant experiences, which in turn is only a sub-set of all of the relevant information. Similar problems afflict machine-based decisions. The data that is used reflects the limitations inherent in the particular analytical tool that is applied, and within that the data that is made accessible to the tool, which is inevitably only a sub-set of the complete set of relevant data. Bias arises in both the choice of process and the choice of data fed to it.
A further concern is the nature of the decision process, and in particular the rationale underlying each particular decision. For an individual or organisation to take responsibility for a decision, they need to be able to understand how the decision mechanism worked, and how it was applied to which data in order to reach that decision.
The extent to which this understanding can be achieved varies, depending on the manner in which computing is applied. Inferencing that is expressed in algorithmic languages is explicit or at least extractable. On the other hand, in rule-based 'expert systems', the decision process and the decision criteria are implicit, and even explanations of the form 'the following rules were fired' may not be available. With 'neural network' software, and other largely empirical approaches, the decision process is implicit, and the criteria are not discernible (NS 1980). The key characteristics are summarised in Table 3.
After Clarke (1991). See also Clarke (2014, s.2.2)
Generation | 3 | 4 | 5 | 6 |
Type
| Algorithmic /
Procedural 'Programming Languages' | Declarative Languages ('4GLs') | Descriptive 'Expert Systems' (commonly rule-based) | Facilitative (summation of empirical evidence, e.g. neural networks) |
Model of the Problem-Domain | Implicit | Implicit | Explicit | Implicit |
Model of the Problem | Implicit | Explicit | None | None |
Model of the Solution | Explicit | Explicit (Pre-Defined)
| Implicit, as Data | None |
Process Transparency | Explicit | Explicit | Explicit Rules but Implicit Handling of Conflicts among Rules | Implicit (Comparison of a new instance with accumulated evidence) |
Decision Criteria Transparency | Explicit or at least Extractable | Explicit or at least Extractable | Implicit, and possibly Unextractable | None |
Concerns about the loss of transparency and of human control over decision-making have been expressed by a variety of authors (Roszak 1986, Dreyfus 1992, boyd & Crawford 2012). When applying the later (higher-numbered) generations of software, "the decision, and perhaps action, has been delegated to a machine, and the machine's rationale is inscrutable. Even with 3rd generation software, the complexity of the ... solution-statement can be such that the provision of an explanation to, for example, corporate executives, can be very challenging. The ... 5th and 6th generations involve successively more substantial abandonment of human intelligence, and dependence on the machine as decision-maker" (Clarke 2014, p.250).
Acting on arguments such as that in Ince et al. (2012), Nature has since 2013 stipulated that "Authors must make available upon request, to editors and reviewers, any previously unreported custom computer code used to generate results that are reported in the paper and central to its main claims" (Nature 2016). Despite this, recent articles in science journals have thrown into doubt the reproducibility of a considerable amount of published research (Roche et al. 2015, Marwick 2015). The antidote is seen as being transparency of both data and analytical methods. The corresponding issue in big data analytics is accountability. Where the smokescreen is lifted, and security analyses are quality-checked, similar shortfalls may become apparent. Accountability depends on clarity about the decision process and the decision criteria. Where transparency is inadequate, accountability is undermined, data and decision quality cannot be guaranteed, and, in the present context, security is compromised.
The conventional security model (Clarke 2015b) provides a basis for understanding the consequences of inadequate quality in big data and big data analytics. Risk assessment techniques commence by understanding stakeholders, the assets that they place value on, and the harm that can be done to those values. That lays the foundation for examining the threats and vulnerabilities that could give rise to harm, and the existing patterns of safeguards against harm arising.
Whereas there is an emergent literature that considers the potential impacts on individuals (e.g. boyd & Crawford 2012, Wigan & Clarke 2013), there is a shortage of sources looking at negative organisational impacts. Searches on relevant terms detect few papers in which more than a passing nod is made to any of data quality, risk assessment and risk management in big data contexts.
