Roger Clarke's Web-Site
© Xamax Consultancy Pty Ltd, 1995-2024

Infrastructure
& Privacy
Matilda
Roger Clarke's Web-Site© Xamax Consultancy Pty Ltd, 1995-2024 |
|
|||||
| HOME | eBusiness |
Information Infrastructure |
Dataveillance & Privacy |
Identity Matters | Other Topics | |
| What's New |
Waltzing Matilda | Advanced Site-Search | ||||
Principal, Xamax Consultancy Pty Ltd, Canberra
Visiting Fellow, Department of Computer Science, Australian National University
Version of 3 February 1994
© Xamax Consultancy Pty Ltd, 1994
This paper was published in the Journal of Computer & Information Law XIII,4 (Summer 1995) 585-633
This document is at http://www.rogerclarke.com/DV/MatchFrame.html
Computer matching is a powerful data surveillance tool which, since its emergence in 1976, has become very widely used by government agencies. It involves the merger of data from multiple sources: data which was gathered for different purposes, is subject to different definitions, and is of variable quality. It is a mass dataveillance technique, and its purpose is to generate suspicions that errors, misdemeanours or fraud have occurred. For many years, computer matching activities were carried on in semi-secrecy. The purpose of this paper is to propose a framework within which effective regulation can be imposed on this dangerous technique.
The paper commences by providing background to computer matching's origins and nature. Its impacts are then discussed, in order to establish that there is a need for controls. Intrinsic controls are assessed, and found wanting. A set of features of a satisfactory external control regime is then presented. It provides a basis for evaluation of the protective measures which are in force in at least four jurisdictions, and guidance for legislators in others.
Computer matching is the comparison of machine-readable records containing personal data relating to many people, in order to detect cases of interest. The technique is called 'computer matching' in the United States, and 'data matching' in Canada, Australia and New Zealand.
Computer matching became economically feasible in the early 1970s, as a result of developments in information technology (IT). The technique has been progressively developed since then, and is now widely used, particularly in government administration and particularly in the four countries mentioned above. It has the capacity to assist in the detection of error, abuse and fraud in large-scale systems, but in so doing may jeopardise the information privacy of those whose data is involved, and even significantly alter the balance of power between consumers and corporations, and citizens and the State.
The research underlying the paper has been undertaken during a protracted period. Literature search and analysis have been supplemented by considerable field work, undertaken primarily in the United States and Australia. The author has been much involved in advocacy on this and related data surveillance matters in Australia during the period since 1972.
The paper's scope is restricted to computer matching in the public sector. This is because, firstly, the technique's primary applications are in these areas; secondly, access to both primary and secondary sources is even more difficult in the private sector than it is in relation to government; and thirdly, the issues which arise in the private sector are somewhat different, and justify separate treatment elsewhere. Throughout the paper, reference is made to circumstances in the United States and Australia. There is good reason to believe that the comments made are at least generally applicable in Canada and New Zealand, which are also advanced in their use of the technique. On the basis of research undertaken in Europe, computer matching appears to have been to date less actively applied there. Because of differences in the legal context including civil rights, and the patterns of use of IT in personal data systems, the application of this paper outside the four countries mentioned requires care.
Background is provided concerning the origins of computer matching, and nature of the technique. Consideration is then given to its impacts and implications, and the natural or intrinsic controls which act to limit its use and to ensure that where it is used it is used fairly. The conclusion is reached that intrinsic controls are largely ineffectual, and that external controls need to be imposed. The final section of the paper puts forward a framework which may be used to assess the adequacy of existing control regimes, and to design regulatory regimes in countries which do not yet have them.
Computer matching is an outgrowth of the increasing data intensity of public administration during the twentieth century. In order to appreciate the context within which it exists, it is necessary to refer to the data surveillance literature - see [1], [2] , [3],4 ,[5], [6], [7], [8], [9], [10], [11], [12], [13], [14], [15], [16] and [17] .
Computer matching itself has been the subject of a surprisingly limited literature. There are government reports of various kinds, but little of an academic nature. Neither the term nor any equivalent can be found in such landmark documents as [18],19, [20], [21], the U.S. Privacy Act 1974, [22], [23], [24], [25] and [26]. It was a discovery of public servants, unheralded by academics and other seers. The term came into currency following publication of descriptions of 'Project Match', conducted by the Department of Health, Education & Welfare (HEW, now DHHS) in 1977. The series of important documents through which the line of development can be traced includes [27], [28], [29], [30], [31], [32], [33], [34], [35], [36], [37], the U.S. Computer Matching and Privacy Protection Act 1988, [38], [39] and [40].
During the subsequent decade, many hundreds of matching programs have been conducted, particularly by federal government agencies. Areas of application include the administration of taxation, social welfare, housing and health insurance. In the United States, fiscal pressure was brought to bear on the States to ensure that they conducted and participated in matching programs. A detailed review of the history of the technique is to be found in [41].
There is no authoritative definition of the term 'computer matching'. Following an examination and analysis of the meaning of the term in the literature and practice, Clarke [42] adopted the following:
computer matching is any computer-supported process in which personal data records relating to many people are compared in order to identify cases of interest.
The procedure involved varies, but the model in Exhibit 1 is sufficiently rich to enable the analysis of the vast majority of programs. The steps in the process are:
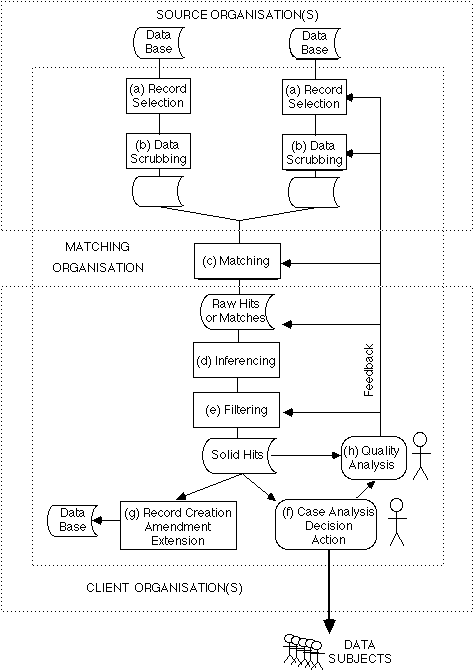
The contention of this paper is that external controls over the practice of computer matching are essential. This section commences by presenting an analysis of its impacts, firstly at an abstract and then at a more detailed level, concluding that they are very substantial. It then assesses factors which act as natural or intrinsic controls, and concludes that they are inadequate.
It is not argued that computer matching is valueless, or that it should never be applied. There is a limited literature on its financial and other benefits, and very little of what is available results from careful, independent assessment. See [43], [44], [45], [46], [47], [48], [49], [50], [51], [52], [53], [54], [55], [56], [57], [58], [59], [60], [61], [62], [63], [64], [65], [66], and [67]. This paper focusses on its negative aspects.
There is a large and highly varied literature expressing cautionary, critical and in some cases hysterical comments about dataveillance in general and computer matching in particular. See [68], [69], [70], [71], [72], [73], [74], [75], [76], [77], [78], [79] and [80]. This sub-section outlines the more general arguments regarding the power relationship between the citizen and the State, arbitrary interference, due process, the loss of data context and social context, social equity considerations and risks to public morality and law and order.
Computer matching has been in many cases undertaken without knowledge or consent of any of the many people to whom the data relates. Data subjects have had no clear right to prevent this happening, because until 1988 no laws creating such a right existed in either the United States or Australia.
Even where consent is sought, it is often not meaningful consent. In some cases the wording is such that the person has no appreciation of the import of the consent that is being given. There are also instances in which pseudo-consent forms are used; for example, where agencies seek an 'authority' from benefit recipients ostensibly to enable the agency to gather information from another agency, when they in any case have legal authority to gather it. The absence of effective subject knowledge and consent mechanisms can be expected to result in individuals distrusting organisations, and in the provision of low quality data.
In many cases the bargaining position is so disproportionately weighted in favour of the agency that the data subject has no real option but to comply; for example, the provision of the person's identification code issued by some other agency (such as the SSN in the United States, the SIN in Canada, or the TFN in Australia) may be made a condition of application for a benefit, specifically to enable front-end verification and matching.
The scope which computer matching offers for cross-system enforcement has also been discovered by some agencies: "use of the data-matching arrangements would enable each agency to identify cases where recovery of an outstanding debt owing to their agency was becoming difficult and that an income support payment was being made by one of the related agencies. Action could then be taken to recover the outstanding debt by withholding an amount from the person's current financial assistance payment" [81]. The legislative authorisation which exists for such recovery was passed in an age before IT had delivered efficient mass dataveillance capabilities.
Automated maintenance of databases using data arising from matching (e.g. cross-notification among agencies of a data subject's change of address) is consistent with a paternalistic approach by the State to the lives of its citizens. Associated with this paternalism is a loss of initiative: "Once people start fearing the government, once they think they are under surveillance by government, whether they are or not, they are likely to refrain from exercising the great rights that are incorporated in the First Amendment to make their minds and spirits free" [82]. The 'chilling effect' of mass data surveillance could cause a society to lose its morality, its creativity, and its resilience. With the recent increased understanding of the depths of despair to which residents of Eastern European Communist dictatorships plunged in recent years, this 'chilling effect' ceases to be mere sociologist's jargon, and becomes a palpable factor. Put more colourfully, "What we confront in the burgeoning surveillance machinery of our society is not a value-neutral technological process ... It is, rather, the social vision of the Utilitarian philosophers at last fully realized in the computer. It yields a world without shadows, secrets or mysteries, where everything has become a naked quantity" [83].
Matching involves trawling through data which refers to large populations, in order to identify relatively small numbers of individuals who may have committed an error, default, dishonesty or fraud. Many commentators have addressed this issue. For example:
"[Data matching programs are] old-fashioned fishing expeditions [posing] as high technology" [84] "[Data matching] has been criticised as simply a modern version of the general warrant once used to search homes without discrimination or reasonable cause"[85] "Computer matches are inherently mass or class investigations, as they are conducted on a category of people rather than on specific individuals" [86] "It is like investigators entering a home without any warrant or prior suspicion, taking away some or all of the contents, looking at them, keeping [copies of] what is of interest and returning [them], all without the knowledge of the occupier" [87] "[Data matching] is the information society's equivalent of driftnet fishing" [88]
Such concerns have not only been voiced by privacy advocates. The U.S. Civil Service Commission's General Counsel opposed the original Project Match in 1977, on the grounds that the matching of disparate records violated the Privacy Act: "At the matching stage there is no indication whatsoever that a violation or potential violation of law has occurred ... It cannot fairly be said ... that disclosure of information about a particular individual at this preliminary stage is justified by any degree of probability that a violation or potential violation of law has occurred" [89].
The practice is therefore not merely an invasion of information privacy. In respect of each individual, computer matching is an arbitrary action, because no prior suspicion existed. The analogy may be drawn with the powers of policemen to interfere with individuals' quiet enjoyment. If a policeman has grounds for suspecting that a person has committed, or even intends, or is considered likely, to commit, an offence, then he generally has the power to intercept and perhaps detain that person. Otherwise, with rare, carefully defined and, in a democratic state well-justified, exceptions (such as national security emergencies and, in some jurisdictions, random testing of drivers for alcohol or drugs), even a policeman does not have the power to intercept or detain a person. Computer matching is therefore in conflict with democratic standards relating to arbitrary interference. There is no justification for the handling of any one person's data, other than that the person is a member of a population which is known to contain miscreants.
Yet it is generally the case that a relatively very small proportion of the people whose data is involved in matching actually prove to be of interest to the organisation conducting the match. Research conducted by the author shows that typically between 1% and 9% of records generate raw hits, and 0.1-2.0% survive the filtering process and reach the analysis stage. In the case of the Australian Department of Social Security's parallel matching scheme, the proportion of raw matches which have resulted in downward variations in benefits has been only about 0.5%, with 0.2% leading to debt recovery action in relation to overpayments [DSS 1992, pp.88-90,107-111]. Computer matching therefore represents an arbitrary interference with personal data which, in relation to the vast majority of the people whose data is processed, is demonstrably unjustifiable.
Basic among the freedoms which residents of advanced Western nations value is the freedom from arbitrary imprisonment and oppression by agents of the State. This is entirely dependent on an independent judiciary applying the law in a fair manner. "Legal due process requires fair and equal treatment, decision making in accordance with known, uniform laws, elimination as much as possible of arbitrary and capricious behavior, and the right of appeal to assure proper procedures were, in fact, followed. All of these factors require a presumption of innocence, full judicial hearings free from the slightest taint of coercion, threats, or consideration of advantage to either the accused or the judicial system ... Information systems which contain inaccurate, incomplete, or ambiguous information lead to violations of elemental notions of fairness in treating individuals and threaten the specific due process guarantees afforded by the Constitution and statutes. Information must be accurate, unambiguous and complete; it must be open to challenge and review by all parties; and the procedure for creating records must be uniform and apply equally to all cases" [90]. See also [91].
A related issue is the increasing tendency of Parliaments and government agencies to provide for the reversal of the onus of proof, such that the agency's determination holds unless the person involved successfully prosecutes his or her innocence. For example, the Australian Taxation Office recently extended its long-standing practice in relation to taxation assessment to its recently acquired function of child maintenance administration.
Government agencies which face difficulties and delays in relation to prosecution and debt recovery may be expected to seek to have their administrative decisions treated as direct legal authority. Because the data on which those decisions are based is by its nature suspect, granting their requests threatens fundamental freedoms.
Many people regard their provision of data to an organisation as being for a particular purpose only, and perceive its use for any other purpose without consent as being, in effect, a breach of contract or trust. Privacy laws and policies throughout the Western world, and encapsulated in international documents such as the OECD Guidelines [1980], reflect that viewpoint. Yet computer matching generally violates this restraint.
The principle is not merely based on a democratic ideal. People, and matters relating to them, are complicated, and organisations generally have difficulty dealing with atypical, idiosyncratic cases or extenuating circumstances 92. Achieving a full understanding of the circumstances generally requires not only additional data which would have seemed too trivial and/or too expensive to collect, but also the application of common sense, and contemporary received wisdom, public opinion and morality [93].
When data is used in its original context, its quality may be sufficient to support effective and fair decision-making, but when data are used outside their original context the probability of misinterpreting them increases greatly. This is the reason why information privacy principles place such importance on relating data to the purpose for which it is collected or is to be used, and why sociologists express concern about the 'acontextual' nature of many administrative decision processes.
The easiest targets are those people about whom records exist, and whose records are accessible by government agencies. Hence some classes of people are subjected to frequent examination by several different agencies, whereas people who live relatively undocumented lives (e.g. those who operate in the so-called 'black economy') escape attention: "in practice, welfare recipients and Federal employees are most often the targets" [94].
In one of a series of GAO Reports urging the commencement of additional matching schemes, four anecdotes were selected to illustrate the kinds of cases which had come to light during pilot projects, and which, by implication, would give rise to millions of dollars of program savings. One related to "a 78-year-old housebound veteran" who in 1984 received a pension of about $3,500 p.a. Tax records suggested that he received in that year not nil interest as his Veterans' Affairs income questionnaire showed, but over $4,000. This would have precluded him from receiving any pension. The tolerance level between declared and apparent income was set at $100, and earnings of $1,000 or more were treated as being "substantial" [95]. Welfare recipients might reasonably complain that the precision applied was of a different order of magnitude from that used in pursuing white-collar criminals and in assessing the taxation payable by self-employed businessmen.
In addition to being readily investigated because of their dependent relationship with one or more of the matching agencies, many of these easy targets are ill-equipped to defend themselves, because they are generally little versed in the ways of information technology, government and the law. Reversal of the onus of proof is especially problematical for people with low incomes and for welfare recipients: "Computer-generated data is doubly dangerous. On the one hand, its supposed reliability and objectivity generates a degree of reverence that makes it most difficult to challenge. On the other hand, it is highly prone to error and misinterpretation. Proving these errors, however, is extremely difficult" [96].
The DHSS has acknowledged that social equity problems are not merely a moral issue: "computer matching, if approached too aggressively, can have some unfortunate side-effects. It can threaten and compromise the service orientation of a department, and in the process engender considerable resistance by front-line eligibility assistance workers. And, not least of all, it can actually undermine public credibility in public assistance programs" [97].
Beyond these rational and describable concerns, computer matching attracts a significant amount of sensationalist treatment, particularly in the lower echelons of the media. The 'Big Brother' spectre is invoked intemperately, inaccurately, and with monotonous regularity; and discussions of human identification numbering are inevitably punctured by allusions to 'the mark of the devil' in Revelations.
Such irrationality often underlies popular movements, and some of these movements are successful in achieving their objectives. It is arguable that a loss of public confidence in and support for organisations could arise, if they are perceived to focus on minor transgressions by 'the little people', rather than addressing larger, but inevitably more difficult, issues. A prevailing climate of suspicion is likely to result in alienation of data subjects from their social institutions.
The danger exists that data surveillance techniques such as computer matching may fuel the disaffection of sufficient people to encourage anarchic developments in social organisation. In sympathy with the 'black economy', the 'black information society' may be stimulated - a proportion of society who mislead and lie as a matter of course, on the not illogical basis that government agencies, remote from the realities of everyday existence and highly impressed with their information-based processes, can be rendered impotent by manifold inconsistencies among their copious data.
This sub-section focuses on more specific matters relating to a number of aspects of the data, the matching step, and the use of the results.
As depicted by Exhibit 2, there is a variety of ways in which data may come to be in an organisation's possession. Importantly:
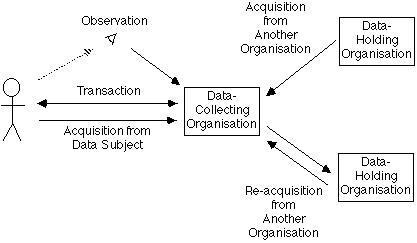
Data is collected with particular purposes in mind, and even within-agency matching may involve data with different purposes; for example, the Australian Taxation Office holds data relating to taxation, and data relating to maintenance payments to spouses and children. The use of data arising in respect of one function to support a distinctly different function represents a breach of the vital OECD Data Protection Guideline regarding Purpose of Collection. Government agencies in some countries have circumvented this protection by relying upon vague statements of objectives for computer matching, such as 'the administration of the Department's programs'.
Information privacy concerns are much greater where the computer matching involves two or more sets of data acquired by different organisations, especially where the purposes of the two systems are not the same.
In the case of data transfer between agencies in the same tier of government (e.g. between U.S. Federal agencies, or between the agencies of a particular State of that Union), government agencies sometimes adopt the pretence that they are members of a monolithic public or civil service. This enables them to claim that all data transfers between government agencies are internal rather than external transfers. It is vital to information privacy that such totalitarian tendencies are resisted, and all inter-agency data flows treated as being inter-organisational [98].