Where shortfalls in data quality undermine the accuracy of inferences from big data, there is a negative impact on the effectiveness of the decisions that they lead to. That spells negative impacts on return on investment, and in the public sector on policy outcomes. There may also be opportunity costs, to the extent that resources are diverted to big data projects that, with perfect hindsight, could have been invested in alternative activities with higher return.
In intelligence and security applications, ineffectiveness of decisions means insecurity. Beyond that, even the most superficial application of data security analysis leads to the conclusion that the result of big data activities is the creation of more copies, of more data, in one place, and its consolidation into more integrated data holdings that are assumed (whether justifiably or not) to be even more valuable than the independent data-sets. Hence, whether the quality is good or bad, the attractiveness of the consolidated data-holdings represents an 'attack magnet' or 'unintended honeypot'. Attackers include both those widely regarded as having no legitimacy, such as organised crime, and those with sufficient legal, institutional or market power to gain access through demands or negotiations. Some efforts by both categories of attacker succeed. So insecurity is heightened.
There are further, second-level risks, associated with organisational reputation. One of the scenarios presented in Clarke (2016) commences like this:
A government agency receives terse instructions from the government to get out ahead of the whistleblower menace, with Brutus, Judas Iscariot, Macbeth, Manning and Snowden invoked as examples of trusted insiders who turned. The agency increases the intrusiveness and frequency of employee vetting, and lowers the threshold at which positive vetting is undertaken. To increase the pool of available information, the agency exercises its powers to gain access to border movements, credit history, court records, law enforcement agencies' persons-of-interest lists, and financial tracking alerts. It applies big data analytics to a consolidated database comprising not only those sources, but also all internal communications, and all postings to social media gathered by a specialist external services corporation.
There is of course a chance that an untrustworthy insider might be discovered in such ways. There is a far higher chance, however, that the outliers that are discovered will be subjected to unjustified suspicion and discrimination. Moreover, the breach of trust in relation to all employees and contractors inevitably undermines morale within an organisation. The basis of the above scenario was not the author's imagination, but an announcement of an upgrade to public service security assessment processes announced in September 2014 by the Australian Attorney-General (AG 2014) and expanded on in interview (Coyne 2014).
Loss of trust arising from abuse of data may be among staff-members, as in the scenario just discussed, or may affect relationships between an organisation and external people that it deals with, e.g. customers, suppliers or registrants. In many circumstances, organisations are dependent on individuals as a source of data, and either have limited ways of encouraging them to provide accurate data, or face high costs to authenticate the data that they provide. Loss of trust inevitably results in higher levels of obfuscation and falsification, and yet lower levels of data quality.
Many of the risks arising from large-scale surveillance, whether of the population as a whole or of specific individuals, do not impinge in the first instance on the organisations conducting it, nor on the individuals and organisations accessing the resulting data-streams, nor even on the individuals and organisations drawing inferences and acting on them. The primary burden of the direct effects are commonly carried by the people who are subjected to the surveillance.
Some inferences will be reasonable, and the resulting actions justified. Others will be criticised, on multiple grounds. The exploitation of the data usually involves breaches of trust. The judgement may apply "a predetermined model of infraction" (Marx & Reichman 1984, p. 429), which gives rise to a 'strict liability' offence that precludes any form of defence. The discrimination may be unfair. The investigation methods will be seen by many to be highly inappropriate for relatively minor offences.
In some cases, an action may involve a non-human accuser, an unclear but serious accusation, an essentially unchallengeable accusation, and a reversed onus of proof. Such patterns have been subjected to polite criticism on the basis that they involve replacing the traditional criterion of "probable cause" with "probabilistic cause" (Bollier 2010, pp.33-34). Terms such as 'algorithmic policing' and 'algorithmic justice' have been applied to the phenomenon. Even less polite descriptions may be warranted. The characteristics are the same as those of "the story of a man arrested and prosecuted by a remote, inaccessible authority, with the nature of his crime revealed neither to him nor to the reader" (Wikipedia plot summary of Kafka's 'The Trial', published in 1925). 'Kafkaesque' justice was once decried by the free world as being an instrument of oppression practised only by uncivilised regimes. To the extent that security applications of big data actually fit to this pattern, their public credibility will be very low. In practice, institutions commonly practise 'security by obscurity' and refuse to permit their modus operandi to be published. In such circumstances, even justifiable actions based on reasonable inferences are also likely to be publicly perceived as the exercise of the power of State, and as without moral credibility.