As a matter of administrative effectiveness and efficiency, clear definitions should exist of the meaning of all the data-items, groups of related data-items (such as the elements of an address), records and files involved in computer matching. In practice, however, the meaning of a significant proportion of data is either never explicitly defined, or is subject to change over time without the changes being formally recorded. Although it is arguable that meaning is a concept applicable only when data is used, it is incumbent on organisations to make clear the definitions which it is intended be associated with data which exist within its systems.
Many apparently common data-items are capable of a variety of interpretations. Is a de facto spouse a 'spouse'? Is a non-dependent child, or a dependent adult son or daughter, a 'child'? Is a child of separated parents a dependent of each or of both of them? Is 'income' to be understood as gross, or net of expenses incurred in earning it, or net of tax as well? Does it include only earned income, or also unearned income (such as interest)? And over what period of time is it to be averaged - a single weekly or fortnightly pay-period, a year, or many years (as is applied in some countries to farmers' income)? When matching and inferencing processes are applied to such common data-items, there is significant risk of designer or investigator misunderstanding and/or machine misprocessing. The greatest dangers arise not from unusual data-items, but in respect of widely used but subtly different data.
Some clusters of organisations have responded to inconsistencies among their definitions of critical data-items by migrating toward a common standard; for example, common identifiers can be used precisely as they are defined by their originating bodies (e.g. the DHHS in respect of the SSN and the Australian Taxation Office in respect of the Tax File Number). Where names and addresses are part of the matching or inferencing algorithms, many conventions need to be harmonised to account for the enormous richness involved: for all of the sophistication of the name standardisation routines they were applying, the Australian Department of Social Security reported that as late as 1992 they had had problems with surnames which had "non-alphabetical characters such as an apostrophe (for example, O'Connor) or contained a blank character (for example Da Vinci)" [99]. The first example was particularly apt, as it was the name of the Australian Privacy Commissioner!
In the late 1980s, there was a tendency among Australian Commonwealth Government agencies to define 'income' in all benefits programs in the same manner as income is defined for the purposes of taxation administration. The problems involved were exemplified by a difficulty encountered in the large-scale parallel matching program. At least one element of income (lump sum payments) continued to be treated differently in the various statutes authorising the programs, resulting in erroneous inferencing [100]. In any case, alignment of key data-items to assist front-end verification and computer matching represents a compromise of the primary objectives of each of the programs in order to serve a secondary purpose. It is clear evidence of subordination of service to control objectives.
A further aspect of consequence in particular circumstances is the 'temporal applicability' of a definition. Remedial actions by organisations are generally retrospective, and the definition of an item may be different at the time at which the action is taken, from the time to which the action relates (e.g. the current definition of income for taxation purposes may well be different from that applicable to the particular taxation return under dispute).
Any decision-making process is at risk of reaching inappropriate or unfair conclusions if the people involved are permitted to use data which has no logical bearing on the matter - every decision-maker has experiences, biases and foibles which may lead him or her to apply possibly unconscious, but decidely extraneous criteria. For this reason, a key privacy protection is the requirement that personal data not be used or disclosed unless it is relevant to the decision being made. Data is relevant to a decision if it can be shown that, depending on whether the data is or is not available to the decision-maker, a different outcome could result.
To establish whether data is relevant to a decision, two tests need to be applied. The first is whether the data-item is in any circumstances capable of influencing the decision. In many jurisdictions, some items of information are specifically precluded from being used in some classes of decision and should therefore not be available to decision-makers; for example, gender, marital status, age, sexual preferences, religious persuasion and political affiliation may be illegal bases for discriminating between alternative applicants for a job. There are other data-items which it may be not illegal to use, but which are irrelevant, or only tangentially relevant to a decision; for example, whether a woman has children and if so what age they are are generally irrelevant to an employment decision, whereas her availability to work during the hours after children come home from school may be an important factor.
The second test of relevance is concerned with the particular value of the data-item in each particular case; for example, whether a person suffers from a disability or chronic disease such as colour blindness or asthma is irrelevant to most employment decisions, and even information about deafness or the lack of a limb is only relevant to some.
The concept of data quality, sometimes referred to as 'data integrity', is a complex of criteria which must be satisfied if decision-making quality is to be achieved. This sub-section identifies key considerations. In addition to standard MIS texts, see [101] and [102].
The criterion of accuracy is important, but easily misunderstood. At least two tests must be applied. The first is correctness, by which is meant the extent to which the content of the data-item corresponds to the attribute of the real-world entity which it purports to measure. One common source of difficulties is lack of information about the measurement scale against which the data is to be understood; for example, an examination mark of 85 looks impressive until it is discovered that the possible mark was 250. Another example is the tendency for Grade-Point Averages awarded by educational institutions to creep upwards: even of the score of 85 was from a possible 100, the mean may have been 90 and the standard deviation 5.
Particular care is needed with textual data, particularly opinions and value-judgements, since the scale of measurement is especially unclear. For example, if a debtor is recorded as being in default on a payment when the debt is actually in dispute, the data is inaccurate. To protect the data's integrity, it is important for the identity of the person making the judgement, and the date, to be recorded with the data.
The other dimension of accuracy is the precision with which the data is recorded. For example, time-of-birth can be recorded as two digits representing the year (e.g. 01), four digits representing year (e.g. 1901), date of birth (e.g. 6 March 1901) or date and time of birth. An extreme example is the need when casting a horoscope for full precision of birth details, down to at least the minute and location of birth, but more workaday examples arise in respect of the detail needed in an audit trail of electronic financial transactions. Precision difficulties can arise in relation to, for example, benefits entitlements and rights of citizenship, permanent residency or asylum. Date and time of birth may need to be supplemented by the time-zone in which the birth occurred (or some surrogate such as city of birth). A related contemporary issue is the precision with which DNA-prints need to be measured and recorded in order to have evidentiary value.
Timeliness may be assessed from the perspective of the recording of the data, or of its use. On the one hand, the data must be 'up-to-date', in the sense that it reflects the present state of the relevant entity, and not some previous state. A typical difficulty in this regard is the out-of-dateness of the address held by a taxation authority, which generally does not receive notifications of change-of-address by its data subjects, but only an address current at the time of submission of an annual return. The other sense of timeliness is the promptness of delivery of the data to the decision-maker such that it is available at a time when it is useful to the decision; for example, a person's taxable income for a particular financial year is not knowable during that year, or indeed perhaps until long after the end of that year.
A further data quality criterion is completeness. By this is meant the requirement that data not be provided in such a way that, due to the absence of some associated item of data, a misinterpretation is invited. For example, a series of defaults on payments is incomplete if it is not accompanied by the information that the person concerned lives alone, and has been in a coma for the whole of the relevant period. A criminal record which shows a judgement and sentence is incomplete if it fails to also record the subsequent reversal on appeal, or pardon, or even the existence of an as yet unresolved appeal. Many less dramatic, but nonetheless significant situations occur.
A factor often overlooked is the erosion of data quality over time; for example the correspondence of a photograph to its subject decreases, in some circumstances very quickly. Some simple measures can be used to mitigate the effects of erosion, such as the recording of birthdate rather than age, and the recording of the month during which an address was last confirmed. In some jurisdictions, criminal records data is expunged after the expiry of a pre-determined period after the date of the offence or the date of release from custody. The justification for this is that the value of the data in sentencing decreases to the point where it is better to invite the person to retain their now 'clean' record.
There is no absolute measure of data quality, not even in respect of a specific data-item. Moreover there are many ways in which low data quality can arise. Some errors are intentional on the part of the data subject or some other party, but many are accidental, and some are a result of design deficiencies such as inadequate coding schemes and inadequate data capture and/or validation procedures. Data quality costs money, and in general higher data quality costs considerably more money. It is only natural for each organisation to select an appropriate trade-off between cost and quality according to its perception of the needs of the function for which the data is used. For many organisations, it is cost-effective to ensure high levels of accuracy only of particular items (such as invoice-amounts), with broad internal controls designed to ensure a reasonable chance of detecting errors in less vital data.
Data quality does not simply occur, but arises because particular features of the collection process and/or of the collecting system ensure quality. The general term for these features is data quality assurance. One element is the application of validation or editing rules at the time of capture. Another is the application of controls at the time of processing or use. For example, before a decision is made adverse to the interests of a data subject, they may be informed of the reason for the proposed decision, and given the opportunity to contest the quality of the data on which it is based. A critical feature is the existence of an audit trail, such that the origins of data can be traced, in order to resolve disputes about quality.
The vast majority of data systems operators are quite casual about the quality of most of their data. For example, the OTA reported that few U.S. federal government agencies have conducted internal audits of data quality 103. Even in systems where a high level of integrity is important, empirical studies have raised serious doubts [104]. In a study of criminal records systems, 54% of Federal records and 74% of Federal disseminations were found to have some significant quality problem, and sample surveys of State systems suggested that quality problems at that level were even more extreme [105], [106]. Data quality appears to be generally not high, and while externally imposed controls remain very limited, it seems likely that the low standards will persist. The quality of data which is used to make important decisions should not only be subject to controls, but those controls should also be subject to external audits of data quality, preferably by an organisation which has an appropriate degree of independence and which represents the interests of all stake-holders.
All of these criteria are important in normal administrative systems. They become even more important when computer matching is undertaken. The reason is that quality problems are compounded by computer matching, because the whole purpose of the matching activity is to detect differences. Quality problems in relation to data-items used in the matching activity can result in differences which are spurious, but which are interpreted by the data scrubbing, matching, inferencing and/or filtering algorithms as being significant.