Organisations that exercise such corrupted forms of justice may be subject to external controls. In some jurisdictions, constitutional challenges may be successful, as has been the case in many countries in relation to 'data retention' measures. A more common, but potentially effective control over intrusive data-handling and data analytics may be public disquiet, amplified by media coverage, undermining support for the measures. For 'algorithmic justice' to be sustained, it may prove necessary for the State to contrive the impression of a 'constant state of warfare' - which was identified by Orwell's '1984' (1948) as a common feature of oppressive regimes.
In summary, security applications of big data involve risks to the effectiveness of decision-making, to the achievement of return on investment, to the execution of public policy, to the security of data, to justice, to the freedoms of individuals, to the reputation and public credibility of organisations and their actions, and ultimately to democracy. Because of the closed nature of intelligence and security operations, it is highly unlikely that natural controls will be effective in constraining behaviour, and therefore highly likely that the theoretical risks will give rise to many real instances of faulty justice and breaches of human rights. If natural controls are inadequate, it is vital that strategies be adopted, at the very least at the organisational level, whereby effective regulatory mechanisms are imposed on security applications of big data.
While big data projects continue to be regarded as experimental, they may enjoy freedom from corporate governance constraints. There might nonetheless be good reasons for applying some tests to big data analytics activities even while they are still inside the laboratory. One reason is that some inferences may escape, and be adopted uncritically by a senior executive or an operational manager, with unpredictable effects. Another is that, as laboratory techniques and results begin to be released into the enterprise, they will be checked by hard-bitten realists who are sceptical about tools that they don't understand.
One approach that is likely to deliver value is early recognition of quality issues, and awareness and training activities to sensitise participants to the risks arising from them. Fundamentally, however, formal risk assessment is essential. Risk assessment and risk management are well-known techniques and are the subject of copious documentation in both formal Standards (ISO 31000 and 31010, and the 27005 series) and commercial processes (ISACA COBIT, ITIL, PRINCE2, etc.).
Risk assessment needs to be conducted well in advance of deployment. It needs to be followed by the expression of a risk management plan, and by the implementation of safeguards for data quality, information quality, and decision quality. Post-controls are also at least advisable, and in many contexts are essential. For example, organisational filters can be applied, to ensure that inferences are not blindly converted into action without reality checks being applied first. In addition, audits can be performed after early uses of each technique, in order to assess its impact in the real world. Table 4 offers some more fully articulated suggestions.
One particular, and in many cases, highly significant risk is capable of being avoided entirely. In Table 1, functions of big data analytics were categorised as having variously a population focus or an individual focus. In the case of population-focused data analytics, the interest is not in individual records, but in the data-set as a whole. Hence risks arising in relation to individual records can be avoided by achieving effective anonymisation of each record.
A literature exists on 'privacy-preserving data mining' (PPDM - Denning 1980, Sweeney 1996, Agrawal & Srikant 2000). For a literature review, see Brynielsson et al. (2013). PPDM involves suppressing all identifiers and quasi-identifiers, and editing data-items and/or statistically randomising (or 'perturbing') the contents of data-items. The declared purpose is to preserve the overall statistical features of the data, while achieving a lower, or in some cases a defined, probability of revealing private information. Many such techniques appear not to have escaped the laboratory. For guidance on forms of data manipulation that are suitable for practical application, see UKICO (2012), but also Slee (2011), DHHS (2012).
A contrary area of research has developed techniques for 're-identification' (Sweeney 2002, Acquisti & Gross 2009, Ohm 2010). Jändel (2014) describes a process for analysing the risk of re-identification, and determining whether a given threshold ("the largest acceptable de-anonymisation probability for the attack scenario") is exceeded.
I contend that a stronger standard is needed than 'mostly de-identified' or 'moderately perturbed'. It would be an attractive idea to stipulate 'irreversible de-identification', but, with data-collections of even modest richness, this appears to be an unachievable nirvana. A different approach is accordingly proposed.
The standard of 'irreversible falsification' needs to be applied to each individual data record. Each record is then valueless for any form of inferencing, and useless for administrative decision-making in relation to individuals. Both to achieve trust and to reduce the attractiveness of the data-set as a target for attackers, the application of irreversible record falsification techniques to the data-set should be publicly known.
Intuitively, it would appear unlikely that any single process could achieve both the standard of 'irreversibly falsified records' and preservation of the original data-set's overall statistical features. It seems more likely that separate and different processes would need to be applied, in order to produce a data-set that preserves the particular statistical features that are critical for any given analysis.
Risk assessment processes of the kinds discussed above are largely conducted from the perspective(s) of one or more of the organisations performing the surveillance, processing the data, drawing the inferences, and making decisions and taking action on the basis of those inferences. There is also a need for impact assessment at a higher level of abstraction, on behalf of the interests of an economy or a society. Relevant techniques include Technology Assessment (TA - Guston & Sarewitz 2002), Privacy Impact Assessment (PIA - Clarke 2009, Wright & De Hert 2012) and Surveillance Impact Assessment (Wright & Raab 2012).
The analysis presented above suggests that research is needed not only into how data can be manipulated in order to provide new insights, but also into how the risks arising from data manipulation can be managed. Table 5 lists research topics that have emerged during the analysis reported above.
An important research technique in leading/bleeding-edge situations is the case study. Whereas a set of vignettes or scenarios can provide a degree of insight (Clarke 2015a), case studies can deliver in-depth understanding. Another area of opportunity is in methods research, where studies can be undertaken of the ways to embed data and process quality into organisational risk assessment and risk management frameworks, and of applications of broader impact assessment techniques.
In circumstances in which considerable volumes of output will be generated - such as anomaly detection in computer networks - experiments can be conducted on alternative ways of presenting the data-glut and avoiding cognitive overload. Hence another potentially fruitful area is the analysis of categories, in order to refine the notion of 'anomaly', and prioritise and cluster them.
The following call to arms appeared several years ago in a journal Editorial: "Big Data's success is inevitably linked to ... clear rules regarding data quality. ... High quality data requires data to be consistent regarding time ..., content ..., meaning ... , and data that allow for unique identifiability ... , as well as being complete, comprehensible, and reliable" (Buhl & Heidemann 2013, pp. 66-67).
To date, however, that call has been largely ignored. Calls for Papers for Big Data Conferences make no more than fleeting mentions of the topic, with more than half of them in the 2014-15 period completely overlooking it. Meanwhile, 30 leaders from the database community recently identified five challenges for big data, but omitted any mention of 'veracity' and made only the most fleeting mentions of quality (Abadi et al. 2016). There remains a remarkable paucity of discussion of data quality and decision quality in the 'big data' literature. To the extent that such topics have been addressed, the treatment has been limited to those aspects of data quality that are amenable to automated analysis and amendment, through operations within the data collection itself.
Big data offers promise in a variety of security contexts. But risks need to be recognised, and managed. This requires the rediscovery of existing knowledge about data quality, information quality and decision quality, and efforts to devise effective and efficient safeguards against harmful misapplication of big data and data analytic techniques. The undertaking needs to be progressively brought within organisations' existing risk assessment and risk management frameworks. Research programs need to encompass quality analysis and assurance.