The quality level which was appropriate to the original function may not be appropriate to the new purpose for which the computer matching is performed. HUD confirmed that there have been instances in which data quality was so low that a proposed matching program was aborted during the preliminary examination stage [107]. Moreover, data from multiple sources and/or collected for multiple purposes has been the subject of different trade-offs, and this alone creates dangers of erroneous matching and inferencing. This issue is particularly important in inter-agency and inter-system matches, and where the matched data is used to make decisions seriously adverse to the interests of the data subject, as in matching programs relating to welfare, taxation and criminal justice administration.
The complexities of each system (particularly a country's major data systems such as taxation, social welfare and health insurance) are such that few specialists are able to comprehend any one of them fully. It challenges the bounds of human capability to appreciate and deal with the incompatibilities between data, sourced from different systems, and of varying meaning and quality, and to handle the matched data with appropriate care. Computer matching should never be undertaken without the greatest caution and scepticism. This is especially so in the case of large-scale, repetitive and routinised programs.
Depending on the nature of the data, there may be additional characteristics which require consideration. One such question is sensitivity. This is usually regarded as referring to race, religious and political affiliations, and sexual preferences. In some cultures and some circumstances a wide variety of other data may also be regarded as sensitive, including financial matters, medical information (e.g. the nature of treatments and pharmaceuticals provided to a person) and household structure (e.g. the absence of a male may mark the household as a target for crime). For some people, even their date of birth is sensitive data.
The question also arises as to whether any privileges exist in relation to the data. In some countries this is the case in confidential relationships, such as those between doctor and patient, and priest and congregation.
Related to the notion of 'completeness' is the context within which the data is to be understood. It would, for example, be unworldly to expect the social mores of the time and culture to be captured into a database as a step in ensuring the completeness of data. On the other hand, when the data is about to be used, it is desirable that the decision-maker consider whether the context in which it arose is relevant. Otherwise, since the decision-maker is remote from the person affected by his decision, some insensitivity in decision-making is an almost inevitable result of computer matching.
One example of a situation in which context may play an important role is information about the person's racial background; for example the United States, Canada, Australia and New Zealand all make provision for the cultures of their small remaining indigenous populations. They also recognise the transitional period required for new immigrants. Other examples of contextual matters are organisational norms and practices, both official and informal; the geographic location of relevant activity (e.g. financial inducements to purchase, which would be illegal in the host country, may be legal or at least tolerated, and even commonplace, in a foreign country); the level of law and order in the region at the relevant time (e.g. loan default might be treated more leniently where it occurs during a period of riots, civil war, invasion or natural catastrophe); and changing attitudes to, for example, the Committee on Unamerican Activities, the Vietnam War, Yasser Arafat, Oliver North, and, in the coming years, perhaps even Communism, the Ayatollah Khomeini, and Colonel Ghadaffi.
These points have been made more graphically elsewhere: "information, [even today], is no more than it has ever been: discrete little bundles of fact, sometimes useful, sometimes trivial, and never the substance of thought [and knowledge] ... The data processing model of thought ... coarsens subtle distinctions in the anatomy of mind ... Experience ... is more like a stew than a filing system ... Every piece of software has some repertory of basic assumptions, values, limitations embedded within it ... [For example], the vice of the spreadsheet is that its neat, mathematical facade, its rigorous logic, its profusion of numbers, may blind its user to the unexamined ideas and omissions that govern the calculations ... garbage in - gospel out" [108].
In any matching programme, the possibility exists that the data-items may have been incorrectly captured, and hence the question arises as to the extent to which validation has been undertaken. For example, on occasions one person nominates another person's identification code or name in his or her dealings with an organisation, and as a result computer matching will associate that data with the wrong person. The same problem may arise through intent, or as a result of error by the individual or by the organisation which records the data. The risk of such errors arises at the time that an organisation originally collects its standing or master-file data, and again on every occasion that a transaction takes place.
Matching may work fairly well in circumstances in which people have an apparent interest in being readily associated with the data stored about them. The procedures are less effective where the control functions of the system are perceived by the data subject to dominate the service objectives, as has always been the case with taxation authorities, and is often so with welfare agencies. Matching is much more difficult to apply where the data subject has a clear self-interest in frustrating the organisation's purpose, e.g. in criminal investigation and national security operations.
Matching algorithms may result in zero, one, several or many 'putative hits', and some means of ambiguity resolution is needed. Approaches which can be taken include:
Different alternatives may be appropriate to particular circumstances. It must be appreciated, however, that in many cases it is not possible to reach an unambiguous conclusion, and serious danger exists that any administrative judgement made or action taken will be based on justification which is inadequate, ineffective, inequitable and/or wrong in law.
In principle, a matching algorithm's effectiveness may be measured on the basis of the error-rate. This might be interprested as the proportion of spurious matches or false hits, plus undetected matches or false misses. In practice, however, this is not easy, because it is seldom economically practicable to identify the errors. As a result, it appears that quality assurance and the exercise of control over the effectiveness of matching algorithms are very difficult and expensive, and the auditability of those controls very limited.
Because so few contemporary identification schemes use a physiological identifier, they are of, at best, moderate integrity. Rather than individuals themselves, the subject of surveillance is data which purports to relate to them. As a result, there is a significant risk of wrong identification, and the association of data with the wrong person [109], [110].
Identification quality problems are compounded by computer matching. The rules applied by each organisation in deciding on its person-identifier are of necessity somewhat arbitrary, and the strong likelihood is that the choices made by the two organisations are different, at least in regard to the details. Characteristics as simple as the sequence of parts of a name, and the inclusion or exclusion of second initial in an identifying routine, can become significant technical challenges when two sets of records are merged.
To address such difficulties, there is a trend toward the use of common identifiers. This has been noticeable in the United States through the widespread use of the Social Security Number (SSN), in Canada where the Parliament has recently acted to curb the proliferation in use of the Social Insurance Number (SIN), and in Australia where successive attempts have been made to establish an Australia Card number (which failed [111]), and to enhance and extend the Tax File Number (which is progressively succeeding [112]). The movement in Australia has followed the conclusions reached by a report on fraud in government, which said: "Agencies should record identification and locator information, as far as possible, in standard form to facilitate matching ... Naturally, clients are free to call themselves as they please ... The Commonwealth is equally entitled to call the client by a standard name" [113].
Matching techniques which are based on common data-items appear likely to more easily achieve a reasonable level of quality than those which are based on complex rules inter-relating a set of data-items with imprecise and differing definitions. Even in those cases, however, allowance must be made for both false hits and false misses. For example, persons may have (intentionally or unwittingly) provided an inappropriate (but valid) identifier to one of the organisations involved, or the organisation may have incorrectly processed the data, e.g. by applying the right number to the wrong person's data. This tends to generate both a false miss and a false hit.
It is important that matching algorithms be subject to controls, and that the controls be subject to audit. This may imply for many organisations which conduct computer matching a significant increase in the degree of formality which is applied.
When matching has been completed, and decisions are made and action is taken on the basis of the combined data, further concerns arise. At the heart of the freedoms which have been won for citizens of free countries during the last few centuries is the right to know one's accuser, the accusation, and the evidence on which the accusation is based. This implies that the data subject be informed that the origin of a decision lay in a particular computer matching run. Moreover, the data subject should have access to the data on which the decision was based, to provide a form of validation, and to provide the necessary information to enable a defence to be mounted.
It may seem unreasonable to call into question whether due process is being respected by organisations who are using the results of computer matching runs. Certainly there have been claims by various U.S. agencies in Hearings before Congressional Committees that due process provisions pre-existed the 1988 Act regulating computer matching. It is increasingly common, however, for guilt to be presumed. In taxation administration, for some time now the onus has been on tax-payers to prosecute their innocence. This inversion was knowingly authorised by a Parliament concerned to ensure effective administration. Much more disturbing is that the inversion of the onus of proof is tending to proliferate, without explicit legislative consideration (see, for example [114]).
Further concerns relate to the retention and re-use of data arising from a matching run, and the subsequent re-disclosure of such data. A case study demonstrating how presumptive such uses can be involved a change to a record in the Australian Passports Office on the basis of a matching run against the Electoral Register. As a result of inadequate procedures in the Electoral Office, the inference drawn by the Passports Office's matching run was wrong. By the time the mistake came to light the audit trail no longer existed and careful negotiations by a person well aware of the processes within government agencies were necessary to ensure that the whole story came to light and the specific problem could be overcome [115].
The previous section has identified a large number of considerations which make it necessary for computer matching to be subject to controls.. This section identifies factors which tend to restrain agencies from applying computer matching, or to cause them to do so carefully, and assesses their effectiveness.
The use of matching may be limited by the exercise of countervailing political power by the class of data subjects affected by the process, by their representatives, or by the general public. Given the imbalance of power between organisations and individuals, it is not realistic to expect this factor to be of any great significance except in particular circumstances; for example, a particular individual who is affected by the process may be influential, or may attract the active support of some influential person or group, or may attract the attention of the mass media to the matter. In practice, the most common classes of subject who are affected by computer matching are welfare recipients and government employees, neither of which have much political influence. Occasional negative publicity may arise in respect of a particular program or case, but is likely to last only a short time, and have negligible impact on the agency's ongoing activities.
Another potential control is that a computer matching activity may incur the displeasure of some organisation, such as a competitor. In practice there is little evidence of such a mechanism having been operational.