Abadi D. (2016) 'The Beckman Report on Database Research' Commun. ACM 59, 2 (February 2016) 92-99
Acquisti A. & Gross R. (2009) `Predicting Social Security Numbers from Public Data' Proc. National Academy of Science 106, 27 (2009) 10975-10980
AG (2014) 'The Insider Threat' Speech by the Australian Attorney-General, 2 September 2014, at https://www.attorneygeneral.gov.au/Speeches/Pages/2014/ThirdQuarter2014/2September2014-2014SecurityinGovernmentConference-TheInsiderThreat.aspx
AGD (2014) 'Australian Government Personnel Security Core Policy' Attorney-General's Dept, 2 September 2014, at http://www.protectivesecurity.gov.au/personnelsecurity/Pages/default.aspx
Agrawal D. et al. (2011) 'Challenges and Opportunities with Big Data 2011-1' Cyber Center Technical Reports, Paper 1, 2011, at http://docs.lib.purdue.edu/cctech/1
Agrawal R. & Srikant R. (2000) 'Privacy-preserving data mining' ACM Sigmod Record, 2000
Bollier D. (2010) 'The Promise and Peril of Big Data' The Aspen Institute, 2010, at http://www.ilmresource.com/collateral/analyst-reports/10334-ar-promise-peril-of-big-data.pdf
boyd D. & Crawford K. (2012) 'Critical Questions for Big Data' Information, Communication & Society, 15, 5 (June 2012) 662-679, DOI: 10.1080/1369118X.2012.678878, at http://www.tandfonline.com/doi/abs/10.1080/1369118X.2012.678878#.U_0X7kaLA4M
Brynielsson J., Johansson F. & Jändel M. (2013) 'Privacy-preserving data mining: A literature review' Swedish Defence Research Agency, February 2013
Chaudhuri S. & Dayal U. (1997) 'An Overview of Data Warehousing and OLAP Technology' ACM SIGMOD 26, 1 (1997) 65-74, at http://www.cs.sfu.ca/CourseCentral/459/han/papers/chaudhuri97.pdf
Clarke R. (1995) 'A Normative Regulatory Framework for Computer Matching' J. of Computer & Info. L. 13,3 (June 1995), PrePrint at http://www.rogerclarke.com/DV/MatchFrame.html
Clarke R. (2009) 'Privacy Impact Assessment: Its Origins and Development' Computer Law & Security Review 25, 2 (April 2009) 123-135, at http://www.rogerclarke.com/DV/PIAHist-08.html
Clarke R. (2014) 'What Drones Inherit from Their Ancestors' Computer Law & Security Review 30, 3 (June 2014) 247-262, PrePrint at http://www.rogerclarke.com/SOS/Drones-I.html
Clarke R. (2015a) 'Quasi-Empirical Scenario Analysis and Its Application to Big Data Quality' Proc. 28th Bled eConference, Slovenia, June 2015, at http://www.rogerclarke.com/EC/BDSA.html
Clarke R. (2015b) 'The Prospects of Easier Security for SMEs and Consumers' Computer Law & Security Review 31, 4 (August 2015) 538-552, at http://www.rogerclarke.com/EC/SSACS.html
Clarke R. (2016) 'Big Data, Big Risks' Information Systems Journal 26, 1 (January 2016) 77-90, PrePrint at http://www.rogerclarke.com/EC/BDBR.html
Coyne A. (2014) 'Brandis boosts vetting of APS staff to prevent insider threats' itNews, 2 September 2014, at http://www.itnews.com.au/News/391656,brandis-boosts-vetting-of-aps-staff-to-prevnt-insider-threats.aspx
Denning D.E. (1980) 'Secure statistical databases with random sample queries' ACM TODS 5, 3 (Sep 1980) 291- 315
DHHS (2012) 'Guidance Regarding Methods for De-identification of Protected Health Information in Accordance with the Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule' Department of Health & Human Services, November 2012, at http://www.hhs.gov/ocr/privacy/hipaa/understanding/coveredentities/De-identification/guidance.html
Guston D.H. & Sarewitz D. (2001) 'Real-time technology assessment' Technology in Society 24 (2002) 93-109, at http://archive.cspo.org/documents/realtimeTA.pdf
Ince D.C., Hatton L. & Graham-Cumming J. (2012) 'The case for open computer programs' Nature 482 (23 February 2012) 485-488 doi:10.1038/nature10836, at http://www.nature.com/nature/journal/v482/n7386/full/nature10836.html
Jagadish H.V., Gehrke J., Labrinidis A., Papakonstantinou Y., Patel J.M., Ramakrishnan R. & Shahabi C. (2014) 'Big data and its technical challenges' Communications of the ACM 57, 7 (July 2014) 86-94
Jändel M. (2014) 'Decision support for releasing anonymised data' Computers & Security 46 (2014) 48-61
Laney D. (2001) '3D Data Management: Controlling Data Volume, Velocity and Variety' Meta-Group, February 2001, at http://blogs.gartner.com/doug-laney/files/2012/01/ad949-3D-Data-Management-Controlling-Data-Volume-Velocity-and-Variety.pdf
Manwaring K. & Clarke R. (2015) 'Surfing the third wave of computing: a framework for research into eObjects' Computer Law & Security Review 31,5 (October 2015) 586-603, at http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2613198
Marwick B. (2015) 'How computers broke science - and what we can do to fix it' The Conversation, 9 November 2015, at https://theconversation.com/how-computers-broke-science-and-what-we-can-do-to-fix-it-49938
Marx G.T. & Reichman N. (1984) 'Routinising the Discovery of Secrets' Am. Behav. Scientist 27,4 (Mar/Apr 1984) 423-452
Müller H. & Freytag J.-C. (2003) 'Problems, Methods and Challenges in Comprehensive Data Cleansing' Technical Report HUB-IB-164, Humboldt-Universität zu Berlin, Institut für Informatik, 2003, at http://www.informatik.uni-jena.de/dbis/lehre/ss2005/sem_dwh/lit/MuFr03.pdf
Nature (2016) 'Availability of data, material and methods' Nature, at http://www.nature.com/authors/policies/availability.html#code
Nozick R. (1994) 'The Nature of Rationality' Princeton University Press, 1994
NS (1980) 'Computers That Learn Could Lead to Disaster' New Scientist, 17 January 1980, at http://www.newscientist.com/article/dn10549-computers-that-learn-could-lead-to-disaster.html
Ohm P. (2010) 'Broken Promises of Privacy: Responding to the Surprising Failure of Anonymization' 57 UCLA LAW REVIEW 1701 (2010) 1701-1711, at http://www.patents.gov.il/NR/rdonlyres/E1685C34-19FF-47F0-B460-9D3DC9D89103/26389/UCLAOhmFailureofAnonymity5763.pdf
Park S.-H., Huh S.-Y., Oh W. & Han A.P. (2012) 'A Social Network-Based Inference Model for Validating Customer Profile Data' MIS Quarterly 36, 4 (December 2012) 1217-1237, at http://www.is.cityu.edu.hk/staff/sangphan/mobility/papers/BI_MISQ_%5BHAN,%2520Sang%2520Pil%5D.pdf
Pathirage M. & Plale B. (2015) 'Fast Data Management with Distributed Streaming SQL' arXiv preprint arXiv:1511.03935, at http://arxiv.org/abs/1511.03935
Piprani B. & Ernst D. (2008) 'A Model for Data Quality Assessment' Proc. OTM Workshops (5333) 2008, pp 750-759
Rahm E. & Do H.H. (2000) 'Data cleaning: Problems and current approaches' IEEE Data Eng. Bull., 2000, at http://dc-pubs.dbs.uni-leipzig.de/files/Rahm2000DataCleaningProblemsand.pdf
Roche D.G., Kruuk L.E.B., Lanfear R. & Binning S.A. (2015) 'Public Data Archiving in Ecology and Evolution: How Well Are We Doing?' PLoS Biol 13(11), 10 Nov 2015, at http://journals.plos.org/plosbiology/article/asset?id=10.1371%2Fjournal.pbio.1002295.PDF
Roszak T. (1986) 'The Cult of Information' Pantheon 1986
Schroeck M., Shockley R., Smart J., Romero-Morales D. & Tufano P. (2012) 'Analytics : The real world use of big data' IBM Institute for Business Value / Saïd Business School at the University of Oxford, October 2012, at http://www.ibm.com/smarterplanet/global/files/se__sv_se__intelligence__Analytics_-_The_real-world_use_of_big_data.pdf
Shanks G. & Darke P. (1998) 'Understanding Data Quality in a Data Warehouse' The Australian Computer Journal 30 (1998) 122-128