There is the possibility of self-restraint being practised by the agency itself. One basis for this could be that matching is inconsistent with its objectives. In earlier years, many benefits-paying agencies regarded their service-related aims as primary. During the past two decades, with the growth in aggregate benefits payments, in the visibility of over-payments and in the dominance of economic over social concerns, welfare-related agencies in the U.S. and Australia have placed increasing emphasis on their control objectives. Self-restraint on the basis of incompatibility with client-service objectives appears on the basis of empirical research to be very limited. There is, however, evidence of a more self-interested motivation on the part of the Internal Revenue Service to limit the use of its data in matching programs. It has expressed opposition to such use on the grounds that this would compromise the voluntary tax system [116].
Other potential bases for agency self-restraint exist. For example, key members of the agency's management team might be guided by professional norms, or by an appreciation of the delicacy of public confidence in its institutions and the resultant need to respect constitutional rights and moral concerns. Relevant decision-makers appear not to have been subject to any explicit professional requirements for care in the use of powerful IT tools, however [117]. And the findings of a GAO study were that "we seldom encountered any expression of concern about the potential invasion of privacy that went beyond a matter of compliance with existing legislation and regulations" [118].
A factor that should not be overlooked is the extent to which general blundering constrains excesses by agencies in their use of computer matching. The quality of both computer-based and manually maintained data, and of data processing, case analysis and prosecution must all be high if the potential benefits are to be attained; for example, two major agencies failed over a series of years to exchange benefit-recipient death information purely because of misunderstandings [119]. In addition, long delays and vague plans to refer cases to the FBI "for potential fraud review" have been detected [120]; and agencies are frequently unwilling to take further action where the recipient has died [121] or is no longer receiving benefits [122].
The intrinsic factor which might be expected to exercise the most significant degree of control over computer matching is economics: surely government agencies will not apply the technique in circumstances in which it is not worthwhile.
However, economic constraints will only be effective if the relationship between a program's costs and benefits are visible, and this is only likely if formal cost/benefit analysis is applied. The use of cost/benefit analysis in relation to computer matching was evaluated as part of this lengthy study, and is reported on in Clarke [123]. The conclusions reached were that cost/benefit analysis is seldom performed voluntarily, that there are many serious deficiencies in those few analyses which have become publicly available, and that programs are continued even after they have been clearly demonstrated to be financially unjustifiable.
The previous section argued that the negative impacts of computer matching are sufficiently serious to demand controls, and that natural or intrinsic controls are inadequate. The final section of this paper presents a framework for a regulatory regime for computer matching. It is normative because, in the absence of 'good' models, it is impractical for it to be derived from experience. The general principles proposed here are derived from previous proposals (and in particular [124] and [125]), and the analysis presented in the earlier sections of this paper.
This framework is intended to be generally applicable. In the few jurisdictions in which regulatory regimes are in place, it provides a basis for evaluating the existing controls. In other jurisdictions, the framework is intended to assist in the creation of codes appropriate to the particular social and economic culture, and legal structure and processes.
General principles are enunciated relating to the environment and infrastructure of regulation. These specify the need for effective information privacy laws, a privacy protection agency, effective computer matching laws, the denial of monolithic government, exceptional treatment rather than exemption, publicly visible justification and adaptive control. The detailed requirements of a legally enforceable code of practice are laid out in the Appendix.
The establishment of extrinsic controls over computer matching are very unlikely to be even embarked upon until comprehensive information privacy laws are in place. Unfortunately, the primary consideration in the formulation of privacy laws throughout the world has been that the efficiency of business and government should not be hindered. What was provided was an 'official response' which legitimated dataveillance measures in return for some limited procedural protections commonly referred to as 'fair information practices' [126], [127]. For a review of the origins of fair information practices guidelines, see [128]. See also [129] 130 and [131].
In the United States, the early discussions of protections, and in particular [132], resulted in the enactment of the Privacy Act 1974. President Ford threatened to veto that statute, and forced the proposed Privacy Commission to be reduced to a short term Study Commission [133]. The Commission's Report [134] implicitly accepted the need to make surveillance as publicly acceptable as possible, consistent with its expansion and efficiency [135]. Agencies had little difficulty subverting the Privacy Act. The President's Council for Integrity and Efficiency (PCIE) and the Office of Management and Budget (OMB) have worked not to limit computer matching, but to legitimise it.
The legitimation process has also been evident in developments in other countries and in international organisations. The OECD's 1980 Guidelines for the Protection of Privacy were quite explicitly motivated by the economic need for freedom of trans-border data flows. In the United Kingdom, the Government stated that its Data Protection Act of 1984 was enacted to ensure that U.K. companies were not disadvantaged with respect to their European competitors. The purpose of the 'EC'92 Directive', which has been under discussion within the European Community for several years, is the application of the limited 'fair information practices' tradition uniformly throughout Europe [136]. Because it would make it mandatory for European Community nations to prohibit the export of personal data to countries which do not provide 'an adequate level of protection', it would significantly increase the influence of international instruments such as the OECD's 1980 Guidelines.
There have been almost no personal data systems, or even uses of systems, which have been banned outright. Shattuck [137] reported that during the first five years, the unsympathetic interpretation of the U.S. Privacy Act by the supervising agency, the Office of Management and the Budget, resulted in not a single matching program being disapproved. Few sets of Information Privacy Principles appear to even contemplate such an extreme action as disallowing some applications of IT because of their excessive privacy-invasive nature. Exceptions include those of the New South Wales Privacy Committee [138], which are not legally enforceable, and, with qualifications, Sweden. This contrasts starkly with the conclusions of observers: "At some point ... the repressive potential of even the most humane systems must make them unacceptable" [139], emphasis in original; and "We need to recognize that the potential for harm from certain surveillance systems may be so great that the risks outweigh their benefits" [140].
The first requirement of a control regime for computer matching is comprehensive and universally applicable data protection legislation which achieves a suitable balance between the various economic and social interests, rather than subordinates information privacy concerns to matters of administrative efficiency.
Privacy protection regimes based on cases being brought by private citizens against the might of large information-rich and worldly-wise agencies have not worked, and are highly unlikely to do so in the future. To achieve appropriate balance between information privacy and administrative efficiency, it is necessary for an organisation to exist which has sufficient powers and resources to effectively represent the information privacy interest 141, [142], [143]].
It has been argued that, in the United States, "a small agency of perhaps sixty professionals drawn from legal, social science and information systems backgrounds" would provide sufficient resources to address the problem [144]. From the perspective of Australia and Canada, this would seem parsimonious for such a large country, but there can be little doubt that, given an appropriate set of powers, and sufficient independence from the Executive, it could make a significant difference to the balance of power.
It would be valuable to complement such a body with an effective option for individuals to prosecute and sue organisations which fail to comply with legal requirements. This can only come about if the requirements of organisations are made explicit, and this in turn is only likely to come about if detailed codes, prepared by a privacy protection agency on the basis of research and experience, are given statutory authority. In addition to valuable discussions in [145], [146], [147] and [148], elements of all of these can be found in Australian and Canadian legislation and practice.
There are two competing models. The conventional one involves the agency being required to balance information privacy against other interests (such as administrative efficiency), and is based on negotiation and conciliation rather than adversary relationships. This risks capture of the privacy protection agency by the other much larger, more powerful, information-rich and diverse agencies, as is occurring in Australia. Laudon argues strongly for the alternative - an agency which is explicitly an advocate for information privacy, and which can represent that interest before the courts and Congress [149].
Legislation is not an effective extrinsic control over computer matching practices if its primary function is to legitimise existing activities or proposed programs. The legislative packages brought forward by or for government agencies are based on those agencies' perceptions of their own needs, and do not reflect broader, public interests. If legislators support the balancing of economic against social objectives, they must be suspicious of agency-initiated Bills, and must instead specify the philosophy and objectives of Bills brought before Parliament.
Computer matching is a specific technique, and cannot be appropriately enabled and controlled by generalised legislation [150]. Either Parliaments must expend the effort to become competent in dealing with the issues, or they must create a specialist agency and invest it with the responsibility of bringing specific statutory instruments before it, dealing with specific programs or specific agencies.
Laudon concluded that "a second generation of privacy legislation is required" [151]. This second generation has since begun, with the United States somewhat improving control over computer matching with its 1988 Act; with Canada rolling back the uses of the Social Insurance Number and regulating data matching in 1989; and with Australia issuing draft Guidelines and passing its first (admittedly limited) second generation legislation in 1990 (after finally catching up with the first generation only at the beginning of 1989). The challenge is to regulate computer matching in such a way that it clears the path for worthwhile applications of the technique, while preventing unjustifiable information privacy intrusions.
It was noted earlier that, when it suits their interests, agencies adopt the attitude that the agencies of government form a monolith, and hence all data transfers are internal to government. This is inimical to the information privacy interest, and it is necessary for Parliaments to make clear that agencies are independent organisations for the purposes of data transfer, and that all data transfers are therefore subject to the rules regarding collection and dissemination.
In addition, there is a danger that privacy protections may be subverted by the concentration of functions and their associated data into large, multi-function agencies. Hence boundaries must be drawn not only between agencies but also between functions and systems.
'Virtual centralisation' of data by way of network connection, and data linkage via common identifiers, also embody extremely high information privacy risks. The 'national databank' agenda of the mid-1960s is being resuscitated by government agencies, and with it is coming pressure for a general-purpose identification scheme. These must be strenuously resisted if the existing balance of power between individuals and the State is not to be dramatically altered.
Care must be taken to ensure that exemptions do not rob privacy protection legislation of its effectiveness. The general principles of information privacy must be applied to all agencies and all systems, and the regulatory regime for computer matching to all programs. The widely practised arrangement of exempting whole classes must therefore be rolled back.
It is entirely reasonable, on the other hand, for the specific nature of controls to reflect the particular features of an organisation, system or program. This applies particularly to operations whose effectiveness would be nullified in the event of full or even partial public disclosure. In such instances, the privacy protection agency needs to be explicitly nominated as the proxy for the public, authorised in law to have access to sensitive operational data, but precluded in law from disclosing details to the public. Not only government agencies but also government business enterprises and private sector organisations have tenable claims for exceptional treatment along these lines.
Finally, the favoured status traditionally granted to defence, national security, criminal intelligence and law enforcement agencies must be rolled back. Parliaments must make these agencies understand that they are subject to democratic processes and that their distinctive and challenging functions and operational environments dictate the need for careful formulation and implementation of privacy protections, not for exemption.
It has been established that, on the prudent basis of the net financial benefits after all financial costs have been considered, the financial worth of many computer matching programs is at best in doubt, and in some cases is negative. This is not necessarily to say that those programs should not have been undertaken, because there are many factors, especially deterrence on the one hand and information privacy invasion on the other, which are not reducible to financial measures.
As Laudon noted, "a pattern has emerged among executive agencies in which the identification of a social problem [such as tax evasion, welfare fraud, illegal immigration, or child maintenance default] provides a blanket rationale for a new system without serious consideration of the need for a system" [152]. This 'blanket rationale' must be swept away. Computer matching programs must be subjected to conventional cost/benefit analysis, including estimation of the full range of actual and opportunity costs and financial benefits, quantification of as many as possible of the non-financial costs and benefits, and description of the non-quantifiable factors. Guides exist as to the nature of costs and benefits which should be considered [153], [154], [155]. See also [156].
It is insufficient, however, for a requirement to be imposed without a control mechanism to ensure its satisfactory implementation. The justification of each program needs to be reviewed by an organisation whose interests are at least independent of those of the proponent organisation, and perhaps even adversarial. While it may be unreasonable in some cases to ask agencies to make their full strategy publicly available (because of the harm this might do to the program's effectiveness), the arguments against publishing the justification for the program are far scantier. Prior cost/benefit analyses and post-program evaluations must be undertaken, be subject to review by the privacy protection agency, and be available to the public.
Technological developments have rendered some of the early information privacy protections ineffective: "new applications of personal information have undermined the goal of the Privacy Act that individuals be able to control information about themselves" [157]. See also [158] and [159]. If a proper balance between information privacy and other interests is to be maintained, processes must be instituted whereby technological change is monitored, and appropriate modifications to law, policy and practice brought about. This needs to be specified as a function of the privacy protection agency, and the agency funded accordingly.
Despite the long-standing dominance of the arguments of Westin [160], it is clear that the needs of administrative efficiency are at odds with individual freedoms. The power of computer matching techniques is far greater than it was two decades ago, and refinements and new approaches are emerging which will require further regulatory measures in the near future.
In addition to the general principles, detailed requirements must be imposed on organisations involved in computer matching. These are presented in the Appendix to this paper, and comprise pre-conditions to the commencement of a program, requirements regarding the conduct and aftermath of a program, general requirements, and definitions.
This framework has been applied to the protective regime which applies in the United States (based on the Computer Matching and Privacy Protection Act 1988), and that proposed for Australia (the Privacy Commissioner's Data Matching Guidelines). Both are seriously deficient in comparison with the normative framework [161].
Computer matching is a powerful dataveillance technique, capable of offering benefits in terms of the efficiency and effectiveness of government business greater than its financial costs. It is also a highly error-prone and privacy-invasive activity. Unless a suitable balance is found, and controls imposed which are perceived by the public to be appropriate and fair, its use is liable to result in inappropriate decisions, and harm to people's lives. In a tightly controlled society, this is inequitable. In a looser, more democratic society, it risks a backlash by the public against the organisations which perform it, and perhaps against the technology which supports it.
Brief background has been provided to the origins and technique of computer matching. Its impact has been analysed, and the need for controls established. Intrinsic controls have been shown to be insufficient to ensure that computer matching programs are accurate, equitable and socio-economically justified. A framework has been presented, which provides a basis for the preparation of effective regulatory measures in jurisdictions where none exists, and a tool for assessing the control regimes in place in those few countries which do have them.
Because of the current fashion of highly information-intensive procedures, and the inadequacy of the controls, the current boom in identification-based computer matching activity may be expected to continue for some years. Further refinements may be confidently expected in the data scrubbing, matching, inferencing and filtering steps, including the application of such techniques as direct access, multiple-file matching, associative memory, expert systems, neural networks and fuzzy logic.
A longer-term scenario can be constructed on the basis of experiences in information privacy issues generally. Occasional public backlashes will follow the publication of information about proposed new schemes, unjustified dataveillance, blunders and unfair behaviour on the part of one agency or another. These will generally be shortlived, and after the proposal has been (temporarily) withdrawn or the (expendable) Secretary or Minister has resigned, the grand momentum of government agency policies will resume. The level of public morality in relation to the provision of information to government agencies will fall lower, and the intrusiveness of government agency questioning of and about data subjects will increase, in order to provide the necessary additional data. The level of public confidence in government agencies will spiral lower still. Improvements to the integrity of identification, which had been withheld in the past, will be instituted. Faced with substantial failure, those schemes will be enforced using seriously repressive measures. The climate of public suspicion and animosity will be exacerbated, and the quality of data will fall lower still.
In due course, as the proportion of the public routinely indulging in multiple identities and noise-laden data increases, two further dataveillance tools will become more prominent. Identification-based matching will be first supplemented and then steadily supplanted by content-based matching, as the techniques develop in sophistication and throughput, and decrease in price. Meanwhile the capacity of distributed databases will be increasingly applied to the linkage of records about individuals, within and beyond the community of government agencies. Initially this will be significantly constrained by technical difficulties and to a limited extent by public opposition and the law. The short span of attention of the public, the ability of the government community to go slowly about its long-term plans with only limited interference from transitory Congressmen and Parliamentarians, the readily invokable economic imperative to use data efficiently, the unenforceability of most data protection laws, and the effective revocability of the remainder through seemingly minor but debilitating amendments will combine to enable government agencies to achieve a 21st century, 'virtual national databank', more powerful, more extensive and far more practicable than that conceived in the 1960s. A wide variety of inventive techniques will be used by many individuals to sustain their private space, and flourishing black economies and black information societies will make a mockery of government statistics.
Like any other scenario, this somewhat apocalyptic vision is a projection rather than a prediction. The analysis in this paper suggests, however, that it is a very plausible trajectory. If it is to be resisted, and the values of democracy and individual freedom sustained, powerful countervailing regulatory regimes must be instituted. Applications of information technology are changing the landscape of the societies in which we live. This paper has proposed a basis for exercising control over one currently important data surveillance technique.
This Appendix contains the detailed set of requirements which need to be imposed within the general framework presented in section 4 of this paper. Definitions are first provided. The requirements are then expressed which are applicable respectively prior to the commencement of a matching program, while it is being conducted, and during its latter stages. A final section contains requirements applicable to all phases.
The meanings of key terms used in these Detailed Requirements are as follows:
A computer matching program is only to be undertaken if the following conditions apply:
At the commencement of every computer matching program:
The objectives of the program, expressed in sufficient detail to enable the reader to gain a clear understanding of the purposes
The legal authorities and constraints under which each participating organisation is to perform its various activities, including:
What measures are being taken to deal with:
Each source organisation must, for every data item which it makes available to a computer matching run, clearly document the matters listed in Exhibit A3. The matching organisation must ensure that these matters have been documented, and refer to that document during the design and operation of the computer matching run. If data is to be acquired from a source organisation which may not have fully complied with these requirements (e.g. an agency of a government, or a corporation, outside the jurisdiction), special care is needed by the matching organisation.
The lead organisation must, in consultation with other participating organisations, design a quality assurance mechanism to ensure that outcomes are measured, analysed, documented and fed back to the appropriate organisation(s).
The following must be clearly documented:
For every data item supplied to a matching organisation, whether or not it is actually used in any part of the program:
For every data item supplied to a matching organisation, whether or not it is actually used in any part of the program:
If the data item is liable to misinterpretation unless used in conjunction with additional data, where that additional data is to be found
The organisation which undertakes data scrubbing must:
The matching organisation must:
The following matters must be clearly documented:
The precise matching algorithm used (e.g. phonex equivalence of family name, phonex equivalence of first given name and birthdate within two years)
For every source which is used in the computer matching process, the precise meaning of a record appearing on that file (e.g. "a person using that name and supplying those details has submitted at least one return to the organisation during the last fifteen years")
For every data item used in the matching process:
The organisation which undertakes inferencing must:
The organisation which undertakes filtering must:
An organisation must only use for the purposes identified in the program's Terms of Reference data which is disclosed for the purposes of a computer matching program or arises from such a program.
Before using data arising from a matching program, an organisation must:
No organisation may use the results of a computer matching program until and unless the conditions listed in Exhibit A5, regarding the data-handling processes, data quality controls, due process, opportunity to appeal and the consequences of the decision or action, have been satisfied.
The means whereby meaning is extracted from the matched data, including the data scrubbing, matching, inferencing and filtering steps, must be explicitly and clearly defined
Any secondary effects of the decision or action must be considered before the decision is made or the action is taken (e.g. the temporary withdrawal of a benefits card as a disciplinary measure may result in the person no longer being able to take advantage of additional benefits normally available from other sources, such as pensioner discounts)
These requirements apply to all uses of such data, including:
Where an organisation uses in a court process data that has been input to or generated from a computer matching program, the data, its source and relevant information concerning its quality must be disclosed as part of the pre-trial discovery procedures.