Slee T. (2011) 'Data Anonymization and Re-identification: Some Basics Of Data Privacy: Why Personally Identifiable Information is irrelevant' Whimsley, September 2011, at http://tomslee.net/2011/09/data-anonymization-and-re-identification-some-basics-of-data-privacy.html
Swan M. (2013) 'The Quantified Self: Fundamental Disruption in Big Data Science and Biological Discovery' Big Data 1, 2 (June 2013) 85-99, at http://online.liebertpub.com/doi/pdfplus/10.1089/big.2012.0002
Sweeney L. (1996) 'Replacing personally-identifying information in medical records, the Scrub system' Journal of the American Medical Informatics Association (1996) 333-337
Sweeney L. (2002) 'k-anonymity: a model for protecting privacy' International Journal on Uncertainty, Fuzziness and Knowledge-based Systems 10, 5 (2002) 557-570, at http://arbor.ee.ntu.edu.tw/archive/ppdm/Anonymity/SweeneyKA02.pdf
UKICO (2012) 'Anonymisation: managing data protection risk: code of practice' UK Information Commissioner's Office, November 2012, at http://ico.org.uk/for_organisations/data_protection/topic_guides/~/media/documents/library/Data_Protection/Practical_application/anonymisation-codev2.pdf
Wang R.Y. & Strong D.M. (1996) 'Beyond Accuracy: What Data Quality Means to Data Consumers' Journal of Management Information Systems 12, 4 (Spring, 1996) 5-33
Widom J. (1995) 'Research Problems in Data Warehousing' Proc. 4th Int'l Conf. on Infor. & Knowledge Management, November 1995, at http://ilpubs.stanford.edu:8090/91/1/1995-24.pdf
Wigan M.R. & Clarke R. (2013) 'Big Data's Big Unintended Consequences' IEEE Computer 46, 6 (June 2013) 46 - 53, PrePrint at http://www.rogerclarke.com/DV/BigData-1303.html
Wright D. & De Hert P. (eds) (2012) 'Privacy Impact Assessments' Springer, 2012
Wright D. & Raab C.D. (2012) 'Constructing a surveillance impact assessment' Computer Law & Security Review 28, 6 (December 2012) 613-626
Roger Clarke is Principal of Xamax Consultancy Pty Ltd, Canberra. He is also a Visiting Professor in the Cyberspace Law & Policy Centre at the University of N.S.W., and a Visiting Professor in the Research School of Computer Science at the Australian National University. He is a longstanding Board member of the Australian Privacy Foundation (APF), including as Chair 2006-14, and was a Board member of Electronic Frontiers Australia (EFA) 2000-05, and a Director of the Internet Society of Australia 2010-15, including as Secretary 2012-15.
An earlier version of this paper was presented on 16 November 2015 at an conference on Redefining R&D Needs for Australian Cyber Security, at the Australian Centre for Cyber Security (ACCS) at the Australian Defence Force Academy, Canberra. The paper has benefited from several very helpful comments and references from an anonymous reviewer.
| Personalia |
Photographs Presentations Videos |
Access Statistics |
 |
The content and infrastructure for these community service pages are provided by Roger Clarke through his consultancy company, Xamax. From the site's beginnings in August 1994 until February 2009, the infrastructure was provided by the Australian National University. During that time, the site accumulated close to 30 million hits. It passed 65 million in early 2021. Sponsored by the Gallery, Bunhybee Grasslands, the extended Clarke Family, Knights of the Spatchcock and their drummer |
Xamax Consultancy Pty Ltd ACN: 002 360 456 78 Sidaway St, Chapman ACT 2611 AUSTRALIA Tel: +61 2 6288 6916 |
Created: 23 October 2015 - Last Amended: 20 May 2016 by Roger Clarke - Site Last Verified: 15 February 2009
This document is at www.rogerclarke.com/EC/BDQAS.html
Mail to Webmaster - © Xamax Consultancy Pty Ltd, 1995-2022 - Privacy Policy