An organisation must not retain personal data used in or arising from a computer matching program any longer than is reasonably necessary for the fulfilment of the objectives specified in the Terms of Reference. In general:
An organisation must dispose of personal data used in and arising from a computer matching program in a manner which ensures the data's security.
Participating organisations must measure, analyse, document and feed back to the appropriate participating organisations information regarding the quality of the data, processing steps and outcomes of a computer matching program.
A post-program evaluation must be undertaken shortly after the completion of the computer matching program, to evaluate it against the original (and, where appropriate, amended) Terms of Reference and Prior Cost/Benefit Analysis, and to make information available to assessments of subsequent proposals for computer matching programs. Such a post-program evaluation must:
Where a computer matching program comprises multiple computer matching runs, post-evaluation must be performed at least annually.
All aspects of computer matching programs must be under the purview of the privacy protection agency. The agency must have the power to disapprove any proposed program or proposed variation to a program, and to impose conditions on a program's implementation.
In general, all information about a computer matching program must be publicly available in advance of the first run, e.g. through publications of the relevant organisation and of the privacy protection agency.
Where one or more participating organisations wishes to claim in respect of particular information (e.g. the matching algorithm) that publication would be detrimental to the conduct of the program, or would be in breach of secrecy provisions, the argument and the information must be submitted in writing to the privacy protection agency. If it accepts the argument, the privacy protection agency must explicitly authorise the non-publication, partial publication or deferral of publication, as appropriate, making clear precisely what information is being granted confidentiality.
The privacy protection agency must report to the public periodically concerning dispensations granted, in such a manner that disclosure of information prejudicial to the conduct of approved programs is avoided.
The conduct of a computer matching program must be consistent with the Terms of Reference. Any material modifications arising during the conduct of the program must be reviewed by all participating organisations, agreed by all of them prior to the modifications being implemented, notified to the privacy protection agency, and not disapproved by that agency.
Participating organisations must take appropriate precautions at all stages to ensure that personal data available to, used in and arising from a computer matching program:
Participating organisations must provide staff with training in all aspects of computer matching, and of these Guidelines, that are relevant to tasks they may perform in relation to a computer matching program.
Participating organisations must ensure that all documentation relating to a computer matching program is maintained in a form which facilitates access and assessment by:
Participating organisations must arrange for convenient access by individuals to records concerning themselves, including records used in and generated by computer matching programs, in compliance with the provisions of all relevant laws, such as Freedom of Information legislation.
Participating organisations must maintain all documentation in a form which facilitates the audit of the organisations' compliance with these Guidelines by internal and external auditors. Participating organisations must give consideration to including audit of compliance with these Guidelines as part of the organisation's internal audit programs.
ALRC (1983) 'Privacy' Aust. L. Reform Comm., Sydney, Report No. 22 (1983)
Berman J. & Goldman J. (1989) 'A Federal Right of Information Privacy: The Need for Reform' Benton Foundation Project on Communications & Information Policy Options, 1776 K Street NW, Washington DC 20006, 1989
Bennett C. (1992) 'Regulating Privacy: Data Protection and Public Policy in Europe and the United States' Cornell University Press, New York, 1992
Bezkind M. (1986) 'Data Accuracy in Criminal Justice Information Systems: The Need for Legislation to Minimize Constitutional Harm' Comput. / Law J. 6,4 (Spring 1986) 677-732
Burnham D. (1983) 'The Rise of the Computer State' Random House, New York, 1983
Clarke R.A. (1987a) 'Just Another Piece of Plastic for Your Wallet: The Australia Card' Prometheus 5,1 June 1987a. Republished in Computers & Society 18,1 (January 1988), with an Addendum in Computers & Society 18,3 (July 1988)
Clarke R.A. (1987b) 'Human Identification in Records Systems', Working Paper available from the author (1987)
Clarke R.A. (1988) 'Information Technology and Dataveillance' Comm. ACM 31,5 (May 1988) Re-published in C. Dunlop and R. Kling (Eds.), 'Controversies in Computing', Academic Press, 1991
Clarke R.A. (1991) 'Computer Matching Case Report: Rental Assistance for Low-Income Families' Working Paper available from the author (December 1991)
Clarke R.A. (1992a) 'Computer Matching in the Social Security Administration', Working Paper available from the author (January 1992)
Clarke R.A. (1992b) 'The Resistible Rise of the National Personal Data System' Software L.J. 5,1 (February 1992)
Clarke R.A. (1992c) 'Computer Matching in Australia', Working Paper available from the author (May 1992)
Clarke R.A. (1993) 'Dataveillance by Governments: The Technique of Computer Matching' Working Paper available from the author (July 1993)
Clarke R.A. (1994) 'The Effectiveness of Cost/Benefit Analysis as a Control Over Data Surveillance Practices' Working Paper available from the author (January 1994)
Davies S. (1992) 'Big Brother: Australia's Growing Web of Surveillance' Simon & Schuster, Sydney, 1992
DSS (1991) 'Data Matching Program (Assistance and Tax): Report on Progress' Dept of Social Security and Data Matching Agency, Dept of Social Security, Canberra (October 1991)
DSS (1992) 'Data Matching Program (Assistance and Tax): Report on Progress - October 1992' Dept of Social Security, Canberra (October 1992)
EC (1992) 'Amended Proposal for a Council Directive Concerning the Protection of Individuals in Relation to the Processing of Personal Data', European Community, Brussells, OJ No L 123, 8 May 1992
FACFI (1976) 'The Criminal Use of False Identification' U.S. Federal Advisory Committee on False Identification, Washington DC, 1976
Flaherty D.H. (1989) 'Protecting Privacy in Surveillance Societies', Uni. of North Carolina Press, 1989
Fraud (1987) 'Review of Systems for Dealing with Fraud on the Commonwealth', Aust. Govt. Publ. Service (March 1987)
GAO (1983a) 'Action Needed to Reduce, Account For, and Collect Overpayments to Federal Retirees' Comptroller General of the United States, General Accounting Office, Washington DC, 1983
GAO (1983b) 'Computer Matches Identify Potential Unemployment Benefit Overpayments' Comptroller General of the United States, General Accounting Office, Washington DC, 1983
GAO (1984a) 'GAO Observations on the Use of Tax Return Information for Verification in Entitlement Programs' Comptroller General of the United States, General Accounting Office, Washington DC, 1984
GAO (1984b) 'Better Wage-Matching Systems and Procedures Would Enhance Food Stamp Program Integrity' General Accounting Office, Washington DC, 1984
GAO (1985a) 'Eligibility Verification and Privacy in Federal Benefit Programs: A Delicate Balance' General Accounting Office, GAO/HRD-85-22, 1985
GAO (1985b) 'A Central Wage File for Use by Federal Agencies: Benefits and Concerns' General Accounting Office, GAO/HRD-85-31 (May 1985)
GAO (1986a) 'Social Security: Pensions Data Useful for Detecting Supplemental Security Payment Errors' General Accounting Office, GAO/HRD-86-32, Mar 1986, 14 pp.
GAO (1986b) 'Computer Matching: Assessing Its Costs and Benefits' General Accounting Office, GAO/PEMD-87-2, Nov 1986, 102 pp.
GAO (1986c) 'Computer Matching: Factors Influencing the Agency Decision-Making Process' General Accounting Office, GAO/PEMD-87-3BR, Nov 1986, 30 pp.
GAO (1987) 'Welfare Eligibility: Deficit Reduction Act Income Verification Issues' General Accounting Office, GAO/HRD-87-79FS, May 1987, 93 pp.
GAO (1988) 'Veterans' Pensions: Verifying Income with Tax Data Can Identify Significant Payment Problems' General Accounting Office, GAO/HRD-88-24, Mar 1988, 100 pp.
GAO (1989a) 'Interstate Child Support: Case Data Limitations, Enforcement Problems, Views on Improvements Needed' General Accounting Office, GAO/HRD-89-25, Jan 1989, 82 pp.
GAO (1989b) 'Child Support: State Progress in developing Automated Enforcement Systems' General Accounting Office, GAO/HRD-89-10FS, Feb 1989, 25 pp.
GAO (1990a) 'Computer Matching: Need for Guidelines on Data Collection and Analysis' General Accounting Office, GAO/HRD-90-30, Apr 1990, 16 pp.
GAO (1990b) 'Veterans' Benefits: VA Needs Death Information From Social Security to Avoid Erroneous Payments' General Accounting Office, GAO/HRD-90-110, Jul 1990, 14 pp.
GAO (1990c) 'Computers and Privacy: How the Government Obtains, Verifies, Uses and Protects Personal Data' General Accounting Office, GAO/IMTEC-90-70BR, Aug 1990, 68 pp.
GAO (1991a) 'Federal Benefit Payments: Agencies Need Death Information From Social Security to Avoid Erroneous Payments' General Accounting Office, GAO/HRD-91-3, Feb 1991, 23 pp.
GAO (1991b) 'Computer Matching Act: Many States Did Not Comply With 3-Day Notice or Data-Verification Provisions' General Accounting Office, GAO/HRD-91-39, Feb 1991, 29 pp.
GAO (1991c) 'Welfare Benefits: States Need Social Security's Death Data to Avoid Payment Error or Fraud' General Accounting Office, GAO/HRD-91-73, Apr 1991, 13 pp.
GAO (1993) 'Computer Matching: Quality of Decisions and Supporting Analyses Little Affected by 1988 Act' GAO/PEMD-94-2, 18 October 1993
GIJAS (1991) 'Computer Matching and Privacy Protection Amendments of 1990: Hearing Before the Government Information, Justice and Agriculture Subcommittee on H.R. 5450, September 11, 1990' U.S. Government Printing Office, 1991
Greenberg D.H. & Wolf D.A. (1985) 'Is Wage Matching Worth All the Trouble?' Public Welfare (Winter 1985) 13-20
Greenberg D.H. & Wolf D.A. (with Pfiester J.) (1986) 'Using Computers to Combat Welfare Fraud: The Operation and Effectiveness of Wage Matching' Greenwood Press Inc., Oct 1986
Greenberg D. & Yudd R. (1989) 'Food Stamp Program Operations Study: Computer Matching: A Review of Exemplary State Practices in the FSP' The Urban Institute, 2100 M St NW, Washington DC 20037, for the U.S. Dept. of Agriculture, Food and Nutrition Service, July 1989
Greenleaf G.W. & Clarke R.A. (1984) 'Database Retrieval Technology and Subject Access Principles' Aust. Comp. J. 16,1 (Feb, 1984)
Henderson L. (1992) 'Case Study in Data Integrity: Australian Passports Office' Working Paper available from the author, Department of Commerce, Aust. National Uni. (March 1992)
HEW (1973) 'Records, Computers and the Rights of Citizens' U.S. Dept of Health, Education & Welfare, Secretary's Advisory Committee on Automated Personal Data Systems, MIT Press, Cambridge Mass., 1973
HHS (1983a) 'Computer Matching in State Administered Benefit Programs: A Manager's Guide to Decision-Making' Dept. of Health and Human Services, 1983
HHS (1983b) 'Inventory of State Computer Matching Technology' Dept. of Health and Human Services, 1983
HHS (1984) 'Computer Matching in State Administered Benefit Programs' U.S. Dept. of Health and Human Services, June 1984
Holden N., Burghardt J.A. & Ohls J.C. (1987) 'Final Report for the Evaluation of the Illinois On-Line Cross-Match Demonstration' Mathematica Policy Research, Sep. 11 1987, for U.S. Dept. of Health and Human Services, Office of Family Assistance
Kirchner J. (1981) 'Privacy: A history of computer matching in federal government programs' Computerworld (December 14, 1981)
Kling R. (1978) 'Automated Welfare Client Tracking and Welfare Service Integration: The Political Economy of Computing' Comm ACM 21,6 (June 1978) 484-93
Kusserow R.P. (1983) 'Inventory of State Computer Matching Technology' Dept. of Health & Human Services, Office of Inspector-General (March 1983)
Kusserow R.P. (1984a) 'The Government Needs Computer Matching to Root out Waste and Fraud' Comm ACM 27,6 (June 1984) 542-545
Kusserow R.P. (1984b) 'Computer Matching in State-Administered Benefit Programs' Dept. of Health & Human Services, Office of Inspector-General (June 1984)
Langan K.J. (1979) 'Computer Matching Programs: A Threat to Privacy?' Columbia J. of Law and Social Problems 15,2 (1979)
Laudon K.C. (1979) 'Computers and Bureaucratic Reform' Wiley, New York, 1974
Laudon K.C. (1986a) 'Data Quality and Due Process in Large Interorganisational Record Systems' Comm. ACM 29,1 (January 1986) 4-11
Laudon K.C. (1986b) 'Dossier Society: Value Choices in the Design of National Information Systems' Columbia U.P., 1986
Lindop (1978) 'Report of the Committee on Data Protection' Cmnd 7341, HMSO, London (December 1978)
Madsen W. (1992) 'Handbook of Personal Data Protection' MacMillan Publishers, London, 1992
Marx G.T. (1985) 'The New Surveillance' Technology Review (May-Jun 1985)
Marx G.T. & Reichman N. (1984) 'Routinising the Discovery of Secrets' Am. Behav. Scientist 27,4 (Mar/Apr 1984) 423-452
Neumann P. (1976-) ''RISKS Forum' Software Eng. Notes since 1,1 (1976) and in Risks.Forum on UseNet
NSWPC (1977) 'Guidelines for the Operation of Personal Data Systems' New South Wales Privacy Committee, Sydney, 1977
O'Connor K. (1990) Paper for the Communications & Media Law Association, available from the Privacy Commissioner, Human Rights & Equal Opportunities Commission, G.P.O. Box 5218, Sydney, 26 April 1990
OECD (1980) 'Guidelines for the Protection of Privacy and Transborder Flows of Personal Data' Organisation for Economic Cooperation and Development, Paris, 1980
OMB (1979a) 'Guidelines to Agencies on Conducting Automated Matching Programs' Office of Management and Budget March 1979
OMB (1979b) 'Privacy Act of 1974: Supplemental Guidance for Matching Programs' 44 Fed. Reg. 23, 138 (1979)
OMB (1982a) 'Computer Matching Guidelines' Office of Management and Budget , May 1982
OMB (1982b) 'Privacy Act of 1974: Revised Supplemental Guidance for Conducting Matching Programs' 47 Fed. Reg. 21, 656 (1982)
OMB (1983) 'Agency Computer Match Checklist' Memorandum M-84-6, Office of Management and Budget, December 29, 1983
OMB/PCIE (1983) 'Model Control System for Conducting Computer Matching Projects Involving Individual Privacy Data' Office of Management and Budget & President's Commission for Integrity & Efficiency 1983
OTA (1986) 'Federal Government Information Technology: Electronic Record Systems and Individual Privacy' OTA-CIT-296, U.S. Govt Printing Office, Washington DC, Jun 1986
PCA (1990) 'Data Matching in Commonwealth Administration: Discussion Paper and Draft Guidelines' Privacy Commissioner, Human Rights & Equal Opportunities Commission, G.P.O. Box 5218, Sydney, Australia (October 1990) (56 pp.)
PCC (1989) 'Data Matching Review: A Resource Document for Notification of the Privacy Commissioner of Proposed Data Matches' Privacy Commissioner, 112 Kent, Ottowa, Canada (July 1989)
PCIE (1982) 'Reference Paper on Computer Matching' President's Council on Integrity and Efficiency, Washington DC, 1982
PCIE (1983) 'Incentives and Disincentives to Computer Matching' President's Council on Integrity and Efficiency, Washington DC, 1983
PPSC (1977) 'Personal Privacy in an Information Society' Privacy Protection Study Commission, U.S. Govt. Printing Office, July 1977
Reichman N. (1987) 'Computer Matching: Toward Computerized Systems of Regulation' Law & Policy 9,4 (October 1987) 387-415
Reichman N. & Marx G.T. (1985) 'Generating Organisational Disputes: The Impact of Computerization' Proc. Law & Society Ass. Conf., San Diego, June 6-9, 1985
Roszak T. (1986) 'The Cult of Information' Pantheon 1986
Rule J.B. (1974) 'Private Lives and Public Surveillance: Social Control in the Computer Age' Schocken Books, 1974
Rule J.B. (1983a) '1984 - The Ingredients of Totalitarianism' in '1984 Revisited - Totalitarianism in Our Century' Harper & Row, 1983 pp.166-179
Rule J.B. (1983b) 'Documentary Identification and Mass Surveillance in the United States' 31 Social Problems 222 (1983)
Rule J.B., McAdam D., Stearns L. & Uglow D. (1980) 'The Politics of Privacy' New American Library, 1980
Smith R.E.(Ed.) (1974-) 'Privacy Journal' monthly since November 1974
Shattuck J. (1984) 'Computer Matching is a Serious Threat to Individual Rights' Comm ACM 27,6 (June 1984) 538-541
SSA (1990) 'Guide for Cost/Benefit Analysis of SSA Computer Matches' Office of the Chief Financial Officer, Office of Program and Integrity Reviews, Social Security Administration, March 1990
SSA (1991a) 'SSA Matching Operations Report: October 1990 - March 1991' Office of Program Integrity and Reviews, Social Security Administration, Pub. No. 31-004, March 1991
SSA (1991b) 'SSA Matching Operations Inventory' Office of Program Integrity and Reviews, Social Security Administration, May 1991
Thom J. & Thorne P. (1983) 'Privacy Legislation and the Right of Access' Austral. Comp. J. 15,4 (November 1983) 145-150
Westin A.F. (1967) 'Privacy and Freedom' Atheneum, 1967
Westin A.F. (ed.) (1971) 'Information Technology in a Democracy' Harvard U.P., 1971
Westin A.F. & Baker M. (1974) 'Databanks in a Free Society' Quadrangle, 1974
| Personalia |
Photographs Presentations Videos |
Access Statistics |
 |
The content and infrastructure for these community service pages are provided by Roger Clarke through his consultancy company, Xamax. From the site's beginnings in August 1994 until February 2009, the infrastructure was provided by the Australian National University. During that time, the site accumulated close to 30 million hits. It passed 65 million in early 2021. Sponsored by the Gallery, Bunhybee Grasslands, the extended Clarke Family, Knights of the Spatchcock and their drummer |
Xamax Consultancy Pty Ltd ACN: 002 360 456 78 Sidaway St, Chapman ACT 2611 AUSTRALIA Tel: +61 2 6288 6916 |
Created: 26 January 1998 - Last Amended: 26 January 1998 by Roger Clarke - Site Last Verified: 15 February 2009
This document is at www.rogerclarke.com/DV/MatchFrame.html
Mail to Webmaster - © Xamax Consultancy Pty Ltd, 1995-2022 - Privacy Policy